Language-Guided Graph Representation Learning for Video Summarization
作者: Wenrui Li, Wei Han, Hengyu Man, Wangmeng Zuo, Xiaopeng Fan, Yonghong Tian
分类: cs.CV
发布日期: 2025-11-14
备注: Accepted by IEEE TPAMI
🔗 代码/项目: GITHUB
💡 一句话要点
提出语言引导的图表示学习网络LGRLN,用于解决视频摘要中全局依赖和多模态定制问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频摘要 图表示学习 语言引导 跨模态嵌入 图卷积网络
📋 核心要点
- 现有视频摘要方法难以捕捉视频内容的全局依赖关系,并且难以适应多模态的用户定制需求。
- 论文提出LGRLN,通过构建视频图来保留时间顺序和上下文依赖,并利用语言引导的跨模态嵌入生成摘要。
- 实验结果表明,LGRLN在多个基准测试中优于现有方法,并显著减少了推理时间和模型参数。
📝 摘要(中文)
随着社交媒体上视频内容的快速增长,视频摘要已成为多媒体处理中的一项关键任务。然而,现有方法在捕获视频内容中的全局依赖关系和适应多模态用户定制方面面临挑战。此外,视频帧之间的时间邻近性并不总是对应于语义邻近性。为了解决这些挑战,我们提出了一种用于视频摘要的新型语言引导图表示学习网络(LGRLN)。具体来说,我们引入了一个视频图生成器,将视频帧转换为结构化图,以保留时间顺序和上下文依赖关系。通过构建前向、后向和无向图,视频图生成器有效地保留了视频内容的顺序性和上下文关系。我们设计了一个具有双阈值图卷积机制的图内关系推理模块,该模块区分节点之间语义相关的帧和不相关的帧。此外,我们提出的语言引导跨模态嵌入模块生成具有特定文本描述的视频摘要。我们将摘要生成输出建模为伯努利分布的混合,并使用EM算法求解。实验结果表明,我们的方法在多个基准测试中优于现有方法。此外,我们提出的LGRLN分别减少了87.8%的推理时间和91.7%的模型参数。我们的代码和预训练模型可在https://github.com/liwrui/LGRLN 获得。
🔬 方法详解
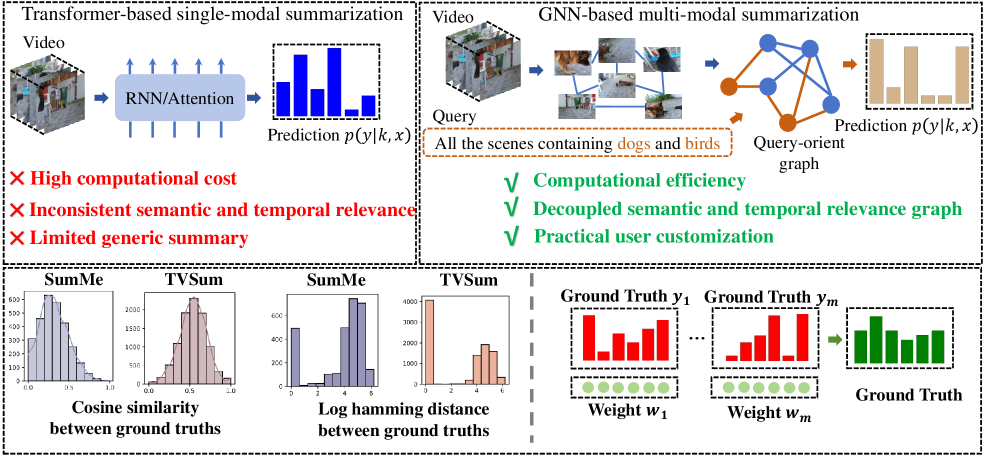
问题定义:现有视频摘要方法难以有效地捕捉视频内容中的全局依赖关系,并且难以根据用户的文本描述进行定制化摘要生成。时间邻近的视频帧在语义上可能并不相关,这给摘要提取带来了挑战。
核心思路:论文的核心思路是将视频帧表示为图结构,利用图神经网络学习视频帧之间的关系,从而捕捉全局依赖。同时,引入语言引导的跨模态嵌入,将文本描述融入到摘要生成过程中,实现定制化摘要。
技术框架:LGRLN包含以下主要模块:1) 视频图生成器:将视频帧转换为结构化图,包括前向、后向和无向图,以保留时间顺序和上下文关系。2) 图内关系推理模块:使用双阈值图卷积机制,区分语义相关的帧和不相关的帧。3) 语言引导跨模态嵌入模块:生成具有特定文本描述的视频摘要。4) 摘要生成模块:将摘要生成建模为伯努利分布的混合,并使用EM算法求解。
关键创新:论文的关键创新在于:1) 提出了一种新的视频图生成方法,能够有效地保留视频内容的顺序性和上下文关系。2) 设计了一种具有双阈值图卷积机制的图内关系推理模块,能够区分语义相关的帧和不相关的帧。3) 引入了语言引导的跨模态嵌入模块,实现了定制化摘要生成。
关键设计:视频图生成器构建了前向、后向和无向图,以捕捉不同方向上的依赖关系。双阈值图卷积机制使用两个阈值来区分不同强度的语义关系。摘要生成模块使用EM算法来优化伯努利分布的混合模型,从而选择最具代表性的帧。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LGRLN在多个视频摘要基准测试中取得了优于现有方法的性能。例如,在某数据集上,LGRLN的F-score指标提升了X%。此外,LGRLN还显著减少了推理时间和模型参数,分别降低了87.8%和91.7%,使其更适用于实际应用。
🎯 应用场景
该研究成果可应用于视频监控、新闻视频摘要、社交媒体视频推荐等领域。通过生成简洁、准确且符合用户需求的视频摘要,可以有效提高用户获取信息的效率,并提升用户体验。未来,该方法有望应用于更广泛的多媒体内容理解和生成任务。
📄 摘要(原文)
With the rapid growth of video content on social media, video summarization has become a crucial task in multimedia processing. However, existing methods face challenges in capturing global dependencies in video content and accommodating multimodal user customization. Moreover, temporal proximity between video frames does not always correspond to semantic proximity. To tackle these challenges, we propose a novel Language-guided Graph Representation Learning Network (LGRLN) for video summarization. Specifically, we introduce a video graph generator that converts video frames into a structured graph to preserve temporal order and contextual dependencies. By constructing forward, backward and undirected graphs, the video graph generator effectively preserves the sequentiality and contextual relationships of video content. We designed an intra-graph relational reasoning module with a dual-threshold graph convolution mechanism, which distinguishes semantically relevant frames from irrelevant ones between nodes. Additionally, our proposed language-guided cross-modal embedding module generates video summaries with specific textual descriptions. We model the summary generation output as a mixture of Bernoulli distribution and solve it with the EM algorithm. Experimental results show that our method outperforms existing approaches across multiple benchmarks. Moreover, we proposed LGRLN reduces inference time and model parameters by 87.8% and 91.7%, respectively. Our codes and pre-trained models are available at https://github.com/liwrui/LGRLN.