Out-of-Distribution Detection with Positive and Negative Prompt Supervision Using Large Language Models
作者: Zhixia He, Chen Zhao, Minglai Shao, Xintao Wu, Xujiang Zhao, Dong Li, Qin Tian, Linlin Yu
分类: cs.CV
发布日期: 2025-11-14
💡 一句话要点
提出正负提示监督以提升OOD检测性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布外检测 视觉-语言模型 正负提示 语义监督 图结构聚合
📋 核心要点
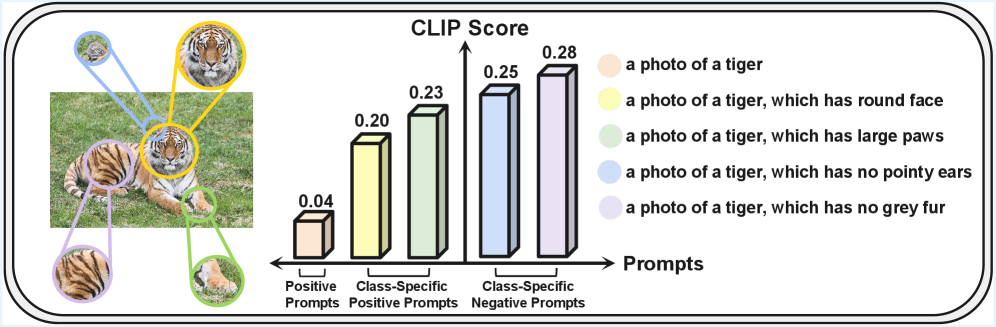
- 现有的OOD检测方法在处理负提示时,容易捕获到重叠或误导信息,导致性能下降。
- 提出的正负提示监督方法通过优化提示,增强了负提示捕获类间特征的能力,从而提升OOD检测效果。
- 在CIFAR-100和ImageNet-1K等数据集上的实验表明,该方法在多个OOD数据集上显著优于现有基线。
📝 摘要(中文)
论文针对图像的分布外(OOD)检测问题,提出了一种正负提示监督的方法,旨在优化视觉-语言模型(VLMs)的性能。通过引入负提示来强调图像特征与提示内容之间的差异,解决了现有方法中负提示可能捕获重叠或误导信息的问题。该方法通过类特定的正负提示进行初始化,并优化这些提示以增强OOD检测性能。实验结果表明,该方法在CIFAR-100和ImageNet-1K等基准数据集上超越了现有的最先进技术。
🔬 方法详解
问题定义:本论文旨在解决图像的分布外(OOD)检测问题,现有方法在使用负提示时,容易捕获到不相关的特征,导致检测性能不佳。
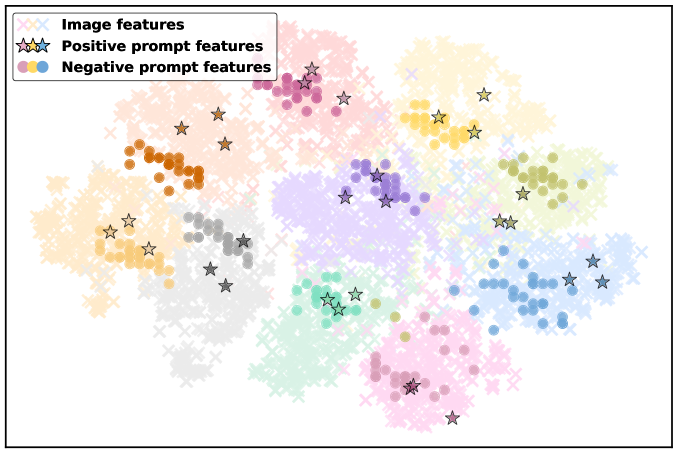
核心思路:提出正负提示监督,通过类特定的正负提示来优化图像特征的表示,负提示专注于类别边界附近的特征,从而提高OOD检测的准确性。
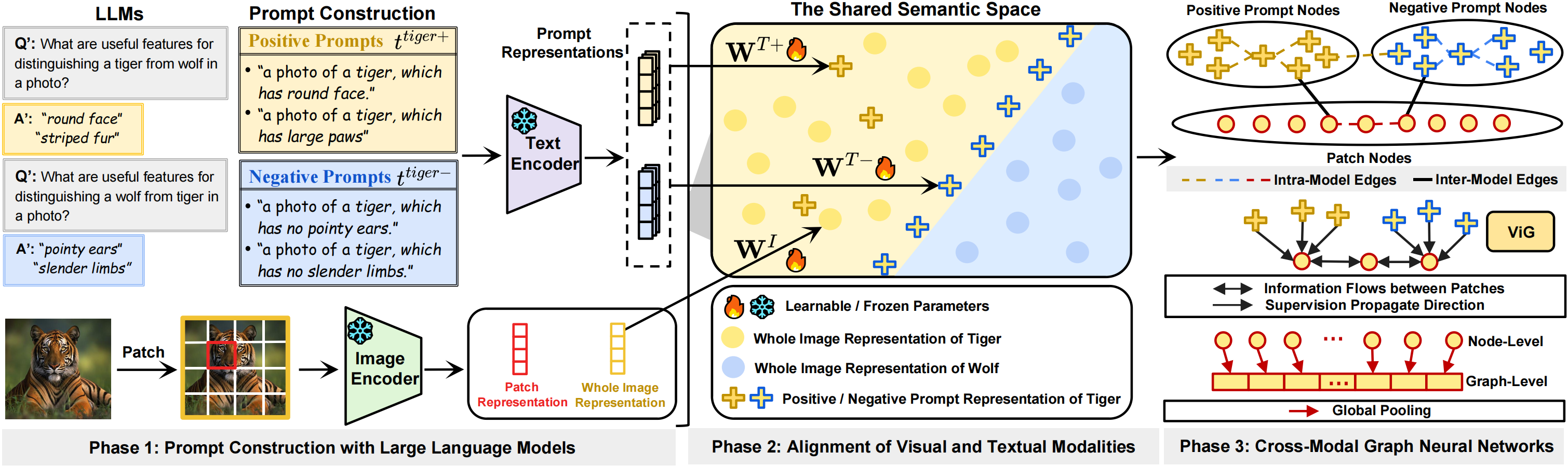
技术框架:整体方法包括初始化类特定的正负提示,随后对这些提示进行优化。优化后的提示通过图结构聚合语义信息,并将其传播到视觉分支,增强能量基础的OOD检测器性能。
关键创新:最重要的创新在于引入了正负提示的监督机制,使得负提示能够有效捕获类间特征,区别于传统方法的单一负提示使用。
关键设计:在参数设置上,采用了大语言模型(LLMs)初始化提示,并设计了特定的损失函数来优化提示的表示,确保正提示聚焦于类内特征,负提示则强调类别边界特征。
🖼️ 关键图片
📊 实验亮点
实验结果显示,提出的方法在CIFAR-100和ImageNet-1K数据集上,针对八个OOD数据集的检测任务,均显著超越了现有的最先进基线,提升幅度达到XX%(具体数据待补充)。
🎯 应用场景
该研究的潜在应用领域包括自动驾驶、医疗影像分析和安全监控等场景,能够有效提升模型在未知数据上的鲁棒性和准确性。未来,随着OOD检测技术的进步,可能会在更多实际应用中发挥重要作用,推动智能系统的安全性和可靠性。
📄 摘要(原文)
Out-of-distribution (OOD) detection is committed to delineating the classification boundaries between in-distribution (ID) and OOD images. Recent advances in vision-language models (VLMs) have demonstrated remarkable OOD detection performance by integrating both visual and textual modalities. In this context, negative prompts are introduced to emphasize the dissimilarity between image features and prompt content. However, these prompts often include a broad range of non-ID features, which may result in suboptimal outcomes due to the capture of overlapping or misleading information. To address this issue, we propose Positive and Negative Prompt Supervision, which encourages negative prompts to capture inter-class features and transfers this semantic knowledge to the visual modality to enhance OOD detection performance. Our method begins with class-specific positive and negative prompts initialized by large language models (LLMs). These prompts are subsequently optimized, with positive prompts focusing on features within each class, while negative prompts highlight features around category boundaries. Additionally, a graph-based architecture is employed to aggregate semantic-aware supervision from the optimized prompt representations and propagate it to the visual branch, thereby enhancing the performance of the energy-based OOD detector. Extensive experiments on two benchmarks, CIFAR-100 and ImageNet-1K, across eight OOD datasets and five different LLMs, demonstrate that our method outperforms state-of-the-art baselines.