AUVIC: Adversarial Unlearning of Visual Concepts for Multi-modal Large Language Models
作者: Haokun Chen, Jianing Li, Yao Zhang, Jinhe Bi, Yan Xia, Jindong Gu, Volker Tresp
分类: cs.CV, cs.AI
发布日期: 2025-11-14
备注: AAAI 2026. Code: https://github.com/HaokunChen245/AUVIC
💡 一句话要点
AUVIC:面向多模态大语言模型的视觉概念对抗性遗忘框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉概念遗忘 对抗学习 数据隐私 机器遗忘
📋 核心要点
- 现有MLLM视觉概念遗忘方法缺乏精确性,难以在删除目标概念的同时保持模型在相关概念上的性能。
- AUVIC通过引入对抗性扰动,精确地隔离并遗忘目标视觉概念,避免对相似概念产生副作用。
- VCUBench基准测试表明,AUVIC在实现高目标遗忘率的同时,对非目标概念的性能影响很小,优于现有方法。
📝 摘要(中文)
多模态大语言模型(MLLMs)在海量数据集上优化后表现出色。然而,这些数据集通常包含敏感或受版权保护的内容,引发了严重的数据隐私问题。强制执行“被遗忘权”的监管框架推动了机器遗忘的需求。这种技术允许删除目标数据,而无需耗费资源的重新训练。虽然文本遗忘已得到充分研究,但MLLM中的视觉概念遗忘仍未被充分探索。一个主要的挑战是在不破坏模型在相关实体上的性能的情况下,精确地删除目标视觉概念。为了解决这个问题,我们引入了AUVIC,这是一个用于MLLM的新型视觉概念遗忘框架。AUVIC应用对抗性扰动来实现精确遗忘。这种方法有效地隔离了目标概念,同时避免了对类似实体的意外影响。为了评估我们的方法,我们构建了VCUBench。它是第一个旨在评估群体环境中视觉概念遗忘的基准。实验结果表明,AUVIC实现了最先进的目标遗忘率,同时对非目标概念造成的性能下降最小。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型中视觉概念的精确遗忘问题。现有方法在尝试删除特定视觉概念时,容易对模型在相关或相似概念上的性能产生负面影响,导致模型泛化能力下降。这种“误伤”问题是视觉概念遗忘的主要痛点。
核心思路:AUVIC的核心思路是利用对抗性学习,通过对输入图像施加精心设计的对抗性扰动,使得模型在目标视觉概念上产生错误的预测,从而实现对该概念的“遗忘”。这种方法旨在精确地针对目标概念,避免对其他相关概念产生干扰。
技术框架:AUVIC框架主要包含以下几个关键模块:1) 对抗样本生成器:负责生成针对目标视觉概念的对抗样本。2) 多模态大语言模型:作为需要进行概念遗忘的目标模型。3) 损失函数:用于指导对抗样本生成器生成有效的对抗扰动,以最大化模型在目标概念上的预测误差。整个流程是,首先选定需要遗忘的视觉概念,然后对抗样本生成器生成针对该概念的对抗样本,这些对抗样本被输入到多模态大语言模型中,通过优化损失函数,使得模型逐渐“遗忘”目标概念。
关键创新:AUVIC的关键创新在于其对抗性遗忘策略,它通过对抗扰动实现了对目标视觉概念的精确打击,避免了传统方法中常见的“误伤”问题。此外,VCUBench基准测试的提出,为视觉概念遗忘的研究提供了一个标准化的评估平台。
关键设计:AUVIC的关键设计包括:1) 对抗扰动的生成方式:论文可能采用了特定的对抗攻击算法(例如PGD、FGSM等)来生成对抗扰动。2) 损失函数的设计:损失函数需要能够有效地引导模型在目标概念上产生错误的预测,同时避免对其他概念产生负面影响。这可能涉及到一些正则化项的设计。3) 对抗样本的注入策略:如何将对抗样本有效地注入到模型的训练或微调过程中,以实现最佳的遗忘效果。
🖼️ 关键图片


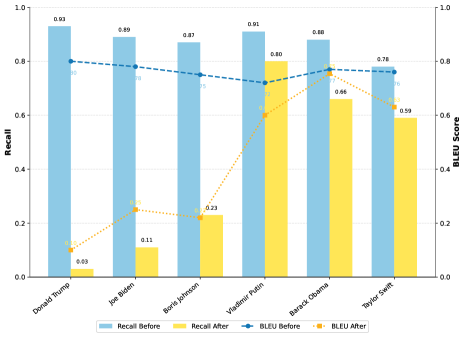
📊 实验亮点
AUVIC在VCUBench基准测试上取得了显著的成果,实现了最先进的目标遗忘率,同时对非目标概念的性能影响最小。具体而言,AUVIC在目标概念遗忘率上超过了现有基线方法,并且在保持模型在相关概念上的准确性方面表现出色。这些实验结果验证了AUVIC在视觉概念遗忘方面的有效性和精确性。
🎯 应用场景
AUVIC技术可应用于保护用户隐私、遵守数据法规(如GDPR中的“被遗忘权”),以及移除模型中的有害或不当内容。例如,可以用于从图像识别系统中移除敏感人脸信息,或从多模态模型中删除包含版权信息的视觉概念,从而降低法律风险并提升模型的可信度。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) achieve impressive performance once optimized on massive datasets. Such datasets often contain sensitive or copyrighted content, raising significant data privacy concerns. Regulatory frameworks mandating the 'right to be forgotten' drive the need for machine unlearning. This technique allows for the removal of target data without resource-consuming retraining. However, while well-studied for text, visual concept unlearning in MLLMs remains underexplored. A primary challenge is precisely removing a target visual concept without disrupting model performance on related entities. To address this, we introduce AUVIC, a novel visual concept unlearning framework for MLLMs. AUVIC applies adversarial perturbations to enable precise forgetting. This approach effectively isolates the target concept while avoiding unintended effects on similar entities. To evaluate our method, we construct VCUBench. It is the first benchmark designed to assess visual concept unlearning in group contexts. Experimental results demonstrate that AUVIC achieves state-of-the-art target forgetting rates while incurs minimal performance degradation on non-target concepts.