Beyond Flatlands: Unlocking Spatial Intelligence by Decoupling 3D Reasoning from Numerical Regression
作者: Zhongbin Guo, Jiahe Liu, Yushan Li, Wenyu Gao, Zhen Yang, Chenzhi Li, Xinyue Zhang, Ping Jian
分类: cs.CV
发布日期: 2025-11-14 (更新: 2025-11-18)
💡 一句话要点
GEODE:解耦3D推理与数值回归,提升视觉语言模型空间智能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 3D空间推理 解耦架构 数值回归 思维链 几何感知 直接回归
📋 核心要点
- 现有VLM难以理解3D空间,原因是几何信息处理与2D特征提取的冲突,以及离散tokenizer无法生成连续数值。
- GEODE通过解耦3D推理和数值回归,利用解耦推理模块(DRM)和直接回归头(DRH)来解决上述瓶颈。
- 实验表明,GEODE仅用15亿参数就达到了与70亿+参数模型相当的空间推理性能,显著提升了效率。
📝 摘要(中文)
现有的视觉语言模型(VLMs)在架构上根植于“平面”感知,难以理解真实世界的3D空间智能。这种不足源于双重瓶颈:输入阶段,计算量巨大的几何感知编码器与肤浅的2D特征之间存在冲突;输出阶段,离散的tokenizer在结构上无法产生精确、连续的数值。为了打破这种僵局,我们提出了GEODE(几何输出和解耦输入引擎),一种通过解耦3D推理与数值生成来解决双重瓶颈的新型架构。GEODE通过两个专门的、即插即用的模块来增强主VLM:解耦推理模块(DRM),作为空间协处理器,通过交叉注意力将显式3D数据与2D视觉特征对齐,并将空间思维链(CoT)逻辑提炼为可注入的推理Token;直接回归头(DRH),一种“嵌入即值”范式,将专门的控制Token路由到轻量级MLP,用于精确、连续的标量和3D边界框回归。这些模块的协同作用使我们15亿参数的模型能够作为高级语义调度器,实现与70亿+模型相媲美的最先进的空间推理性能。
🔬 方法详解
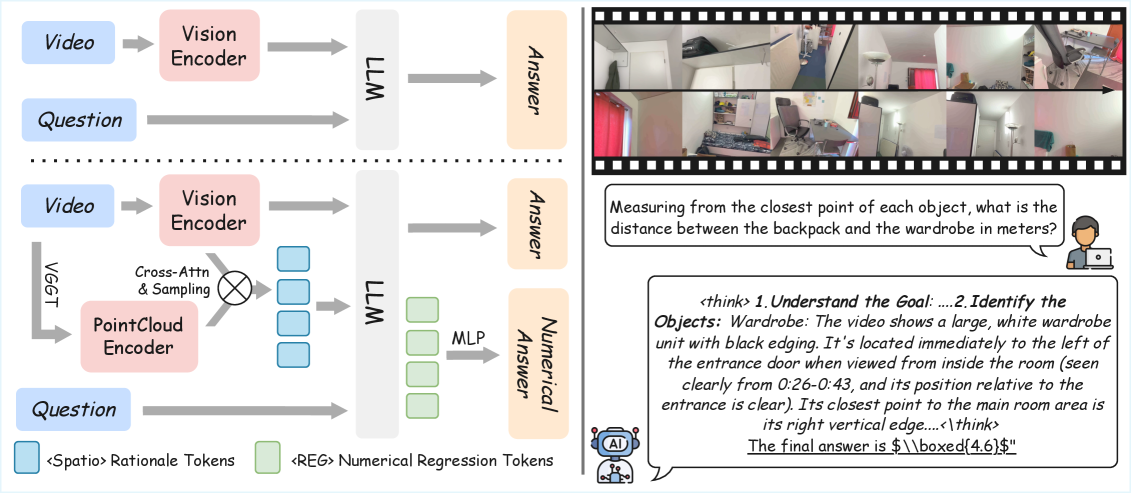
问题定义:现有视觉语言模型(VLMs)在理解3D空间信息时面临挑战。主要痛点在于,一方面,几何感知编码器计算量大,与简单的2D视觉特征融合困难;另一方面,模型输出通常依赖离散的tokenizer,难以生成精确的连续数值,例如3D bounding box的坐标。
核心思路:GEODE的核心思路是将3D空间推理与最终的数值回归解耦。通过引入专门的模块处理3D信息,并使用直接回归的方式生成数值,避免了传统VLM的瓶颈。这样设计的原因在于,3D空间理解和数值生成是两个不同的任务,应该分别优化。
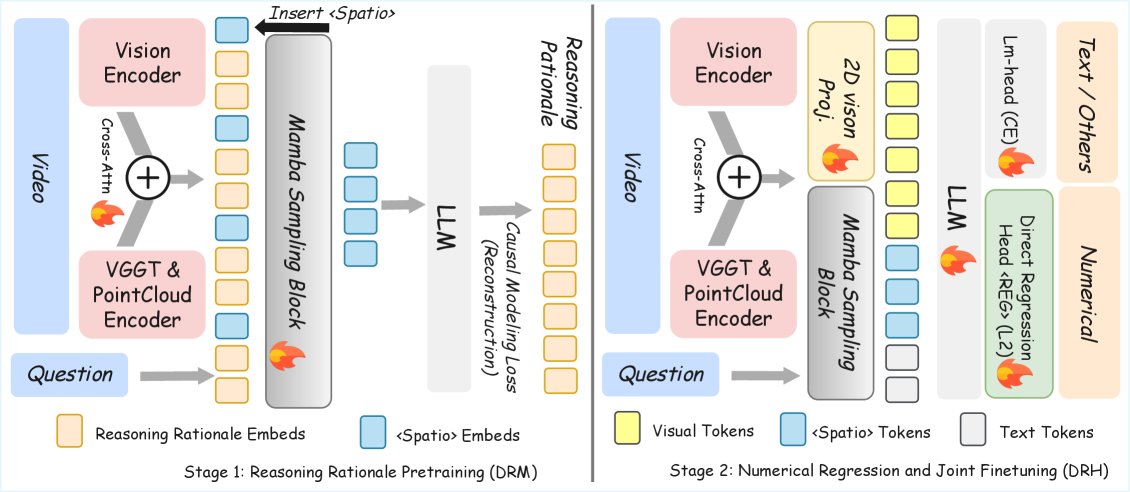
技术框架:GEODE的整体架构是在现有VLM的基础上,添加两个即插即用的模块:解耦推理模块(DRM)和直接回归头(DRH)。DRM负责处理3D空间信息,并将推理过程转化为可注入的Rationale Token。DRH则负责接收这些Token,并直接回归出连续的数值结果。整个流程可以看作是VLM负责高层语义理解,DRM和DRH负责空间推理和数值生成。
关键创新:GEODE的关键创新在于解耦的架构设计。DRM将3D空间信息与2D视觉特征对齐,并通过空间思维链(CoT)进行推理。DRH采用“嵌入即值”的范式,直接将Token嵌入映射为数值,避免了离散tokenizer的限制。这种解耦设计使得模型能够更有效地利用3D信息,并生成精确的数值结果。
关键设计:DRM使用交叉注意力机制将3D数据与2D视觉特征对齐。DRH使用轻量级的MLP进行数值回归,并引入专门的控制Token来控制回归过程。损失函数方面,可能使用了回归损失(如L1或L2损失)来优化数值预测的准确性。具体的网络结构和参数设置在论文中应该有更详细的描述。
🖼️ 关键图片
📊 实验亮点
GEODE在空间推理任务上取得了显著的性能提升。实验结果表明,GEODE仅使用15亿参数,就达到了与70亿+参数模型相媲美的性能。这表明GEODE的解耦架构能够更有效地利用模型参数,并提高空间推理的效率。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
GEODE具有广泛的应用前景,例如机器人导航、自动驾驶、增强现实等领域。它可以帮助机器人更好地理解周围环境,并进行精确的空间推理和定位。在自动驾驶领域,GEODE可以用于识别和定位车辆、行人等目标,提高驾驶安全性。在增强现实领域,GEODE可以用于将虚拟物体与真实场景进行精确对齐,提升用户体验。该研究的未来影响在于,它为视觉语言模型在3D空间理解方面的发展提供了一种新的思路。
📄 摘要(原文)
Existing Vision Language Models (VLMs) architecturally rooted in "flatland" perception, fundamentally struggle to comprehend real-world 3D spatial intelligence. This failure stems from a dual-bottleneck: input-stage conflict between computationally exorbitant geometric-aware encoders and superficial 2D-only features, and output-stage misalignment where discrete tokenizers are structurally incapable of producing precise, continuous numerical values. To break this impasse, we introduce GEODE (Geometric-Output and Decoupled-Input Engine), a novel architecture that resolves this dual-bottleneck by decoupling 3D reasoning from numerical generation. GEODE augments main VLM with two specialized, plug-and-play modules: Decoupled Rationale Module (DRM) that acts as spatial co-processor, aligning explicit 3D data with 2D visual features via cross-attention and distilling spatial Chain-of-Thought (CoT) logic into injectable Rationale Tokens; and Direct Regression Head (DRH), an "Embedding-as-Value" paradigm which routes specialized control tokens to a lightweight MLP for precise, continuous regression of scalars and 3D bounding boxes. The synergy of these modules allows our 1.5B parameter model to function as a high-level semantic dispatcher, achieving state-of-the-art spatial reasoning performance that rivals 7B+ models.