MicroVQA++: High-Quality Microscopy Reasoning Dataset with Weakly Supervised Graphs for Multimodal Large Language Model
作者: Manyu Li, Ruian He, Chenxi Ma, Weimin Tan, Bo Yan
分类: cs.CV
发布日期: 2025-11-14
备注: 11 pages, 4 figures
💡 一句话要点
提出MicroVQA++:一个高质量显微镜推理数据集,利用弱监督图进行多模态大语言模型训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 显微镜图像 视觉问答 多模态学习 大语言模型 弱监督学习 图神经网络 生物医学图像分析
📋 核心要点
- 现有显微镜图像推理方法受限于缺乏大规模、高质量的标注数据,阻碍了多模态大语言模型在该领域的应用。
- 论文提出MicroVQA++数据集,通过三阶段流程,结合专家知识、图结构过滤和人工筛选,保证数据质量和规模。
- 实验表明,基于MicroVQA++训练的4B规模MLLM在显微镜推理任务上达到与GPT-5相当的水平,并在开源模型中取得SOTA。
📝 摘要(中文)
多模态大语言模型越来越多地应用于生物医学成像,但由于缺乏大规模、高质量的训练数据,显微镜科学推理仍然受到限制。我们推出了MicroVQA++,这是一个三阶段、大规模、高质量的显微镜VQA语料库,来源于BIOMEDICA档案。第一阶段从同行评审文章中提取专家验证的图-标题对,引导监督学习。第二阶段应用HiCQA-Graph,这是一个新颖的异构图,它融合了基于NLI的文本蕴含、基于CLIP的视觉-语言对齐和agent信号,以识别和过滤不一致的样本。第三阶段使用多模态大语言模型(MLLM)agent生成多项选择题(MCQ),然后进行人工筛选。最终发布包含一个大型训练集和一个人工检查的测试集,其Bloom难度级别硬样本分布超过了MicroVQA基准。我们的工作提供了(i)一个质量控制的数据集,将专家文献与基于图的过滤和人工改进相结合;(ii)HiCQA-Graph,第一个联合建模(图像、标题、QA)以进行跨模态一致性过滤的图;(iii)证据表明,精心构建的数据使4B规模的MLLM能够达到具有竞争力的显微镜推理性能(例如GPT-5),并在开源MLLM中实现最先进的性能。代码和数据集将在审查过程结束后发布。
🔬 方法详解
问题定义:论文旨在解决显微镜图像视觉问答(VQA)领域缺乏高质量、大规模数据集的问题。现有方法依赖于人工标注,成本高昂且难以覆盖复杂的科学推理场景。因此,需要一种能够自动生成并筛选高质量显微镜VQA数据的方案。
核心思路:论文的核心思路是利用弱监督学习和图神经网络,结合专家知识、视觉-语言对齐和文本蕴含关系,自动构建和过滤显微镜VQA数据。通过多阶段流程,逐步提升数据集的质量和规模。
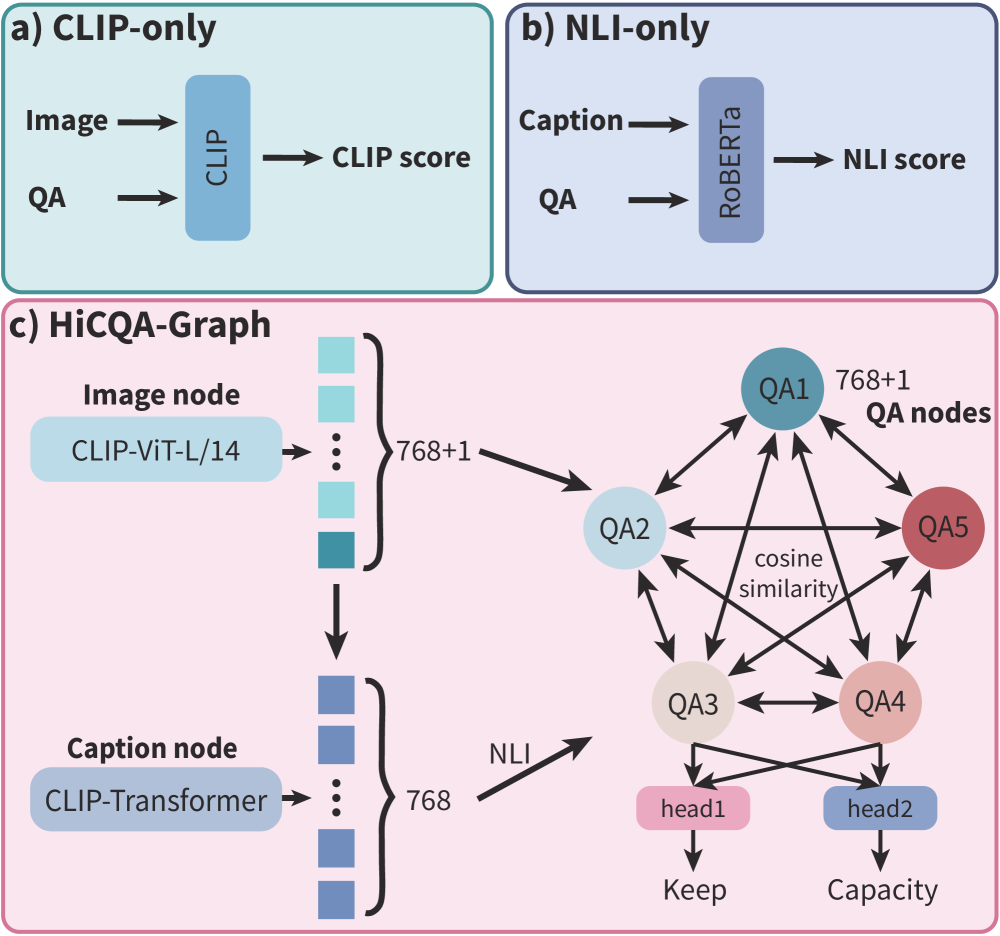
技术框架:MicroVQA++的构建分为三个阶段: 1. Bootstrapping Supervision: 从BIOMEDICA档案中提取专家验证的图-标题对,作为初始监督信号。 2. HiCQA-Graph Filtering: 构建异构图HiCQA-Graph,节点包括图像、标题和QA对。利用NLI、CLIP和agent信号,对图中的不一致样本进行过滤。 3. MLLM-based Question Generation: 使用多模态大语言模型生成多项选择题,并进行人工筛选,进一步提升数据质量。
关键创新:论文的关键创新在于HiCQA-Graph,这是一个联合建模图像、标题和QA对的异构图,用于跨模态一致性过滤。该图结构能够有效地捕捉视觉、语言和推理之间的关系,从而识别和过滤不一致的样本。这是首次尝试将图神经网络应用于显微镜VQA数据的质量控制。
关键设计:HiCQA-Graph的关键设计包括: * 节点类型: 图像、标题、QA对。 * 边类型: 基于NLI的文本蕴含关系、基于CLIP的视觉-语言对齐关系、agent信号。 * 过滤策略: 基于图结构,识别并移除不一致的节点和边。具体参数设置和损失函数细节未知,需要在论文发布后进一步分析。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于MicroVQA++训练的4B规模MLLM在显微镜推理任务上取得了显著的性能提升,达到与GPT-5相当的水平,并在开源MLLM中实现了SOTA。该数据集的Bloom难度级别硬样本分布超过了MicroVQA基准,表明其具有更高的难度和挑战性。
🎯 应用场景
MicroVQA++数据集可广泛应用于生物医学图像分析、疾病诊断、药物研发等领域。通过训练多模态大语言模型,可以实现对显微镜图像的自动理解和推理,辅助科研人员进行科学发现,提高生物医学研究的效率和准确性。未来,该数据集有望推动人工智能在生物医学领域的更广泛应用。
📄 摘要(原文)
Multimodal Large Language Models are increasingly applied to biomedical imaging, yet scientific reasoning for microscopy remains limited by the scarcity of large-scale, high-quality training data. We introduce MicroVQA++, a three-stage, large-scale and high-quality microscopy VQA corpus derived from the BIOMEDICA archive. Stage one bootstraps supervision from expert-validated figure-caption pairs sourced from peer-reviewed articles. Stage two applies HiCQA-Graph, a novel heterogeneous graph over images, captions, and QAs that fuses NLI-based textual entailment, CLIP-based vision-language alignment, and agent signals to identify and filter inconsistent samples. Stage three uses a MultiModal Large Language Model (MLLM) agent to generate multiple-choice questions (MCQ) followed by human screening. The resulting release comprises a large training split and a human-checked test split whose Bloom's level hard-sample distribution exceeds the MicroVQA benchmark. Our work delivers (i) a quality-controlled dataset that couples expert literature with graph-based filtering and human refinement; (ii) HiCQA-Graph, the first graph that jointly models (image, caption, QA) for cross-modal consistency filtering; (iii) evidence that careful data construction enables 4B-scale MLLMs to reach competitive microscopy reasoning performance (e.g., GPT-5) and achieve state-of-the-art performance among open-source MLLMs. Code and dataset will be released after the review process concludes.