VIDEOP2R: Video Understanding from Perception to Reasoning
作者: Yifan Jiang, Yueying Wang, Rui Zhao, Toufiq Parag, Zhimin Chen, Zhenyu Liao, Jayakrishnan Unnikrishnan
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-11-14
💡 一句话要点
VideoP2R:通过感知与推理建模,提升视频理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 强化微调 流程感知 思维链 大型语言模型
📋 核心要点
- 大型视频语言模型(LVLMs)的推理能力提升面临挑战,现有强化微调方法难以有效应用。
- VideoP2R将视频理解分解为感知和推理两个过程,并分别进行优化,提升模型性能。
- 实验结果表明,VideoP2R在多个视频理解基准上达到SOTA,验证了流程感知建模的有效性。
📝 摘要(中文)
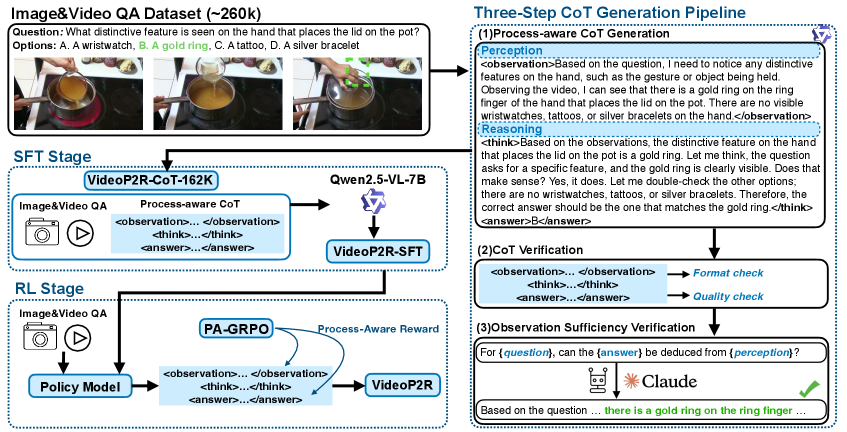
本文提出了一种新颖的流程感知视频强化微调框架VideoP2R,旨在通过将感知和推理建模为不同的过程来增强视频推理能力。在监督微调(SFT)阶段,我们开发了一个三步流程,生成了高质量的、流程感知的思维链(CoT)数据集VideoP2R-CoT-162K,用于感知和推理。在强化学习(RL)阶段,我们引入了一种新颖的流程感知分组相对策略优化(PA-GRPO)算法,为感知和推理提供单独的奖励。大量实验表明,VideoP2R在七个视频推理和理解基准测试中的六个上实现了最先进(SotA)的性能。消融研究进一步证实了我们的流程感知建模和PA-GRPO的有效性,并证明了模型的感知输出对于下游推理具有足够的信息。
🔬 方法详解
问题定义:现有的大型视频语言模型(LVLMs)在进行复杂视频推理时,难以有效利用强化微调(RFT)框架提升性能。传统的RFT方法通常将整个过程视为一个整体进行优化,忽略了视频理解中感知和推理这两个关键步骤的差异性,导致优化效率低下。因此,如何针对视频理解的特点,设计更有效的RFT方法,是本文要解决的核心问题。
核心思路:本文的核心思路是将视频理解过程分解为感知和推理两个独立的阶段,并分别进行优化。感知阶段负责从视频中提取关键信息,推理阶段则利用这些信息进行逻辑推理和问题解答。通过对这两个阶段进行解耦,可以更精确地评估每个阶段的性能,并针对性地进行优化,从而提高整体的视频理解能力。
技术框架:VideoP2R框架主要包含两个阶段:监督微调(SFT)和强化学习(RL)。在SFT阶段,首先构建一个高质量的流程感知思维链(CoT)数据集VideoP2R-CoT-162K,该数据集包含感知和推理两个阶段的详细标注。然后,使用该数据集对LVLM进行微调,使其具备初步的感知和推理能力。在RL阶段,引入一种新的流程感知分组相对策略优化(PA-GRPO)算法,为感知和推理阶段提供单独的奖励信号,从而更有效地优化模型的策略。
关键创新:本文最重要的技术创新点在于提出了流程感知的建模方法和PA-GRPO算法。流程感知的建模方法将视频理解分解为感知和推理两个阶段,并分别进行优化,这与传统的端到端方法不同。PA-GRPO算法则为感知和推理阶段提供单独的奖励信号,从而更有效地优化模型的策略。这种方法能够更精确地评估每个阶段的性能,并针对性地进行优化,从而提高整体的视频理解能力。
关键设计:在SFT阶段,采用了三步流程来生成VideoP2R-CoT-162K数据集,包括数据收集、标注和清洗。在RL阶段,PA-GRPO算法的关键在于如何设计感知和推理阶段的奖励函数。具体来说,感知阶段的奖励函数旨在鼓励模型提取更准确、更全面的视频信息,而推理阶段的奖励函数则旨在鼓励模型进行更合理的逻辑推理。此外,还设计了一些正则化项,以防止模型过度拟合训练数据。
🖼️ 关键图片


📊 实验亮点
VideoP2R在七个视频推理和理解基准测试中的六个上实现了最先进(SotA)的性能,包括MSRVTT-QA、MSVD-QA、TGIF-QA、ActivityNet-QA、TVQA和HowToQA。消融研究表明,流程感知建模和PA-GRPO算法均能有效提升模型性能。此外,研究还证明了模型的感知输出对于下游推理具有足够的信息。
🎯 应用场景
VideoP2R框架具有广泛的应用前景,例如智能监控、视频搜索、自动驾驶、视频内容分析和生成等领域。通过提升视频理解能力,可以实现更智能化的视频分析和处理,为人们的生活和工作带来便利。未来,该研究可以进一步扩展到更复杂的视频场景和任务中,例如视频对话、视频摘要等。
📄 摘要(原文)
Reinforcement fine-tuning (RFT), a two-stage framework consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) has shown promising results on improving reasoning ability of large language models (LLMs). Yet extending RFT to large video language models (LVLMs) remains challenging. We propose VideoP2R, a novel process-aware video RFT framework that enhances video reasoning by modeling perception and reasoning as distinct processes. In the SFT stage, we develop a three-step pipeline to generate VideoP2R-CoT-162K, a high-quality, process-aware chain-of-thought (CoT) dataset for perception and reasoning. In the RL stage, we introduce a novel process-aware group relative policy optimization (PA-GRPO) algorithm that supplies separate rewards for perception and reasoning. Extensive experiments show that VideoP2R achieves state-of-the-art (SotA) performance on six out of seven video reasoning and understanding benchmarks. Ablation studies further confirm the effectiveness of our process-aware modeling and PA-GRPO and demonstrate that model's perception output is information-sufficient for downstream reasoning.