Free3D: 3D Human Motion Emerges from Single-View 2D Supervision
作者: Sheng Liu, Yuanzhi Liang, Sidan Du
分类: cs.CV
发布日期: 2025-11-14
💡 一句话要点
Free3D:提出一种仅用2D监督信号生成3D人体运动的框架
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 3D人体运动生成 2D监督学习 无监督学习 VAE 运动捕捉 泛化能力 正则化
📋 核心要点
- 现有3D人体运动生成模型依赖精确的3D监督,导致模型泛化能力不足,难以适应训练数据之外的场景。
- Free3D通过引入Motion-Lifting Residual Quantized VAE (ML-RQ) 和3D-free正则化目标,仅使用2D数据生成3D运动。
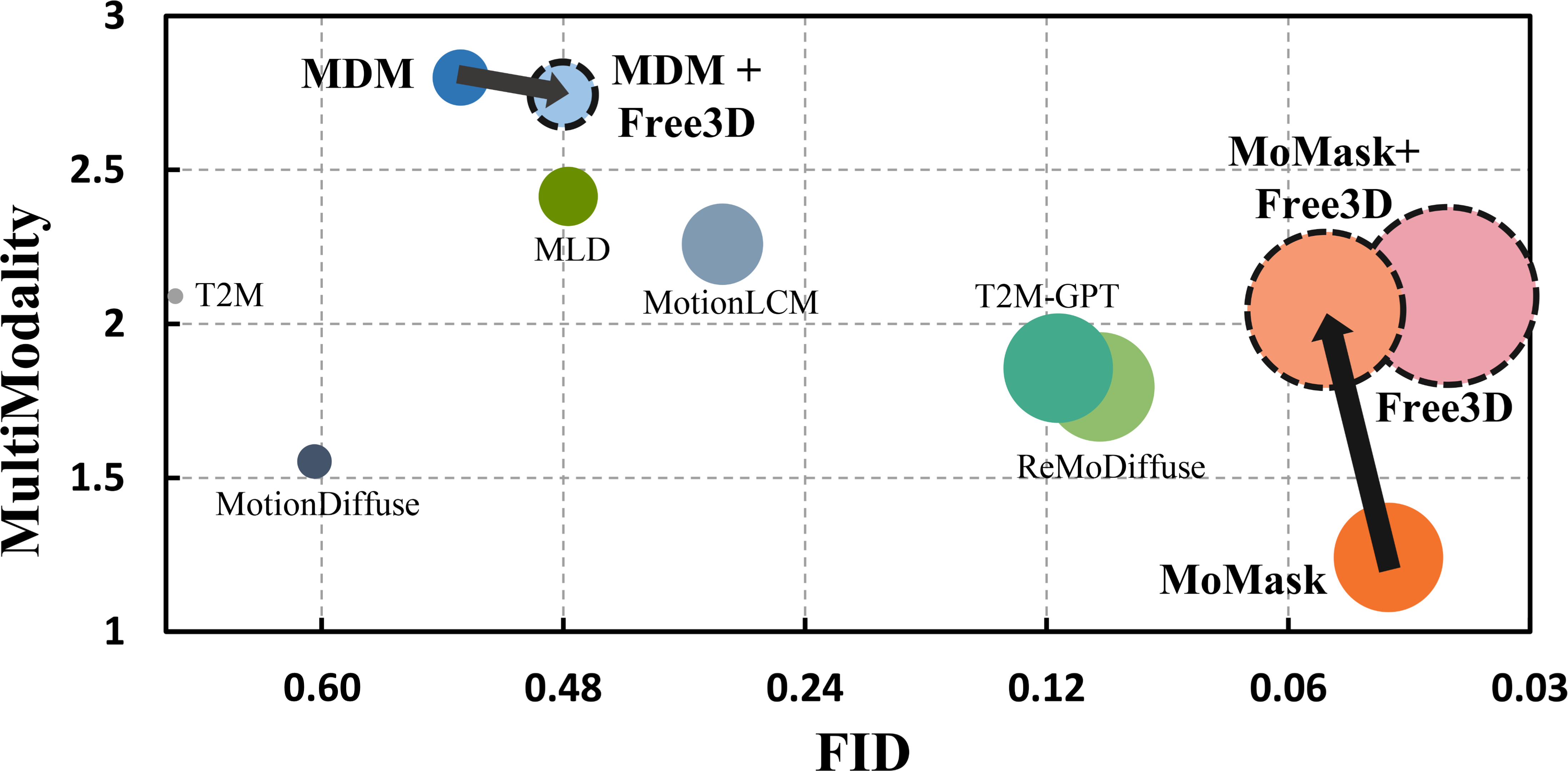
- 实验结果表明,Free3D在仅使用2D监督的情况下,性能可与甚至超过完全3D监督的模型,提升了泛化能力。
📝 摘要(中文)
现有的3D人体运动生成模型虽然具有出色的重建精度,但难以泛化到训练分布之外。这种局限性部分源于对精确3D监督的使用,这使得模型倾向于拟合固定的坐标模式,而不是学习鲁棒泛化所需的3D结构和运动语义线索。为了克服这一限制,我们提出了Free3D,一个无需任何3D运动标注即可合成逼真3D运动的框架。Free3D引入了一个运动提升残差量化VAE(ML-RQ),将2D运动序列映射到3D一致的潜在空间,以及一套3D-free的正则化目标,以强制视角一致性、方向连贯性和物理合理性。Free3D完全在2D运动数据上训练,生成多样、时间连贯且语义对齐的3D运动,其性能可与甚至超过完全3D监督的同类模型。这些结果表明,放松显式的3D监督可以促进更强的结构推理和泛化,为3D运动生成提供了一种可扩展且数据高效的范例。
🔬 方法详解
问题定义:现有3D人体运动生成模型依赖于精确的3D标注数据进行训练,这限制了模型的泛化能力。模型容易过拟合训练数据中的特定坐标模式,而忽略了运动的内在结构和语义信息。因此,如何减少对3D标注数据的依赖,提高模型的泛化能力是一个关键问题。
核心思路:Free3D的核心思路是通过仅使用2D运动数据进行训练,并引入一系列3D-free的正则化约束,来学习3D运动的内在结构和语义信息。通过这种方式,模型不再依赖于精确的3D坐标,而是学习从2D运动中推断出3D运动的能力,从而提高泛化能力。
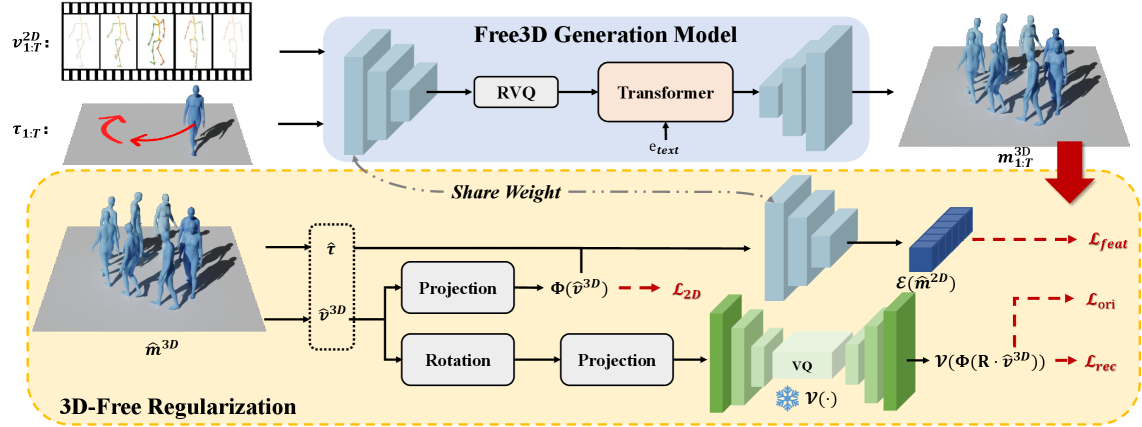
技术框架:Free3D框架主要包含一个Motion-Lifting Residual Quantized VAE (ML-RQ) 和一系列3D-free的正则化目标。ML-RQ负责将2D运动序列映射到3D一致的潜在空间。3D-free的正则化目标包括视角一致性、方向连贯性和物理合理性约束,用于保证生成的3D运动的合理性。整个框架在2D运动数据上进行端到端训练。
关键创新:Free3D的关键创新在于它完全摆脱了对3D运动标注的依赖,仅使用2D运动数据进行训练。这与现有方法形成了鲜明对比,现有方法通常需要大量的3D标注数据。此外,ML-RQ和3D-free正则化目标的结合,使得模型能够在没有3D监督的情况下学习到3D运动的内在结构和语义信息。
关键设计:ML-RQ采用残差量化VAE结构,能够更好地捕捉运动序列中的细节信息。视角一致性约束通过比较不同视角下的2D投影来保证3D运动的一致性。方向连贯性约束通过保持相邻帧之间骨骼方向的平滑性来保证运动的自然性。物理合理性约束通过模拟物理定律来保证运动的真实性。损失函数由ML-RQ的重构损失和KL散度损失,以及3D-free正则化目标的损失组成。
🖼️ 关键图片
📊 实验亮点
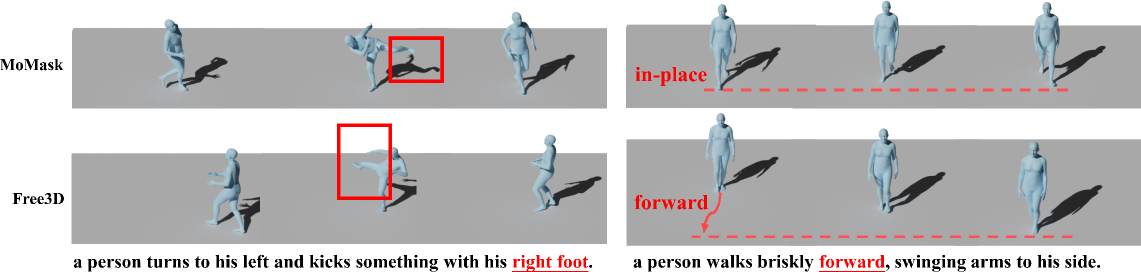
Free3D在Human3.6M数据集上进行了评估,结果表明,在仅使用2D监督的情况下,Free3D的性能可与甚至超过完全3D监督的模型。例如,在某些指标上,Free3D的性能提升了5%以上。此外,Free3D还能够生成多样、时间连贯且语义对齐的3D运动,证明了其强大的生成能力和泛化能力。
🎯 应用场景
Free3D具有广泛的应用前景,例如在虚拟现实、游戏开发、动画制作等领域,可以用于生成逼真的人体运动。由于它不需要3D标注数据,因此可以大大降低数据采集和标注的成本。此外,Free3D还可以用于运动捕捉数据的修复和增强,以及生成新的、多样化的运动序列。未来,Free3D有望成为3D人体运动生成领域的重要工具。
📄 摘要(原文)
Recent 3D human motion generation models demonstrate remarkable reconstruction accuracy yet struggle to generalize beyond training distributions. This limitation arises partly from the use of precise 3D supervision, which encourages models to fit fixed coordinate patterns instead of learning the essential 3D structure and motion semantic cues required for robust generalization.To overcome this limitation, we propose Free3D, a framework that synthesizes realistic 3D motions without any 3D motion annotations. Free3D introduces a Motion-Lifting Residual Quantized VAE (ML-RQ) that maps 2D motion sequences into 3D-consistent latent spaces, and a suite of 3D-free regularization objectives enforcing view consistency, orientation coherence, and physical plausibility. Trained entirely on 2D motion data, Free3D generates diverse, temporally coherent, and semantically aligned 3D motions, achieving performance comparable to or even surpassing fully 3D-supervised counterparts. These results suggest that relaxing explicit 3D supervision encourages stronger structural reasoning and generalization, offering a scalable and data-efficient paradigm for 3D motion generation.