$\mathbf{S^2LM}$: Towards Semantic Steganography via Large Language Models
作者: Huanqi Wu, Huangbiao Xu, Runfeng Xie, Jiaxin Cai, Kaixin Zhang, Xiao Ke
分类: cs.CV, cs.CR
发布日期: 2025-11-07 (更新: 2026-01-07)
备注: 30 Pages, 24 Figures
💡 一句话要点
提出S^2LM,利用大语言模型实现图像语义隐写,突破传统比特级限制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义隐写 大语言模型 信息隐藏 图像隐写 自然语言处理
📋 核心要点
- 现有隐写术难以嵌入语义丰富的句子级信息,限制了信息隐藏的表达能力。
- S^2LM利用大语言模型,将句子级语义信息编码到图像中,实现句子级别的隐写和恢复。
- 实验表明,S^2LM能够有效恢复隐藏的句子,超越了传统比特级隐写方法的限制。
📝 摘要(中文)
本文提出了一种新的语义隐写概念,旨在将语义丰富的句子级信息嵌入到载体中。以句子到图像的隐写为例,提出了语义隐写语言模型S^2LM,该模型利用大型语言模型(LLM)将高层文本信息嵌入到图像中。与传统的比特级方法不同,S^2LM重新设计了整个流程,在整个过程中利用LLM来实现任意句子的隐藏和恢复。此外,建立了一个名为Invisible Text (IVT)的基准,其中包含各种句子级文本作为秘密消息,以评估语义隐写方法。实验结果表明,S^2LM有效地实现了超越比特级隐写的直接句子恢复。
🔬 方法详解
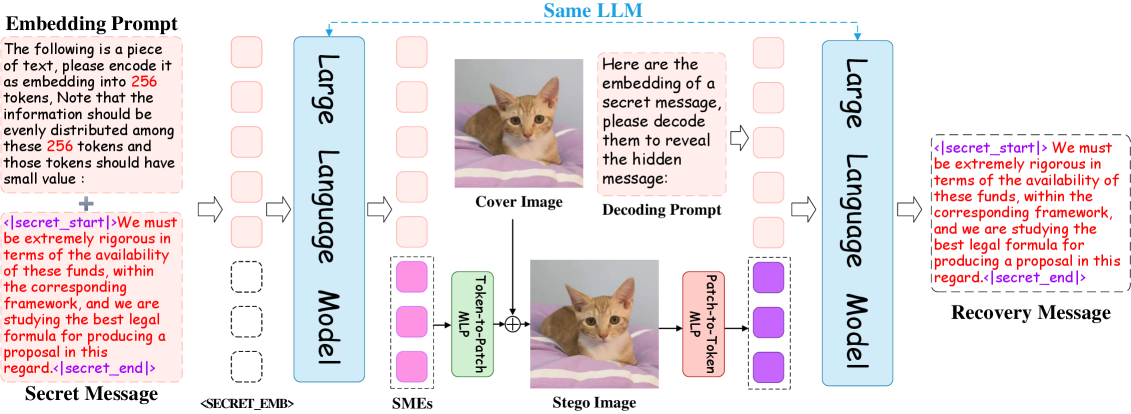
问题定义:现有隐写术主要集中在比特级别的信息隐藏,难以直接嵌入和恢复具有复杂语义的句子或段落。传统方法的痛点在于信息容量小,且难以保证隐藏信息的语义完整性和可理解性。
核心思路:S^2LM的核心在于利用大语言模型(LLM)的强大语义理解和生成能力,将句子级别的文本信息转化为图像中的某种表示,从而实现语义隐写。通过LLM,可以将文本的语义信息编码成一种不易察觉的图像特征,并在需要时解码恢复。
技术框架:S^2LM的整体框架包含以下几个主要阶段:1) 句子编码:使用LLM将输入的句子编码成一个语义向量。2) 图像嵌入:将语义向量嵌入到载体图像中,通过某种方式修改图像的像素值或特征,使得嵌入的信息不易被察觉。3) 图像提取:从嵌入信息的图像中提取出语义向量。4) 句子解码:使用LLM将提取出的语义向量解码成原始句子。整个流程依赖于LLM的编码和解码能力,以及图像嵌入和提取技术。
关键创新:S^2LM最重要的创新点在于将LLM引入到隐写术中,实现了语义级别的隐写,突破了传统比特级隐写的限制。与现有方法相比,S^2LM能够直接隐藏和恢复句子级别的文本信息,而不需要将其转换为比特流。
关键设计:具体的技术细节包括:1) 使用特定的LLM架构(例如Transformer)进行句子编码和解码。2) 设计合适的图像嵌入和提取方法,例如使用可逆神经网络或对抗训练来保证图像质量和信息隐藏的安全性。3) 损失函数的设计需要考虑图像质量、信息隐藏容量和恢复准确率等因素。4) 针对不同的LLM和图像嵌入方法,需要调整超参数以达到最佳性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,S^2LM能够有效地将句子嵌入到图像中,并成功恢复原始句子。与传统的比特级隐写方法相比,S^2LM在信息容量和语义表达能力方面具有显著优势。论文还建立了一个新的基准数据集IVT,用于评估语义隐写方法的性能。
🎯 应用场景
S^2LM具有广泛的应用前景,例如在安全通信中隐藏敏感信息,在数字版权保护中嵌入版权声明,以及在图像取证中隐藏身份信息。该技术可以用于保护个人隐私,防止信息泄露,并为数字内容的安全提供更高级别的保障。未来,该技术可以进一步扩展到视频、音频等其他媒体形式。
📄 摘要(原文)
Despite remarkable progress in steganography, embedding semantically rich, sentence-level information into carriers remains a challenging problem. In this work, we present a novel concept of Semantic Steganography, which aims to hide semantically meaningful and structured content, such as sentences or paragraphs, in cover media. Based on this concept, we present Sentence-to-Image Steganography as an instance that enables the hiding of arbitrary sentence-level messages within a cover image. To accomplish this feat, we propose S^2LM: Semantic Steganographic Language Model, which leverages large language models (LLMs) to embed high-level textual information into images. Unlike traditional bit-level approaches, S^2LM redesigns the entire pipeline, involving the LLM throughout the process to enable the hiding and recovery of arbitrary sentences. Furthermore, we establish a benchmark named Invisible Text (IVT), comprising a diverse set of sentence-level texts as secret messages to evaluate semantic steganography methods. Experimental results demonstrate that S^2LM effectively enables direct sentence recovery beyond bit-level steganography. The source code and IVT dataset will be released soon.