DEFT-LLM: Disentangled Expert Feature Tuning for Micro-Expression Recognition
作者: Ren Zhang, Huilai Li, Chao qi, Guoliang Xu, Tianyu Zhou, Wei wei, Jianqin Yin
分类: cs.CV, cs.HC
发布日期: 2025-11-14
💡 一句话要点
提出DEFT-LLM,通过解耦专家特征调整微表情识别,提升性能与可解释性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 微表情识别 多模态学习 大型语言模型 特征解耦 指令学习
📋 核心要点
- 现有微表情识别方法难以区分静态外观和动态运动,导致模型无法有效捕捉细微表情变化。
- DEFT-LLM通过多专家解耦面部动态,将其分解为结构、动态纹理和运动语义等独立表示。
- 该方法构建了Uni-MER数据集,利用光流和动作单元标签约束,对齐文本指令与局部面部运动。
📝 摘要(中文)
微表情识别(MER)对于推断真实情感至关重要。将多模态大型语言模型(MLLM)应用于此任务,可以实现面部运动的时空分析并提供可解释的描述。然而,仍然存在两个核心挑战:(1)静态外观和动态运动线索的纠缠阻碍了模型专注于细微的运动;(2)现有MER数据集中的文本标签不能完全对应于潜在的面部肌肉运动,从而在文本监督和物理运动之间产生语义差距。为了解决这些问题,我们提出了DEFT-LLM,它通过多专家解耦实现运动语义对齐。我们首先引入Uni-MER,一个运动驱动的指令数据集,旨在将文本与局部面部运动对齐。它的构建利用了光流和动作单元(AU)标签的双重约束,以确保时空一致性以及与运动的合理对应关系。然后,我们设计了一个具有三个专家的架构,以将面部动态解耦为独立且可解释的表示(结构、动态纹理和运动语义)。通过将来自Uni-MER的指令对齐知识集成到DEFT-LLM中,我们的方法为微表情注入了有效的物理先验,同时也利用了大型语言模型的跨模态推理能力,从而能够精确捕捉细微的情感线索。在多个具有挑战性的MER基准上的实验表明,该方法具有最先进的性能,并且在局部面部运动的可解释建模方面具有特别的优势。
🔬 方法详解
问题定义:微表情识别旨在从细微的面部运动中推断真实情感。现有方法的痛点在于难以有效分离静态外观和动态运动信息,导致模型无法专注于捕捉细微的表情变化。此外,现有数据集的文本标签与实际的面部肌肉运动之间存在语义鸿沟,阻碍了模型学习准确的运动语义。
核心思路:DEFT-LLM的核心思路是通过多专家解耦的方式,将面部动态分解为独立且可解释的表示,包括结构、动态纹理和运动语义。同时,构建一个运动驱动的指令数据集Uni-MER,以对齐文本指令与局部面部运动,从而弥合文本监督和物理运动之间的语义差距。这样设计的目的是为了让模型能够更好地关注细微的运动信息,并学习到更准确的运动语义表示。
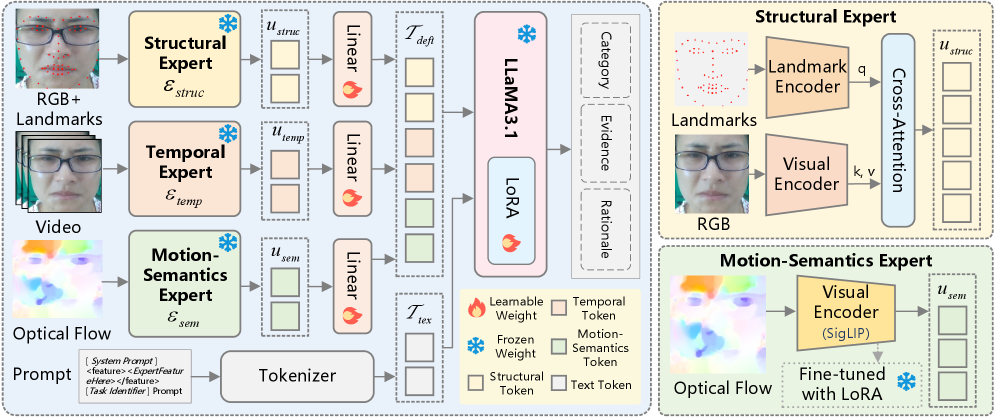
技术框架:DEFT-LLM的整体架构包含三个专家模块,分别负责提取面部结构信息、动态纹理信息和运动语义信息。首先,使用卷积神经网络提取面部图像的特征。然后,三个专家模块分别处理这些特征,生成各自的表示。这些表示被融合后输入到大型语言模型中,进行跨模态推理,最终得到微表情的识别结果。Uni-MER数据集用于训练模型,通过光流和动作单元标签的双重约束,确保时空一致性以及与运动的合理对应关系。
关键创新:DEFT-LLM的关键创新在于多专家解耦和运动驱动的指令数据集。多专家解耦能够将面部动态分解为独立且可解释的表示,从而更好地捕捉细微的运动信息。Uni-MER数据集能够对齐文本指令与局部面部运动,弥合文本监督和物理运动之间的语义差距。这两个创新共同提升了模型在微表情识别任务上的性能和可解释性。
关键设计:Uni-MER数据集的构建采用了光流和动作单元标签的双重约束,以确保时空一致性。三个专家模块的具体网络结构未知,但其目标是提取结构、动态纹理和运动语义三种不同的特征表示。损失函数的设计未知,但推测会包含对齐文本指令和面部运动的损失项,以及促进专家模块学习独立表示的损失项。
🖼️ 关键图片


📊 实验亮点
DEFT-LLM在多个具有挑战性的微表情识别基准上取得了最先进的性能。论文中提到该方法在局部面部运动的可解释建模方面具有特别的优势,但没有提供具体的性能数据和提升幅度。具体的实验结果未知,需要查阅原文。
🎯 应用场景
DEFT-LLM在人机交互、心理学研究、安全监控等领域具有广泛的应用前景。它可以用于提升人机交互的自然性和准确性,帮助心理学家更好地理解人类情感,以及在安全监控中识别潜在的威胁行为。未来,该研究可以进一步扩展到其他情感识别任务,例如语音情感识别和生理信号情感识别。
📄 摘要(原文)
Micro expression recognition (MER) is crucial for inferring genuine emotion. Applying a multimodal large language model (MLLM) to this task enables spatio-temporal analysis of facial motion and provides interpretable descriptions. However, there are still two core challenges: (1) The entanglement of static appearance and dynamic motion cues prevents the model from focusing on subtle motion; (2) Textual labels in existing MER datasets do not fully correspond to underlying facial muscle movements, creating a semantic gap between text supervision and physical motion. To address these issues, we propose DEFT-LLM, which achieves motion semantic alignment by multi-expert disentanglement. We first introduce Uni-MER, a motion-driven instruction dataset designed to align text with local facial motion. Its construction leverages dual constraints from optical flow and Action Unit (AU) labels to ensure spatio-temporal consistency and reasonable correspondence to the movements. We then design an architecture with three experts to decouple facial dynamics into independent and interpretable representations (structure, dynamic textures, and motion-semantics). By integrating the instruction-aligned knowledge from Uni-MER into DEFT-LLM, our method injects effective physical priors for micro expressions while also leveraging the cross modal reasoning ability of large language models, thus enabling precise capture of subtle emotional cues. Experiments on multiple challenging MER benchmarks demonstrate state-of-the-art performance, as well as a particular advantage in interpretable modeling of local facial motion.