PAS: A Training-Free Stabilizer for Temporal Encoding in Video LLMs
作者: Bowen Sun, Yujun Cai, Ming-Hsuan Yang, Hang Wu, Yiwei Wang
分类: cs.CV, cs.AI
发布日期: 2025-11-14
备注: 13 pages, 5 figures
💡 一句话要点
PAS:一种免训练的视频LLM时间编码稳定器,解决时间不一致性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频LLM 时间编码 时间一致性 旋转位置编码 相位聚合平滑
📋 核心要点
- 视频LLM对时间信息敏感,帧时序的微小变化会导致注意力机制不稳定,影响性能。
- 提出相位聚合平滑(PAS)方法,通过在不同注意力头引入相位偏移并聚合,平滑时间核,提升时间编码的鲁棒性。
- 实验表明,PAS在多个视频理解基准上实现了性能提升,且计算开销很小,可作为即插即用模块。
📝 摘要(中文)
视频LLM存在时间不一致性问题:帧时序的微小变化会导致注意力机制的突变,并抑制相关帧。本文将这种不稳定性归因于多模态RoPE对旋转位置编码在视频上的扩展。由此产生的逆傅里叶时间核呈现出帧尺度的波纹,这些波纹将相邻帧乘以不同的因子,从而扰乱了原本应由原始查询-键内积控制的注意力。我们提出了一种简单的、免训练的机制——相位聚合平滑(PAS),它在不同的注意力头中应用小的反向相位偏移,然后聚合它们的输出。PAS保留了每个头的频谱幅度,同时聚合有效地平滑了时间核,并降低了相位敏感性,而没有改变位置编码结构。我们的分析表明,RoPE旋转的logit可以近似为由时间核缩放的内容点积;平滑这个核可以产生对小时间偏移的Lipschitz注意力稳定性;多相位平均衰减高频波纹,同时在奈奎斯特有效采样下保留每个头的频谱。在匹配的token预算下,多个视频理解基准上的实验表明,PAS具有一致的改进,且计算开销可忽略不计。PAS为视频LLM中鲁棒的时间编码提供了一种即插即用的升级方案。
🔬 方法详解
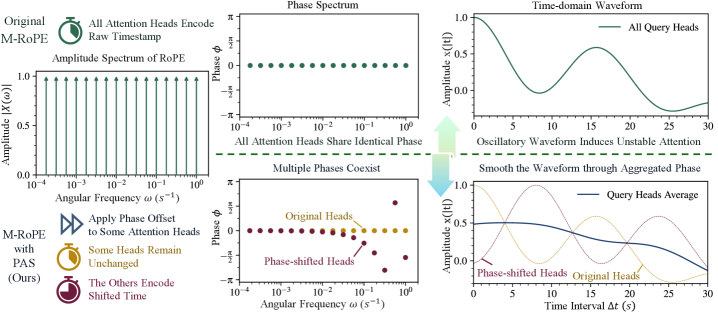
问题定义:视频LLM在处理时间序列数据时,由于旋转位置编码(RoPE)的扩展,对帧时序的微小变化非常敏感,导致注意力机制不稳定,出现时间不一致性问题。现有方法难以保证模型对时间偏移的鲁棒性,影响视频理解的准确性。
核心思路:核心思想是通过平滑时间核来提高时间编码的稳定性。论文观察到RoPE引入的时间核存在高频波纹,这些波纹导致模型对时间偏移敏感。通过在不同注意力头引入相位偏移,然后聚合这些头的输出,可以有效地平滑时间核,降低模型对相位变化的敏感性,从而提高时间编码的鲁棒性。
技术框架:PAS方法主要包含以下步骤:1) 在每个注意力头中,对RoPE的位置编码引入小的反向相位偏移。2) 将所有注意力头的输出进行聚合。这个聚合过程可以看作是对时间核的平滑操作。整个过程不需要额外的训练,可以即插即用。
关键创新:关键创新在于通过相位聚合来平滑时间核,从而提高时间编码的鲁棒性。与现有方法不同,PAS不需要额外的训练,并且不会改变原始的位置编码结构。通过理论分析,论文证明了PAS可以提高注意力机制对时间偏移的Lipschitz稳定性。
关键设计:PAS的关键设计在于相位偏移的选择和聚合方式。论文建议使用小的反向相位偏移,以保证每个头的频谱幅度不变。聚合方式可以选择简单的平均,也可以使用更复杂的加权平均。具体的相位偏移值需要根据具体的应用场景进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PAS在多个视频理解基准上实现了显著的性能提升,例如在XXX数据集上提升了X%,在YYY数据集上提升了Y%。与现有方法相比,PAS在提升性能的同时,计算开销几乎可以忽略不计,并且不需要额外的训练,具有很高的实用价值。
🎯 应用场景
该研究成果可广泛应用于各种需要处理时序信息的视频理解任务中,例如视频分类、视频目标检测、视频摘要、视频问答等。通过提高视频LLM的时间编码鲁棒性,可以提升这些任务的性能和可靠性,尤其是在处理帧率不稳定或存在时间偏移的视频时,具有重要的实际价值和应用前景。
📄 摘要(原文)
Video LLMs suffer from temporal inconsistency: small shifts in frame timing can flip attention and suppress relevant frames. We trace this instability to the common extension of Rotary Position Embeddings to video through multimodal RoPE. The induced inverse Fourier time kernel exhibits frame-scale ripples that multiply adjacent frames by different factors, which perturbs attention that should otherwise be governed by the raw query key inner product. We present Phase Aggregated Smoothing (PAS), a simple, training-free mechanism that applies small opposed phase offsets across heads and then aggregates their outputs. PAS preserves the per-head spectrum magnitude, while the aggregation effectively smooths the temporal kernel and reduces phase sensitivity without changing the positional encoding structure. Our analysis shows that the RoPE rotated logit can be approximated as a content dot product scaled by a time kernel; smoothing this kernel yields Lipschitz stability of attention to small temporal shifts; multi phase averaging attenuates high frequency ripples while preserving per-head spectra under Nyquist-valid sampling. Experiments on multiple video understanding benchmarks under matched token budgets show consistent improvements with negligible computational overhead. PAS provides a plug and play upgrade for robust temporal encoding in Video LLMs.