CrossMed: A Multimodal Cross-Task Benchmark for Compositional Generalization in Medical Imaging
作者: Pooja Singh, Siddhant Ujjain, Tapan Kumar Gandhi, Sandeep Kumar
分类: cs.CV, cs.AI
发布日期: 2025-11-14
💡 一句话要点
CrossMed:一个用于评估医学影像中组合泛化能力的多模态跨任务基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学影像 多模态学习 组合泛化 视觉问答 基准测试
📋 核心要点
- 现有的多模态大型语言模型在医学影像组合泛化能力方面缺乏充分评估,尤其是在未见过的模态、解剖部位和任务组合上。
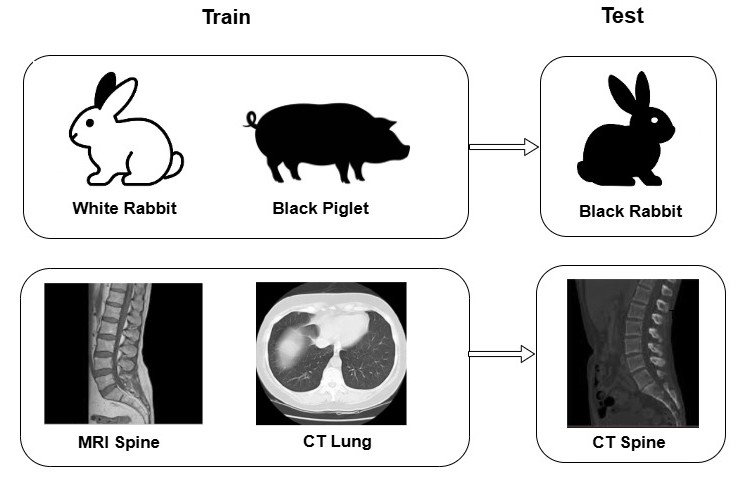
- CrossMed基准通过构建模态-解剖部位-任务(MAT)结构,将多个医学影像数据集统一为视觉问答格式,用于评估模型的组合泛化能力。
- 实验结果表明,多模态LLM在相关任务上表现良好,但在不相关和零重叠任务上性能显著下降,突显了组合泛化的挑战。
📝 摘要(中文)
本文提出了CrossMed,一个用于评估医学多模态大型语言模型中组合泛化(CG)能力的基准,该基准使用结构化的模态-解剖部位-任务(MAT)模式。CrossMed将四个公共数据集(CheXpert、SIIM-ACR、BraTS 2020和MosMedData)重新构建为统一的视觉问答(VQA)格式,生成了20,200个多项选择QA实例。研究评估了两个开源多模态LLM(LLaVA-Vicuna-7B和Qwen2-VL-7B)在相关和不相关MAT分割以及零重叠设置下的性能。结果表明,在相关分割上训练的模型达到了83.2%的分类准确率和0.75的分割cIoU,但在不相关和零重叠条件下性能显著下降。此外,还展示了跨任务迁移,仅使用分类数据训练时,分割性能提高了7% cIoU。传统模型表现出适度提升,证实了MAT框架的广泛效用,而多模态LLM在组合泛化方面表现出色。CrossMed为评估医学视觉-语言模型中的零样本、跨任务和模态无关泛化提供了一个严格的测试平台。
🔬 方法详解
问题定义:论文旨在解决医学影像领域多模态大型语言模型在组合泛化能力上的评估问题。现有方法缺乏对模型在未见过的模态、解剖部位和任务组合上的泛化能力的有效评估,这限制了模型在实际临床应用中的可靠性。
核心思路:论文的核心思路是构建一个结构化的基准数据集CrossMed,该数据集基于模态-解剖部位-任务(MAT)模式,将多个现有的医学影像数据集统一为视觉问答(VQA)格式。通过控制训练和测试数据中MAT三元组的重叠程度,可以系统地评估模型在不同组合泛化场景下的性能。
技术框架:CrossMed基准的构建流程包括以下几个主要步骤:1) 选择四个公开的医学影像数据集(CheXpert, SIIM-ACR, BraTS 2020, MosMedData);2) 将这些数据集中的数据转换为VQA格式,每个样本包含图像、问题和答案;3) 定义MAT模式,将每个样本与特定的模态、解剖部位和任务类型关联;4) 创建不同的数据分割,包括相关分割、不相关分割和零重叠分割,以评估不同程度的组合泛化能力。
关键创新:CrossMed的关键创新在于其结构化的MAT模式和统一的VQA格式。MAT模式允许对组合泛化能力进行细粒度的评估,而VQA格式则使得可以使用统一的模型架构处理不同类型的医学影像任务。此外,CrossMed还提供了零重叠分割,用于评估模型在完全未见过的MAT组合上的泛化能力。
关键设计:CrossMed基准使用了多项选择题作为VQA的答案形式,每个问题有四个选项。数据集的构建过程中,问题和答案的设计需要保证其与图像内容和MAT三元组的一致性。实验中,使用了LLaVA-Vicuna-7B和Qwen2-VL-7B作为多模态LLM的评估对象,并采用了分类准确率和分割cIoU作为评估指标。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在相关MAT分割上训练的模型达到了83.2%的分类准确率和0.75的分割cIoU。然而,在不相关和零重叠分割上,性能显著下降,突显了组合泛化的挑战。值得注意的是,通过跨任务迁移学习,仅使用分类数据训练的模型在分割任务上获得了7% cIoU的提升。传统模型(ResNet-50和U-Net)的性能提升有限,表明多模态LLM在组合泛化方面具有独特的优势。
🎯 应用场景
CrossMed基准的潜在应用领域包括医学影像诊断、辅助决策和医学教育。通过评估和提升多模态LLM的组合泛化能力,可以开发出更加可靠和通用的医学AI系统,从而提高诊断效率、减少误诊率,并为医生提供更全面的决策支持。未来,CrossMed可以扩展到更多医学影像模态和任务,并与其他医学知识库相结合,构建更强大的医学AI平台。
📄 摘要(原文)
Recent advances in multimodal large language models have enabled unified processing of visual and textual inputs, offering promising applications in general-purpose medical AI. However, their ability to generalize compositionally across unseen combinations of imaging modality, anatomy, and task type remains underexplored. We introduce CrossMed, a benchmark designed to evaluate compositional generalization (CG) in medical multimodal LLMs using a structured Modality-Anatomy-Task (MAT) schema. CrossMed reformulates four public datasets, CheXpert (X-ray classification), SIIM-ACR (X-ray segmentation), BraTS 2020 (MRI classification and segmentation), and MosMedData (CT classification) into a unified visual question answering (VQA) format, resulting in 20,200 multiple-choice QA instances. We evaluate two open-source multimodal LLMs, LLaVA-Vicuna-7B and Qwen2-VL-7B, on both Related and Unrelated MAT splits, as well as a zero-overlap setting where test triplets share no Modality, Anatomy, or Task with the training data. Models trained on Related splits achieve 83.2 percent classification accuracy and 0.75 segmentation cIoU, while performance drops significantly under Unrelated and zero-overlap conditions, demonstrating the benchmark difficulty. We also show cross-task transfer, where segmentation performance improves by 7 percent cIoU even when trained using classification-only data. Traditional models (ResNet-50 and U-Net) show modest gains, confirming the broad utility of the MAT framework, while multimodal LLMs uniquely excel at compositional generalization. CrossMed provides a rigorous testbed for evaluating zero-shot, cross-task, and modality-agnostic generalization in medical vision-language models.