TimeSearch-R: Adaptive Temporal Search for Long-Form Video Understanding via Self-Verification Reinforcement Learning
作者: Junwen Pan, Qizhe Zhang, Rui Zhang, Ming Lu, Xin Wan, Yuan Zhang, Chang Liu, Qi She
分类: cs.CV, cs.AI
发布日期: 2025-11-07
备注: 22 pages, 17 figures. Official code: https://github.com/Time-Search/TimeSearch-R
🔗 代码/项目: GITHUB
💡 一句话要点
提出TimeSearch-R,通过自验证强化学习进行长视频理解的自适应时序搜索。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 长视频理解 时序搜索 强化学习 自验证 文本-视频推理
📋 核心要点
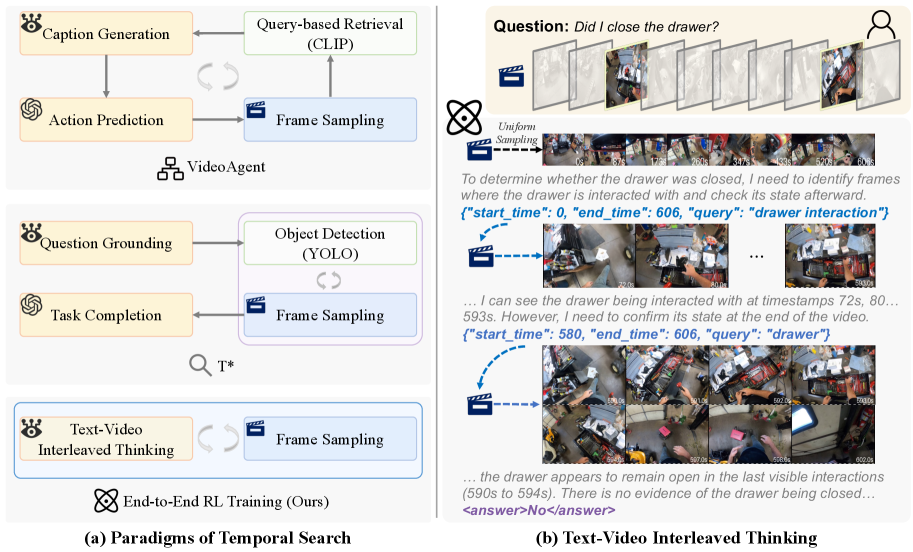
- 现有长视频理解的时序搜索方法依赖手工设计的搜索过程,缺乏端到端优化,难以学习最优搜索策略。
- TimeSearch-R将时序搜索重构为交错的文本-视频思考,通过强化学习将视频片段搜索融入推理过程。
- TimeSearch-R在多个长视频理解基准测试中取得了显著提升,并在LongVideoBench上刷新了SOTA。
📝 摘要(中文)
时序搜索旨在根据给定的查询,从成千上万的帧中识别出最小的相关帧集合,这是准确理解长视频的基础。现有方法试图逐步缩小搜索空间,但通常依赖于手工设计的搜索过程,缺乏端到端优化来学习最佳搜索策略。本文提出了TimeSearch-R,它将时序搜索重新定义为交错的文本-视频思考,通过强化学习(RL)将搜索视频片段无缝集成到推理过程中。然而,将RL训练方法(如GRPO)应用于视频推理可能导致无监督的中间搜索决策,从而导致视频内容探索不足和逻辑推理不一致。为了解决这些问题,我们引入了带有完整性自验证的GRPO(GRPO-CSV),它收集来自交错推理过程的搜索视频帧,并利用相同的策略模型来验证搜索帧的充分性,从而提高视频推理的完整性。此外,我们构建了专门为GRPO-CSV的SFT冷启动和RL训练设计的数据集,过滤掉具有弱时序依赖性的样本,以提高任务难度并提升时序搜索能力。大量实验表明,TimeSearch-R在Haystack-LVBench和Haystack-Ego4D等时序搜索基准,以及VideoMME和MLVU等长视频理解基准上取得了显著的改进。值得注意的是,TimeSearch-R在LongVideoBench上建立了新的state-of-the-art,比基础模型Qwen2.5-VL提高了4.1%,比先进的视频推理模型Video-R1提高了2.0%。
🔬 方法详解
问题定义:论文旨在解决长视频理解中时序搜索效率和准确性的问题。现有方法依赖于手工设计的搜索策略,缺乏端到端的优化,导致搜索效率低下,并且难以捕捉视频中的关键信息。这些方法无法充分利用视频内容进行推理,限制了长视频理解的性能。
核心思路:论文的核心思路是将时序搜索建模为一个交错的文本-视频思考过程,并利用强化学习来优化搜索策略。通过将视频片段的搜索集成到推理过程中,模型可以根据当前的推理状态动态地调整搜索策略,从而更有效地找到与查询相关的视频帧。
技术框架:TimeSearch-R的整体框架包含以下几个主要模块:1) 视频编码器:用于提取视频帧的特征表示。2) 文本编码器:用于提取查询文本的特征表示。3) 策略网络:用于根据当前的文本和视频特征,决定下一步要搜索的视频片段。4) 奖励函数:用于评估搜索到的视频片段与查询的相关性,并指导策略网络的训练。5) GRPO-CSV:一种改进的强化学习训练方法,用于提高搜索的完整性和一致性。模型通过交错的文本-视频推理过程,逐步缩小搜索范围,最终找到与查询最相关的视频帧。
关键创新:论文的关键创新在于提出了GRPO-CSV,一种带有完整性自验证的Group Relative Policy Optimization方法。该方法通过收集搜索到的视频帧,并利用相同的策略模型来验证搜索帧的充分性,从而提高视频推理的完整性。这解决了传统强化学习方法在视频推理中可能出现的无监督中间搜索决策问题,避免了视频内容探索不足和逻辑推理不一致的情况。
关键设计:论文设计了专门用于SFT冷启动和RL训练的数据集,过滤掉具有弱时序依赖性的样本,以提高任务难度并提升时序搜索能力。奖励函数的设计考虑了搜索到的视频片段与查询的相关性,以及搜索过程的效率。策略网络采用Transformer结构,可以有效地捕捉文本和视频之间的关系。GRPO-CSV通过引入自验证机制,提高了强化学习训练的稳定性和效率。
🖼️ 关键图片


📊 实验亮点
TimeSearch-R在Haystack-LVBench和Haystack-Ego4D等时序搜索基准,以及VideoMME和MLVU等长视频理解基准上取得了显著的改进。在LongVideoBench上,TimeSearch-R比基础模型Qwen2.5-VL提高了4.1%,比先进的视频推理模型Video-R1提高了2.0%,建立了新的state-of-the-art。
🎯 应用场景
TimeSearch-R可应用于各种长视频理解任务,例如视频问答、视频摘要、视频检索等。该技术可以帮助用户快速找到视频中的关键信息,提高信息获取效率。在智能监控、自动驾驶等领域也有潜在应用价值,可以帮助系统更好地理解和分析视频内容。
📄 摘要(原文)
Temporal search aims to identify a minimal set of relevant frames from tens of thousands based on a given query, serving as a foundation for accurate long-form video understanding. Existing works attempt to progressively narrow the search space. However, these approaches typically rely on a hand-crafted search process, lacking end-to-end optimization for learning optimal search strategies. In this paper, we propose TimeSearch-R, which reformulates temporal search as interleaved text-video thinking, seamlessly integrating searching video clips into the reasoning process through reinforcement learning (RL). However, applying RL training methods, such as Group Relative Policy Optimization (GRPO), to video reasoning can result in unsupervised intermediate search decisions. This leads to insufficient exploration of the video content and inconsistent logical reasoning. To address these issues, we introduce GRPO with Completeness Self-Verification (GRPO-CSV), which gathers searched video frames from the interleaved reasoning process and utilizes the same policy model to verify the adequacy of searched frames, thereby improving the completeness of video reasoning. Additionally, we construct datasets specifically designed for the SFT cold-start and RL training of GRPO-CSV, filtering out samples with weak temporal dependencies to enhance task difficulty and improve temporal search capabilities. Extensive experiments demonstrate that TimeSearch-R achieves significant improvements on temporal search benchmarks such as Haystack-LVBench and Haystack-Ego4D, as well as long-form video understanding benchmarks like VideoMME and MLVU. Notably, TimeSearch-R establishes a new state-of-the-art on LongVideoBench with 4.1% improvement over the base model Qwen2.5-VL and 2.0% over the advanced video reasoning model Video-R1. Our code is available at https://github.com/Time-Search/TimeSearch-R.