MCN-CL: Multimodal Cross-Attention Network and Contrastive Learning for Multimodal Emotion Recognition
作者: Feng Li, Ke Wu, Yongwei Li
分类: cs.CV, cs.AI
发布日期: 2025-11-14
备注: Accepted by 32nd International Conference on MultiMedia Modeling (MMM 2026)
💡 一句话要点
提出MCN-CL模型,利用跨模态注意力与对比学习提升多模态情感识别性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感识别 跨模态注意力 对比学习 三重查询机制 硬负样本挖掘
📋 核心要点
- 现有方法在多模态情感识别中面临类别不平衡、面部动作建模复杂和模态异质性等挑战。
- MCN-CL模型利用三重查询机制和硬负样本挖掘策略,有效处理模态异质性和类别不平衡问题。
- 在IEMOCAP和MELD数据集上,MCN-CL的加权F1分数分别提升了3.42%和5.73%,优于现有方法。
📝 摘要(中文)
本文提出了一种用于多模态情感识别的多模态跨注意力网络与对比学习方法(MCN-CL)。多模态情感识别在心理健康监测、教育互动和人机交互等领域起着关键作用。然而,现有方法通常面临类别分布不平衡、动态面部动作单元时间建模复杂以及模态异质性导致特征融合困难等挑战。针对社交媒体场景下多模态数据爆炸式增长,构建高效的跨模态情感识别融合框架的需求日益迫切。MCN-CL采用三重查询机制和硬负样本挖掘策略,在保留重要情感线索的同时消除特征冗余,有效解决了模态异质性和类别不平衡问题。在IEMOCAP和MELD数据集上的实验结果表明,该方法优于现有技术,加权F1分数分别提高了3.42%和5.73%。
🔬 方法详解
问题定义:论文旨在解决多模态情感识别中由于模态异质性、类别不平衡以及动态面部动作单元时间建模复杂性导致的特征融合困难问题。现有方法难以有效融合不同模态的信息,并且容易受到类别不平衡的影响,导致识别精度下降。
核心思路:论文的核心思路是利用跨模态注意力机制来学习不同模态之间的关联,并通过对比学习来增强模型对情感特征的区分能力。三重查询机制用于提取更全面的情感信息,硬负样本挖掘策略用于解决类别不平衡问题,从而提升模型的泛化能力。
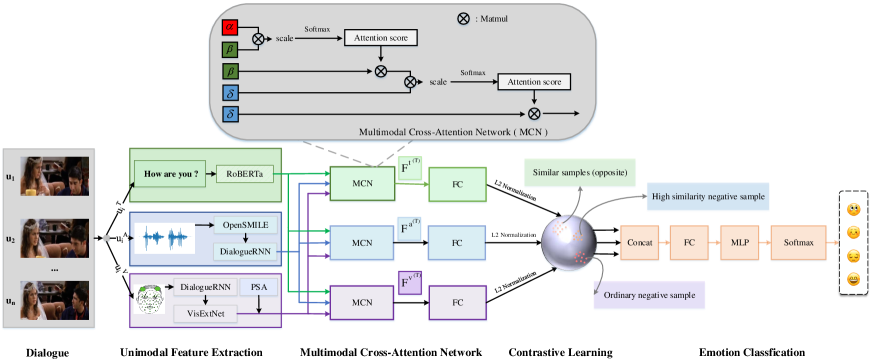
技术框架:MCN-CL模型主要包含以下几个模块:1) 特征提取模块,用于提取不同模态(如文本、音频、视频)的特征;2) 跨模态注意力网络,利用三重查询机制学习模态间的关联;3) 对比学习模块,通过构造正负样本对,增强模型对情感特征的区分能力;4) 分类器,用于最终的情感分类。整体流程是先提取各模态特征,然后通过跨模态注意力网络进行融合,再利用对比学习进行特征优化,最后通过分类器进行情感识别。
关键创新:论文的关键创新在于提出了三重查询机制和硬负样本挖掘策略。三重查询机制能够更全面地捕捉不同模态之间的关联信息,而硬负样本挖掘策略能够有效解决类别不平衡问题,从而提升模型的性能。与现有方法相比,MCN-CL能够更有效地融合不同模态的信息,并且具有更好的鲁棒性。
关键设计:论文中,三重查询机制的具体实现方式是使用三个不同的查询向量来分别关注不同模态的信息。硬负样本挖掘策略则是通过选择与正样本相似但标签不同的样本作为负样本,从而增强模型的区分能力。损失函数包括交叉熵损失和对比学习损失,用于优化模型参数。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
MCN-CL模型在IEMOCAP和MELD数据集上取得了显著的性能提升。在IEMOCAP数据集上,加权F1分数提高了3.42%,在MELD数据集上,加权F1分数提高了5.73%。这些结果表明,MCN-CL模型能够有效地融合不同模态的信息,并且具有较强的鲁棒性,优于现有的多模态情感识别方法。
🎯 应用场景
该研究成果可应用于心理健康监测,通过分析用户的语音、面部表情和文本信息,自动识别用户的情绪状态,从而提供个性化的心理辅导。此外,还可应用于教育互动领域,帮助教师更好地了解学生的情绪状态,从而调整教学策略。在人机交互领域,该技术可以使机器更好地理解人类的情感,从而实现更自然、更智能的交互。
📄 摘要(原文)
Multimodal emotion recognition plays a key role in many domains, including mental health monitoring, educational interaction, and human-computer interaction. However, existing methods often face three major challenges: unbalanced category distribution, the complexity of dynamic facial action unit time modeling, and the difficulty of feature fusion due to modal heterogeneity. With the explosive growth of multimodal data in social media scenarios, the need for building an efficient cross-modal fusion framework for emotion recognition is becoming increasingly urgent. To this end, this paper proposes Multimodal Cross-Attention Network and Contrastive Learning (MCN-CL) for multimodal emotion recognition. It uses a triple query mechanism and hard negative mining strategy to remove feature redundancy while preserving important emotional cues, effectively addressing the issues of modal heterogeneity and category imbalance. Experiment results on the IEMOCAP and MELD datasets show that our proposed method outperforms state-of-the-art approaches, with Weighted F1 scores improving by 3.42% and 5.73%, respectively.