Q-Doc: Benchmarking Document Image Quality Assessment Capabilities in Multi-modal Large Language Models
作者: Jiaxi Huang, Dongxu Wu, Hanwei Zhu, Lingyu Zhu, Jun Xing, Xu Wang, Baoliang Chen
分类: cs.CV
发布日期: 2025-11-14
🔗 代码/项目: GITHUB
💡 一句话要点
Q-Doc:评估多模态大语言模型在文档图像质量评估中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 文档图像质量评估 思维链提示 基准测试 失真类型识别
📋 核心要点
- 现有文档图像质量评估方法缺乏对多模态大语言模型(MLLM)能力的系统性评估。
- Q-Doc框架通过粗、中、细三个粒度层级,全面评估MLLM在DIQA任务中的表现。
- 实验表明MLLM在DIQA方面存在局限性,但思维链提示能显著提升其性能。
📝 摘要(中文)
多模态大语言模型(MLLM)的快速发展使其能力超越了高级视觉任务。然而,它们在文档图像质量评估(DIQA)方面的潜力仍未被充分探索。为了弥合这一差距,我们提出了Q-Doc,一个三层评估框架,用于系统地探究MLLM在粗粒度、中粒度和细粒度级别的DIQA能力。a) 在粗粒度级别,我们指示MLLM为文档图像分配质量分数,并分析它们与质量标注的相关性。b) 在中粒度级别,我们设计了失真类型识别任务,包括单选题和多选题测试,用于多重失真场景。c) 在细粒度级别,我们引入了失真严重程度评估,其中MLLM根据人工标注的参考对失真强度进行分类。我们的评估表明,虽然MLLM具有初步的DIQA能力,但它们表现出关键的局限性:不一致的评分、失真误识别和严重程度误判。重要的是,我们表明思维链(CoT)提示显著提高了所有级别的性能。我们的工作为MLLM中的DIQA能力提供了一个基准,揭示了它们在质量感知方面的明显缺陷,并为增强提供了有希望的途径。基准和代码可在以下网址公开获得:https://github.com/cydxf/Q-Doc。
🔬 方法详解
问题定义:论文旨在评估多模态大语言模型(MLLM)在文档图像质量评估(DIQA)方面的能力。现有方法缺乏对MLLM在DIQA任务中表现的系统性分析,无法充分了解其优势与不足。这阻碍了MLLM在文档处理领域的进一步应用。
核心思路:论文的核心思路是构建一个多层次的评估框架,从不同粒度级别对MLLM的DIQA能力进行全面测试。通过设计一系列任务,包括质量评分、失真类型识别和失真严重程度评估,来考察MLLM对文档图像质量的感知和判断能力。同时,探索思维链(CoT)提示对提升MLLM性能的有效性。
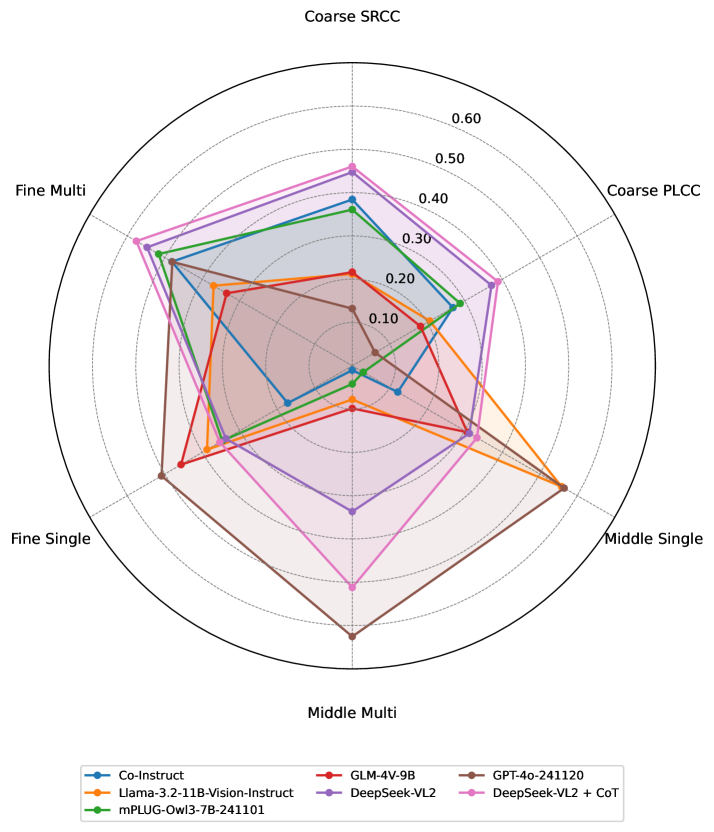
技术框架:Q-Doc框架包含三个主要层级:1) 粗粒度评估:MLLM被要求为文档图像分配质量分数,并分析这些分数与人工标注的相关性。2) 中粒度评估:设计失真类型识别任务,包括单选题和多选题,以评估MLLM识别不同类型失真的能力。3) 细粒度评估:引入失真严重程度评估,MLLM需要根据人工标注的参考,对失真强度进行分类。整个框架旨在从不同维度考察MLLM的DIQA能力。
关键创新:该论文的关键创新在于提出了一个系统性的、多层次的评估框架Q-Doc,专门用于评估MLLM在文档图像质量评估方面的能力。与以往研究不同,Q-Doc不仅关注整体质量评分,还深入到失真类型识别和严重程度评估,从而更全面地了解MLLM的DIQA能力。此外,论文还探索了思维链提示在提升MLLM性能方面的作用,为未来的研究提供了新的方向。
关键设计:在粗粒度评估中,使用Spearman相关系数来衡量MLLM评分与人工标注之间的相关性。在中粒度评估中,设计了单选题和多选题,以评估MLLM识别不同类型失真的准确率。在细粒度评估中,采用了分类任务,使用交叉熵损失函数来训练MLLM对失真严重程度进行分类。思维链提示通过引导MLLM逐步推理,来提升其在各个层级的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,虽然MLLM在DIQA方面具有初步能力,但在评分一致性、失真识别和严重程度判断方面存在明显不足。然而,思维链(CoT)提示能够显著提升MLLM在所有评估层级的性能。例如,在失真类型识别任务中,CoT提示可以将准确率提升10%-20%。
🎯 应用场景
该研究成果可应用于文档图像处理、信息提取、自动化办公等领域。通过提升MLLM的文档图像质量评估能力,可以提高文档识别的准确率,减少人工干预,从而提高工作效率。未来,该研究可以进一步扩展到更复杂的文档场景,例如手写文档、表格文档等。
📄 摘要(原文)
The rapid advancement of Multi-modal Large Language Models (MLLMs) has expanded their capabilities beyond high-level vision tasks. Nevertheless, their potential for Document Image Quality Assessment (DIQA) remains underexplored. To bridge this gap, we propose Q-Doc, a three-tiered evaluation framework for systematically probing DIQA capabilities of MLLMs at coarse, middle, and fine granularity levels. a) At the coarse level, we instruct MLLMs to assign quality scores to document images and analyze their correlation with Quality Annotations. b) At the middle level, we design distortion-type identification tasks, including single-choice and multi-choice tests for multi-distortion scenarios. c) At the fine level, we introduce distortion-severity assessment where MLLMs classify distortion intensity against human-annotated references. Our evaluation demonstrates that while MLLMs possess nascent DIQA abilities, they exhibit critical limitations: inconsistent scoring, distortion misidentification, and severity misjudgment. Significantly, we show that Chain-of-Thought (CoT) prompting substantially enhances performance across all levels. Our work provides a benchmark for DIQA capabilities in MLLMs, revealing pronounced deficiencies in their quality perception and promising pathways for enhancement. The benchmark and code are publicly available at: https://github.com/cydxf/Q-Doc.