Visual Spatial Tuning
作者: Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wenqian Wang, Yi Lin, Hengshuang Zhao
分类: cs.CV
发布日期: 2025-11-07
💡 一句话要点
提出视觉空间调优(VST)框架,提升视觉语言模型(VLM)的空间感知和推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 空间感知 空间推理 视觉空间调优 强化学习 数据集构建 多模态学习
📋 核心要点
- 现有方法通常通过添加额外的专家编码器来增强视觉语言模型的空间感知能力,但这会增加额外开销并损害通用能力。
- 本文提出视觉空间调优(VST)框架,通过构建大规模数据集和渐进式训练流程,提升VLM的空间感知和推理能力。
- 实验结果表明,VST在多个空间基准测试上取得了SOTA结果,且没有损害模型的通用能力,为视觉-语言-动作模型带来显著提升。
📝 摘要(中文)
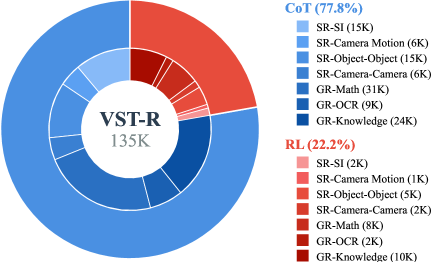
本文提出视觉空间调优(VST)框架,旨在提升视觉语言模型(VLM)中类人视觉空间能力,包括空间感知和推理。为了增强VLM的空间感知能力,构建了一个大规模数据集VST-P,包含410万个样本,覆盖单视角、多图像和视频等19种技能。此外,还提出了VST-R数据集,包含13.5万个样本,用于指导模型进行空间推理。采用渐进式训练流程:首先进行监督微调以构建基础空间知识,然后使用强化学习进一步提高空间推理能力。VST在不损害通用能力的前提下,在多个空间基准测试上取得了最先进的结果,例如在MMSI-Bench上达到34.8%,在VSIBench上达到61.2%。该空间调优范式可以显著增强视觉-语言-动作模型,为更具物理基础的人工智能铺平道路。
🔬 方法详解
问题定义:现有视觉语言模型在理解和推理视觉空间关系方面存在不足,尤其是在复杂场景和多模态输入下。以往方法通常采用增加额外专家编码器的方式,但这种方式会引入额外的计算开销,并且往往会损害模型原有的通用能力。因此,如何有效地提升VLM的空间感知和推理能力,同时保持其通用性,是一个重要的挑战。
核心思路:本文的核心思路是通过数据驱动的方式,利用大规模数据集和特定的训练策略,直接在现有的VLM架构上进行“调优”,从而赋予模型更强的空间感知和推理能力。这种方法避免了引入额外的复杂模块,从而降低了计算成本,并更好地保持了模型的通用性。
技术框架:VST框架主要包含两个阶段:空间感知增强和空间推理增强。首先,利用大规模数据集VST-P(包含单视角、多图像和视频等多种场景)对VLM进行监督微调,使其具备基础的空间感知能力。然后,利用数据集VST-R,采用强化学习方法进一步提升模型的空间推理能力。整个训练流程采用渐进式策略,逐步提升模型的空间智能。
关键创新:VST的关键创新在于其“调优”的思路,即不改变VLM的整体架构,而是通过数据和训练策略来提升其特定能力。此外,VST还构建了两个大规模数据集VST-P和VST-R,分别用于空间感知和空间推理的训练,为VLM的空间能力提升提供了有力的数据支撑。
关键设计:在数据集构建方面,VST-P覆盖了19种不同的空间技能,包括位置、方向、距离、形状等。VST-R则侧重于空间推理,包含多种推理任务,例如路径规划、物体关系推理等。在训练策略方面,采用了监督微调和强化学习相结合的方式,充分利用了两种方法的优势。具体而言,强化学习部分使用了策略梯度算法,并设计了合适的奖励函数,以鼓励模型进行正确的空间推理。
🖼️ 关键图片


📊 实验亮点
VST在多个空间基准测试上取得了显著的性能提升。在MMSI-Bench上,VST达到了34.8%的准确率,相比基线模型有显著提升。在VSIBench上,VST达到了61.2%的准确率,同样取得了SOTA结果。这些实验结果表明,VST能够有效地提升VLM的空间感知和推理能力,且不会损害模型的通用能力。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、智能家居、增强现实等领域。通过提升视觉语言模型的空间感知和推理能力,可以使机器人在复杂环境中更好地理解和交互,从而实现更智能、更安全的应用。
📄 摘要(原文)
Capturing spatial relationships from visual inputs is a cornerstone of human-like general intelligence. Several previous studies have tried to enhance the spatial awareness of Vision-Language Models (VLMs) by adding extra expert encoders, which brings extra overhead and usually harms general capabilities. To enhance the spatial ability in general architectures, we introduce Visual Spatial Tuning (VST), a comprehensive framework to cultivate VLMs with human-like visuospatial abilities, from spatial perception to reasoning. We first attempt to enhance spatial perception in VLMs by constructing a large-scale dataset termed VST-P, which comprises 4.1 million samples spanning 19 skills across single views, multiple images, and videos. Then, we present VST-R, a curated dataset with 135K samples that instruct models to reason in space. In particular, we adopt a progressive training pipeline: supervised fine-tuning to build foundational spatial knowledge, followed by reinforcement learning to further improve spatial reasoning abilities. Without the side-effect to general capabilities, the proposed VST consistently achieves state-of-the-art results on several spatial benchmarks, including $34.8\%$ on MMSI-Bench and $61.2\%$ on VSIBench. It turns out that the Vision-Language-Action models can be significantly enhanced with the proposed spatial tuning paradigm, paving the way for more physically grounded AI.