AccKV: Towards Efficient Audio-Video LLMs Inference via Adaptive-Focusing and Cross-Calibration KV Cache Optimization
作者: Zhonghua Jiang, Kui Chen, Kunxi Li, Keting Yin, Yiyun Zhou, Zhaode Wang, Chengfei Lv, Shengyu Zhang
分类: cs.MM, cs.CV, cs.SD
发布日期: 2025-11-14
💡 一句话要点
AccKV:面向高效音视频LLM推理的自适应聚焦与交叉校准KV缓存优化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频大语言模型 KV缓存优化 自适应聚焦 交叉校准 多模态推理
📋 核心要点
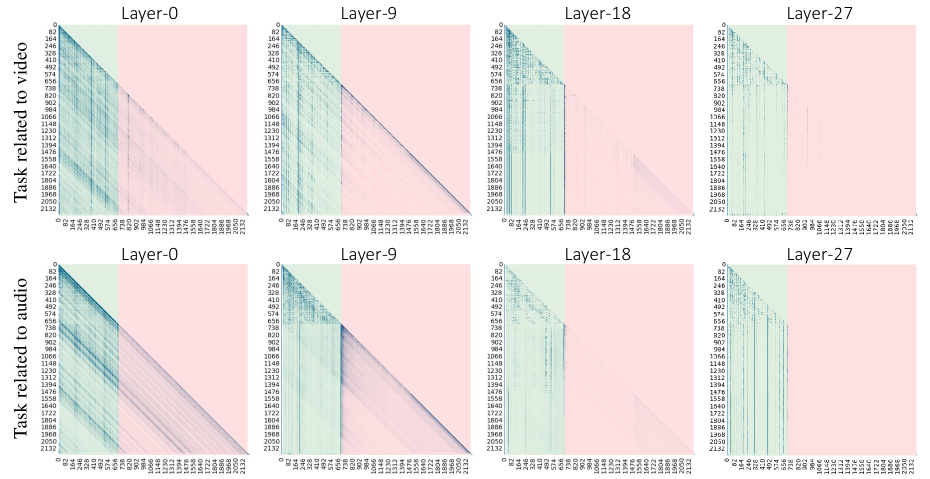
- 现有的AV-LLM推理面临着由于音视频数据时间维度扩展而导致的KV缓存过大的挑战,直接优化效果不佳。
- AccKV通过层自适应聚焦关键模态,并利用交叉校准技术对KV缓存进行优化,提升推理效率。
- 实验结果表明,AccKV能够在保持精度的前提下,显著提升AV-LLM的计算效率,具有实际应用价值。
📝 摘要(中文)
近年来,音视频大语言模型(AV-LLMs)在音视频问答和多模态对话系统等任务中表现出强大的能力。与静态图像嵌入相比,视频和音频引入了扩展的时间维度,导致更大的键值(KV)缓存。一种简单的优化策略是基于任务选择性地聚焦和保留音频或视频的KV缓存。然而,实验表明,AV-LLMs在高层对各种模态的注意力并不严格依赖于任务,而是更多地转向视频模态。此外,直接整合音频的时间KV和视频的时空KV可能导致信息混淆和AV-LLMs性能的显著下降。不加区分地处理音频和视频也可能导致对某种模态的过度压缩或保留,从而破坏模态之间的对齐。为了解决这些挑战,我们提出了AccKV,一个专为高效AV-LLMs推理设计的自适应聚焦和交叉校准KV缓存优化框架。我们的方法基于层自适应聚焦技术,根据不同层的特性选择性地聚焦于关键模态,并通过注意力重新分配来增强对高频token的识别。此外,我们提出了一种交叉校准技术,首先整合音频和视频模态内低效的KV缓存,然后将低优先级模态与高优先级模态对齐,以选择性地驱逐低优先级模态的KV缓存。实验结果表明,AccKV可以在保持精度的同时显著提高AV-LLMs的计算效率。
🔬 方法详解
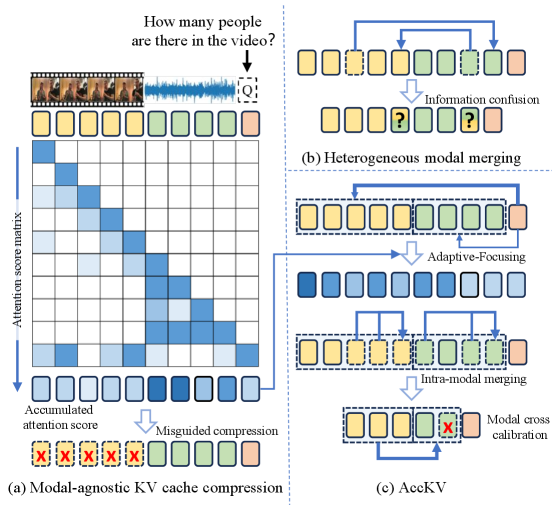
问题定义:AV-LLM推理过程中,音视频数据引入了时间维度,导致KV缓存显著增大,成为计算瓶颈。简单地对音频或视频KV缓存进行选择性保留的策略效果不佳,因为模型在高层对不同模态的注意力并非完全依赖于任务。此外,直接融合音频和视频的KV缓存可能导致信息混淆和性能下降。
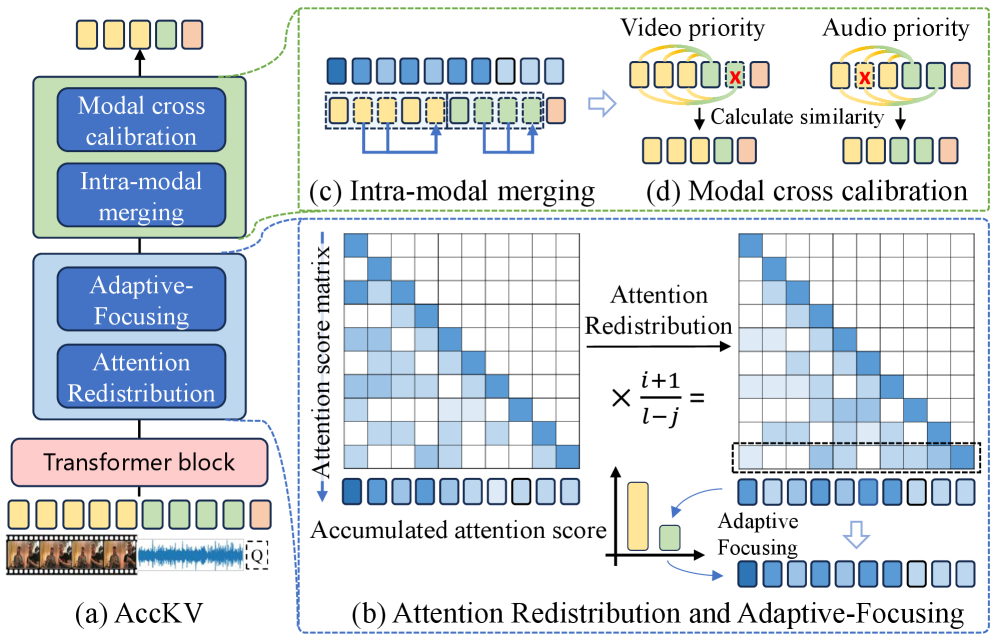
核心思路:AccKV的核心思路是根据AV-LLM不同层的特性,自适应地聚焦于关键模态,并利用交叉校准技术优化KV缓存。通过层自适应聚焦,模型可以更有效地利用不同模态的信息。交叉校准技术则通过模态内整合和模态间对齐,选择性地驱逐低优先级模态的KV缓存,从而减少计算量。
技术框架:AccKV框架包含两个主要模块:层自适应聚焦和交叉校准。层自适应聚焦模块根据不同层的特性,动态调整对音频和视频模态的关注度。交叉校准模块首先在模态内部整合低效的KV缓存,然后将低优先级模态与高优先级模态对齐,并选择性地移除低优先级模态的KV缓存。
关键创新:AccKV的关键创新在于其层自适应聚焦和交叉校准技术。层自适应聚焦能够根据模型的不同层动态调整对不同模态的关注度,从而更有效地利用信息。交叉校准技术则通过模态内整合和模态间对齐,实现了更精细的KV缓存管理,避免了信息混淆和性能下降。与现有方法相比,AccKV能够更有效地减少KV缓存大小,提高推理效率。
关键设计:层自适应聚焦模块通过分析模型不同层的注意力权重,确定每一层应该重点关注的模态。交叉校准模块使用一种基于注意力的机制来评估KV缓存的重要性,并根据重要性选择性地移除低优先级模态的KV缓存。具体的参数设置和损失函数细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文实验结果表明,AccKV能够在保持精度的前提下,显著提高AV-LLM的计算效率。具体的性能数据和对比基线在摘要中未给出,属于未知信息。但可以确定的是,AccKV通过自适应聚焦和交叉校准技术,有效地减少了KV缓存的大小,从而提升了推理速度。
🎯 应用场景
AccKV可应用于各种需要高效音视频理解的场景,例如智能助手、视频会议、自动驾驶、机器人等。通过降低AV-LLM的计算成本,AccKV可以促进这些模型在资源受限设备上的部署,并提升用户体验。未来,AccKV可以进一步扩展到其他多模态任务,并与其他优化技术相结合,实现更高效的AV-LLM推理。
📄 摘要(原文)
Recent advancements in Audio-Video Large Language Models (AV-LLMs) have enhanced their capabilities in tasks like audio-visual question answering and multimodal dialog systems. Video and audio introduce an extended temporal dimension, resulting in a larger key-value (KV) cache compared to static image embedding. A naive optimization strategy is to selectively focus on and retain KV caches of audio or video based on task. However, in the experiment, we observed that the attention of AV-LLMs to various modalities in the high layers is not strictly dependent on the task. In higher layers, the attention of AV-LLMs shifts more towards the video modality. In addition, we also found that directly integrating temporal KV of audio and spatial-temporal KV of video may lead to information confusion and significant performance degradation of AV-LLMs. If audio and video are processed indiscriminately, it may also lead to excessive compression or reservation of a certain modality, thereby disrupting the alignment between modalities. To address these challenges, we propose AccKV, an Adaptive-Focusing and Cross-Calibration KV cache optimization framework designed specifically for efficient AV-LLMs inference. Our method is based on layer adaptive focusing technology, selectively focusing on key modalities according to the characteristics of different layers, and enhances the recognition of heavy hitter tokens through attention redistribution. In addition, we propose a Cross-Calibration technique that first integrates inefficient KV caches within the audio and video modalities, and then aligns low-priority modalities with high-priority modalities to selectively evict KV cache of low-priority modalities. The experimental results show that AccKV can significantly improve the computational efficiency of AV-LLMs while maintaining accuracy.