LiveStar: Live Streaming Assistant for Real-World Online Video Understanding
作者: Zhenyu Yang, Kairui Zhang, Yuhang Hu, Bing Wang, Shengsheng Qian, Bin Wen, Fan Yang, Tingting Gao, Weiming Dong, Changsheng Xu
分类: cs.CV, cs.AI
发布日期: 2025-11-07
备注: NeurIPS 2025 Accepted
🔗 代码/项目: GITHUB
💡 一句话要点
LiveStar:通过自适应流解码实现实时在线视频理解的直播助手
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线视频理解 实时流媒体 视频大语言模型 自适应流解码 增量式学习
📋 核心要点
- 现有在线Video-LLM难以兼顾连续帧处理和最佳响应时机,导致实时性和叙事连贯性受损。
- LiveStar通过自适应流解码实现主动响应,利用增量式视频-语言对齐和响应-静默解码框架。
- 实验表明,LiveStar在语义正确性、时间差异和FPS方面均优于现有方法,并在OmniStar数据集上进行了验证。
📝 摘要(中文)
本文提出LiveStar,一种开创性的直播助手,通过自适应流解码实现始终在线的主动响应,解决了现有在线Video-LLM在处理连续帧输入和确定最佳响应时机方面的局限性。LiveStar包含:(1)一种训练策略,能够对变长视频流进行增量式的视频-语言对齐,保持动态演进的帧序列之间的时间一致性;(2)一个响应-静默解码框架,通过单次前向验证确定最佳的主动响应时机;(3)通过峰终记忆压缩进行在线推理的内存感知加速,用于10分钟以上的视频,结合流式键值缓存,实现1.53倍的推理加速。此外,构建了一个OmniStar数据集,这是一个全面的数据集,用于训练和基准测试,包含15个不同的真实场景和5个在线视频理解的评估任务。广泛的实验表明,LiveStar具有最先进的性能,在语义正确性方面平均提高了19.5%,与现有的在线Video-LLM相比,时间差异减少了18.1%,同时在所有五个OmniStar任务中,FPS提高了12.0%。
🔬 方法详解
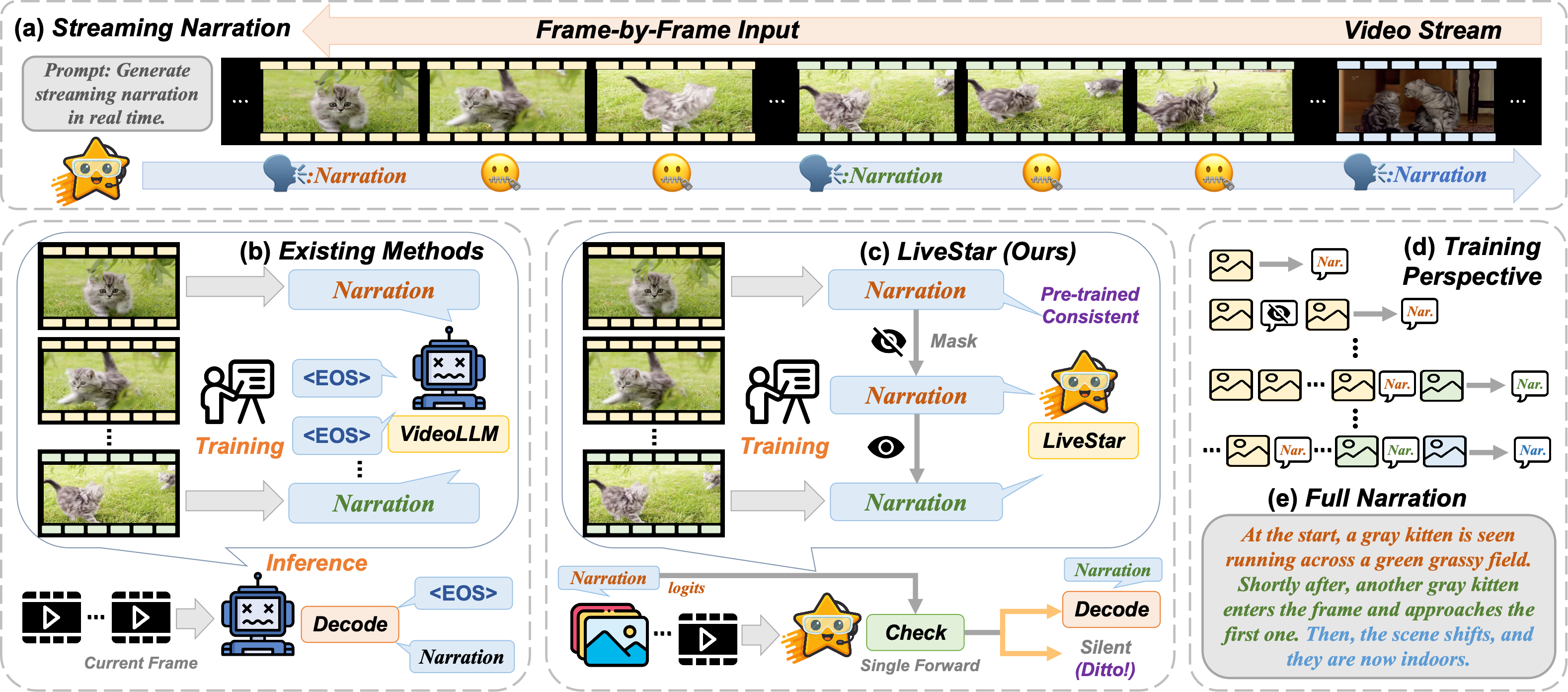
问题定义:现有在线视频理解模型难以同时处理连续的视频帧输入,并准确判断最佳的响应时机。这导致模型在实时性和保持叙事连贯性方面表现不佳。现有的Video-LLM通常针对离线视频进行优化,无法直接应用于实时流媒体场景。
核心思路:LiveStar的核心思路是通过自适应流解码,实现对实时视频流的增量式理解和响应。模型通过学习变长视频流的视频-语言对齐,并利用响应-静默解码框架来确定最佳的响应时机。这种设计使得模型能够在保证实时性的前提下,提供语义上正确且时间上合理的响应。
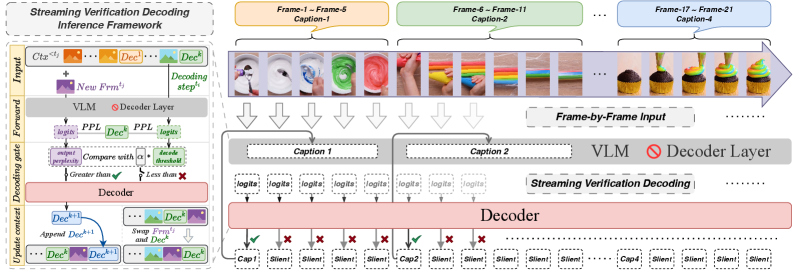
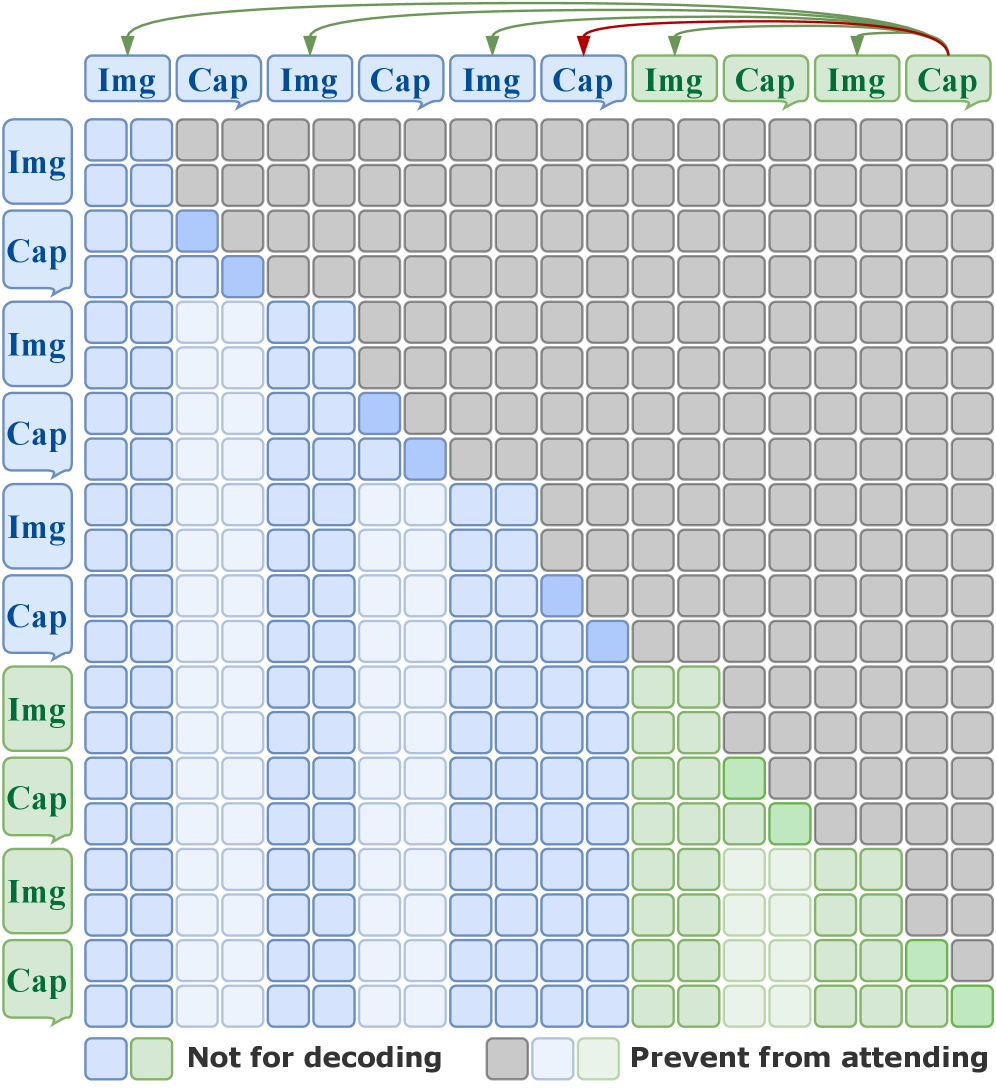
技术框架:LiveStar的整体框架包括三个主要组成部分:增量式视频-语言对齐训练策略、响应-静默解码框架和内存感知加速模块。首先,使用增量式训练策略对模型进行训练,使其能够处理变长的视频流。然后,利用响应-静默解码框架,通过单次前向验证确定最佳的响应时机。最后,使用内存感知加速模块,包括峰终记忆压缩和流式键值缓存,来提高在线推理的效率。
关键创新:LiveStar的关键创新在于其能够实现始终在线的主动响应,而无需等待整个视频片段处理完毕。这得益于其增量式训练策略和响应-静默解码框架,使得模型能够在处理视频流的同时,预测最佳的响应时机。此外,内存感知加速模块也显著提高了模型的推理速度。
关键设计:增量式训练策略允许模型逐步学习视频和语言之间的对应关系,而无需一次性处理整个视频。响应-静默解码框架通过预测一个“静默”信号来判断何时不应该进行响应,从而避免不必要的干扰。峰终记忆压缩通过保留视频的关键帧信息,减少了内存占用。流式键值缓存则通过缓存中间计算结果,加速了推理过程。
🖼️ 关键图片
📊 实验亮点
LiveStar在三个基准测试中均取得了最先进的性能。在OmniStar数据集上,LiveStar在语义正确性方面平均提高了19.5%,时间差异减少了18.1%,同时FPS提高了12.0%。这些结果表明,LiveStar在实时性和准确性方面均优于现有的在线Video-LLM。
🎯 应用场景
LiveStar可应用于多种实时视频理解场景,如直播辅助、智能监控、远程协作等。例如,在直播场景中,LiveStar可以实时分析主播的内容,并提供智能提示或自动生成字幕。在智能监控场景中,LiveStar可以实时检测异常事件,并及时发出警报。该研究的实际价值在于提高了在线视频理解的效率和准确性,未来有望推动更多基于实时视频的应用。
📄 摘要(原文)
Despite significant progress in Video Large Language Models (Video-LLMs) for offline video understanding, existing online Video-LLMs typically struggle to simultaneously process continuous frame-by-frame inputs and determine optimal response timing, often compromising real-time responsiveness and narrative coherence. To address these limitations, we introduce LiveStar, a pioneering live streaming assistant that achieves always-on proactive responses through adaptive streaming decoding. Specifically, LiveStar incorporates: (1) a training strategy enabling incremental video-language alignment for variable-length video streams, preserving temporal consistency across dynamically evolving frame sequences; (2) a response-silence decoding framework that determines optimal proactive response timing via a single forward pass verification; (3) memory-aware acceleration via peak-end memory compression for online inference on 10+ minute videos, combined with streaming key-value cache to achieve 1.53x faster inference. We also construct an OmniStar dataset, a comprehensive dataset for training and benchmarking that encompasses 15 diverse real-world scenarios and 5 evaluation tasks for online video understanding. Extensive experiments across three benchmarks demonstrate LiveStar's state-of-the-art performance, achieving an average 19.5% improvement in semantic correctness with 18.1% reduced timing difference compared to existing online Video-LLMs, while improving FPS by 12.0% across all five OmniStar tasks. Our model and dataset can be accessed at https://github.com/yzy-bupt/LiveStar.