Draft and Refine with Visual Experts
作者: Sungheon Jeong, Ryozo Masukawa, Jihong Park, Sanggeon Yun, Wenjun Huang, Hanning Chen, Mahdi Imani, Mohsen Imani
分类: cs.CV
发布日期: 2025-11-14 (更新: 2025-11-21)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Draft and Refine框架,提升LVLM视觉信息利用率,减少幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态推理 视觉利用率 幻觉减少 知识蒸馏
📋 核心要点
- 现有LVLM过度依赖语言先验,缺乏对视觉信息利用率的有效度量,导致产生幻觉。
- 提出Draft and Refine框架,通过问题条件利用率指标指导模型利用视觉专家反馈进行优化。
- 实验表明,DnR框架在VQA和图像描述任务上提升了准确率,并有效减少了幻觉。
📝 摘要(中文)
现有的大型视觉语言模型(LVLMs)虽然展现出强大的多模态推理能力,但由于过度依赖语言先验而非视觉证据,常常产生无根据或幻觉性的响应。这种局限性突显了缺乏对这些模型在推理过程中实际使用视觉信息程度的定量衡量。我们提出了Draft and Refine (DnR),一个由问题条件利用率指标驱动的代理框架。该指标通过首先构建一个查询条件相关性图来定位问题特定的线索,然后通过相关性引导的概率掩蔽来测量依赖性,从而量化模型对视觉证据的依赖程度。在该指标的指导下,DnR代理使用来自外部视觉专家的有针对性的反馈来改进其初始草案。每个专家的输出(例如框或掩码)被渲染为图像上的视觉线索,并重新查询模型以选择产生最大利用率改进的响应。这个过程在不进行重新训练或架构更改的情况下加强了视觉基础。在VQA和字幕基准测试上的实验表明,一致的准确性提升和幻觉减少,表明测量视觉利用率提供了一条通向更可解释和证据驱动的多模态代理系统的原则性路径。
🔬 方法详解
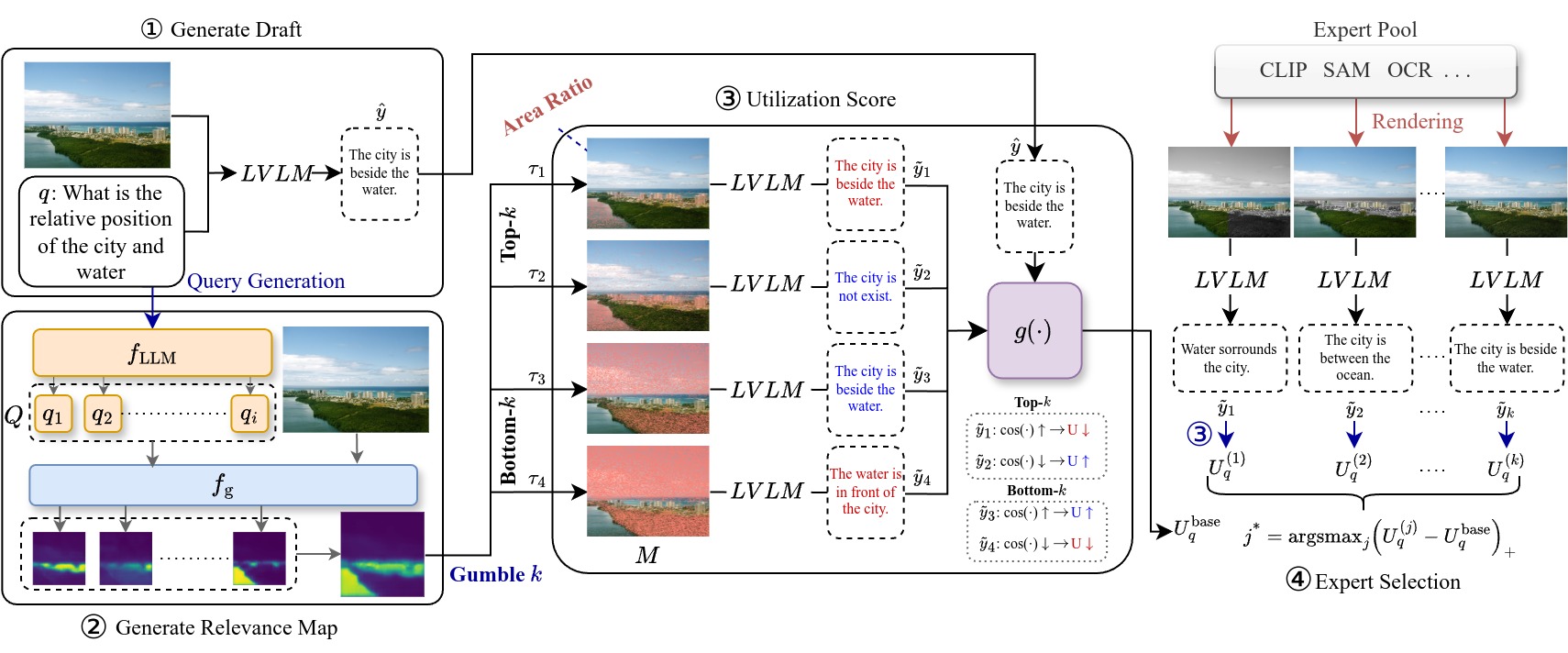
问题定义:现有的大型视觉语言模型(LVLMs)在多模态推理时,过度依赖语言先验知识,而对视觉信息的利用不足,导致生成不准确甚至产生幻觉。缺乏一种有效的定量方法来衡量模型对视觉信息的依赖程度,限制了模型的可解释性和可靠性。
核心思路:DnR框架的核心思路是通过一个问题条件利用率指标来量化模型对视觉信息的依赖程度,并利用外部视觉专家的反馈来引导模型更加关注相关的视觉线索。通过迭代的“草稿-精炼”过程,逐步提升模型对视觉信息的利用率,从而减少幻觉并提高准确性。
技术框架:DnR框架主要包含以下几个模块:1) 问题条件相关性图构建:根据问题定位图像中相关的视觉线索。2) 利用率指标计算:通过相关性引导的概率掩蔽来量化模型对视觉证据的依赖程度。3) 视觉专家反馈:利用外部视觉专家(例如目标检测器、分割模型)提供视觉线索(例如边界框、掩码)。4) 草稿-精炼迭代:模型根据视觉专家的反馈,重新生成响应,并选择利用率提升最大的响应。
关键创新:DnR框架的关键创新在于提出了问题条件利用率指标,该指标能够定量地衡量模型对视觉信息的依赖程度,并以此为基础指导模型的优化。与现有方法不同,DnR框架不需要重新训练或修改模型架构,而是通过外部视觉专家的反馈来提升模型的性能。
关键设计:利用率指标的计算涉及相关性图的构建和概率掩蔽。相关性图通过注意力机制或梯度信息等方法获得,用于定位与问题相关的视觉区域。概率掩蔽则根据相关性图的权重,对图像进行随机遮挡,并观察模型输出的变化,从而评估模型对不同视觉区域的依赖程度。视觉专家的选择可以根据具体任务进行调整,例如,对于VQA任务,可以使用目标检测器来提供目标位置信息;对于图像描述任务,可以使用分割模型来提供对象分割信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DnR框架在VQA和图像描述任务上均取得了显著的性能提升。例如,在VQA任务上,DnR框架将准确率提高了多个百分点,并显著减少了幻觉现象。与现有的基线方法相比,DnR框架在不进行重新训练或修改模型架构的情况下,实现了更优的性能。
🎯 应用场景
该研究成果可应用于各种需要视觉理解的多模态任务,例如视觉问答、图像描述、机器人导航等。通过提升模型对视觉信息的利用率,可以提高这些应用场景下的准确性和可靠性,并减少模型产生幻觉的风险。该方法还有助于提高模型的可解释性,使用户能够更好地理解模型的推理过程。
📄 摘要(原文)
While recent Large Vision-Language Models (LVLMs) exhibit strong multimodal reasoning abilities, they often produce ungrounded or hallucinated responses because they rely too heavily on linguistic priors instead of visual evidence. This limitation highlights the absence of a quantitative measure of how much these models actually use visual information during reasoning. We propose Draft and Refine (DnR), an agent framework driven by a question-conditioned utilization metric. The metric quantifies the model's reliance on visual evidence by first constructing a query-conditioned relevance map to localize question-specific cues and then measuring dependence through relevance-guided probabilistic masking. Guided by this metric, the DnR agent refines its initial draft using targeted feedback from external visual experts. Each expert's output (such as boxes or masks) is rendered as visual cues on the image, and the model is re-queried to select the response that yields the largest improvement in utilization. This process strengthens visual grounding without retraining or architectural changes. Experiments across VQA and captioning benchmarks show consistent accuracy gains and reduced hallucination, demonstrating that measuring visual utilization provides a principled path toward more interpretable and evidence-driven multimodal agent systems. Code is available at https://github.com/EavnJeong/Draft-and-Refine-with-Visual-Experts.