Positional Bias in Multimodal Embedding Models: Do They Favor the Beginning, the Middle, or the End?
作者: Kebin Wu, Fatima Albreiki
分类: cs.CV
发布日期: 2025-11-14
备注: accepted to AAAI 2026 main track
💡 一句话要点
揭示多模态嵌入模型中的位置偏差:文本偏向起始,图像偏向两端
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 位置偏差 图像-文本检索 表征学习 模型鲁棒性
📋 核心要点
- 现有研究对表征模型,特别是多模态模型中的位置偏差关注不足,这会影响模型性能。
- 该研究通过区分上下文重要性和位置偏差,分析了多模态模型中不同模态的位置偏差。
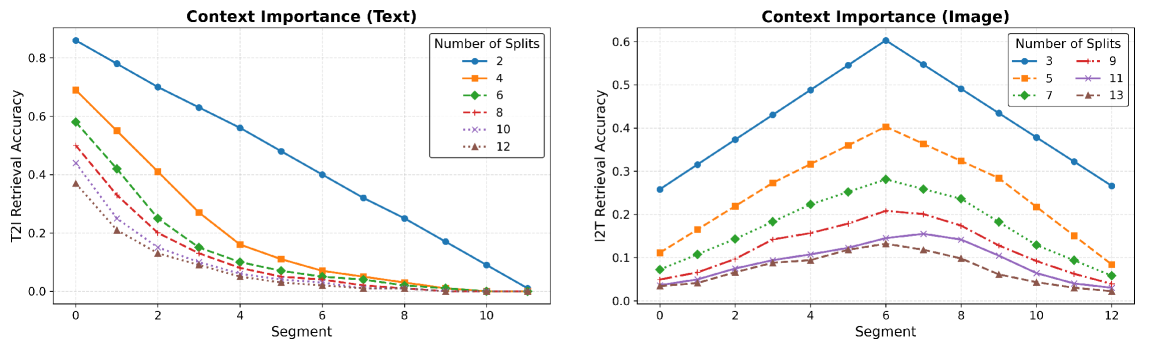
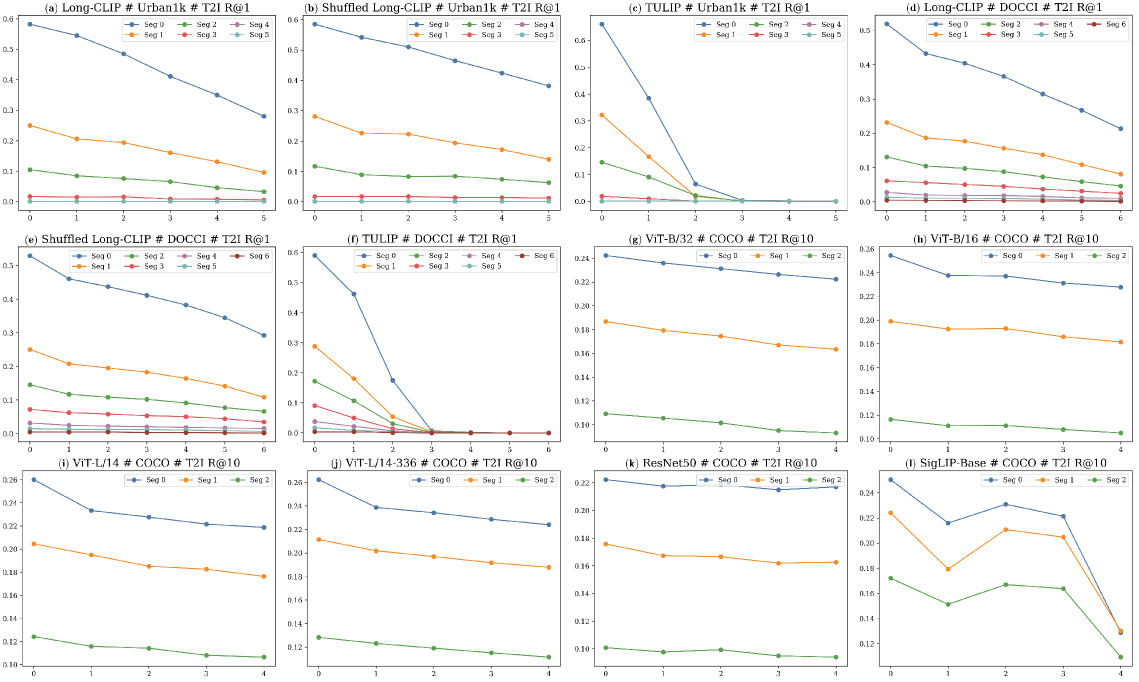
- 实验发现文本编码器偏向输入开头,图像编码器偏向开头和结尾,并探究了偏差的来源。
📝 摘要(中文)
本文研究了多模态表征模型中的位置偏差,即模型过度强调某些位置而忽略内容的情况。尽管位置偏差在文本生成模型中已被广泛研究,但在表征模型中,尤其是在多模态模型中的存在和影响仍未得到充分探索。本文在图像-文本检索的背景下,区分了上下文重要性和位置偏差,并评估了不同模型和数据集中的位置偏差。实验表明,位置偏差在多模态模型中普遍存在,但在不同模态中表现不同:文本编码器倾向于偏向输入的开头,而图像编码器则在开头和结尾都表现出偏差。这种偏差源于或被多种因素放大,包括位置编码方案、训练损失、上下文重要性以及多模态训练中使用图像-文本对的性质。
🔬 方法详解
问题定义:论文旨在解决多模态嵌入模型中位置偏差的问题。现有方法在处理多模态数据时,容易受到输入序列中不同位置的影响,导致模型对某些位置的信息过度关注,而忽略了其他位置的信息,从而影响模型的表征能力和检索性能。现有方法没有充分考虑这种位置偏差,导致模型性能下降。
核心思路:论文的核心思路是区分上下文重要性和位置偏差,并设计实验来评估不同模型和数据集中的位置偏差。通过分析不同模态(文本和图像)的位置偏差模式,揭示了位置偏差的来源和影响因素。这种分析有助于更好地理解多模态模型的行为,并为设计更鲁棒的模型提供指导。
技术框架:论文的技术框架主要包括以下几个步骤:1) 定义位置偏差和上下文重要性;2) 选择不同的多模态模型和数据集;3) 设计实验来评估不同模型和数据集中的位置偏差;4) 分析实验结果,揭示位置偏差的模式和来源。具体来说,论文可能使用了特定的探针任务或注意力机制分析方法来量化不同位置对模型输出的影响。
关键创新:论文的关键创新在于首次系统地研究了多模态嵌入模型中的位置偏差。之前的研究主要集中在文本生成模型中的位置偏差,而忽略了多模态模型中的情况。论文通过实验证明,位置偏差在多模态模型中普遍存在,并且在不同模态中表现出不同的模式。此外,论文还探讨了位置偏差的来源和影响因素,为未来的研究提供了新的方向。
关键设计:论文的关键设计可能包括:1) 选择具有代表性的多模态模型,如CLIP等;2) 设计合适的实验来量化位置偏差,例如通过masking或扰动输入序列的不同位置;3) 使用特定的指标来评估模型对不同位置的敏感度;4) 分析不同位置编码方案对位置偏差的影响;5) 考察不同的训练损失函数是否会加剧位置偏差。
🖼️ 关键图片

📊 实验亮点
实验结果表明,文本编码器倾向于偏向输入的开头,而图像编码器则在开头和结尾都表现出偏差。这种偏差受到位置编码方案、训练损失、上下文重要性以及多模态训练方式的影响。具体性能提升数据未知,但研究揭示了多模态模型中位置偏差的普遍性和差异性。
🎯 应用场景
该研究成果可应用于提升图像-文本检索、视频理解、跨模态信息融合等任务的性能。通过减轻位置偏差,可以提高模型对输入信息的理解能力,从而改善下游任务的效果。未来的研究可以基于此,设计更鲁棒的多模态模型,并探索缓解位置偏差的有效方法。
📄 摘要(原文)
Positional bias - where models overemphasize certain positions regardless of content - has been shown to negatively impact model performance across various tasks. While recent research has extensively examined positional bias in text generation models, its presence and effects in representation models remain underexplored. Even less is known about such biases in multimodal models. In this work, we investigate positional bias in multimodal representation models, specifically in the context of image-text retrieval. We begin by distinguishing between context importance and positional bias, and then assess the presence and extent of positional bias across different models and datasets. Our experiments demonstrate that positional bias is prevalent in multimodal models, but manifests differently across modalities: text encoders tend to exhibit bias toward the beginning of the input, whereas image encoders show bias at both the beginning and end. Furthermore, we find that this bias arises from, or is amplified by, a combination of factors, including the positional encoding scheme, training loss, context importance, and the nature of using image-text pairs in multimodal training.