Cross-domain EEG-based Emotion Recognition with Contrastive Learning
作者: Rui Yan, Yibo Li, Han Ding, Fei Wang
分类: cs.CV
发布日期: 2025-11-07 (更新: 2026-01-25)
备注: Accepted by IEEE ICASSP 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出EmotionCLIP以解决跨域EEG情感识别问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: EEG情感识别 对比学习 多模态学习 跨域泛化 深度学习
📋 核心要点
- 现有EEG情感识别方法在特征利用和跨域泛化方面存在显著挑战,导致识别准确率不高。
- 本研究提出EmotionCLIP,通过将情感识别转化为EEG与文本的匹配任务,利用对比学习提升模型性能。
- 在SEED和SEED-IV数据集上,EmotionCLIP实现了显著的性能提升,跨主体和跨时间的准确率均超过了88%。
📝 摘要(中文)
基于脑电图(EEG)的情感识别在情感计算中至关重要,但面临特征利用和跨域泛化的挑战。本研究提出EmotionCLIP,将情感识别重新定义为EEG与文本匹配任务,基于CLIP框架。采用定制的骨干网络SST-LegoViT,通过多尺度卷积和Transformer模块捕捉空间、频谱和时间特征。实验结果显示,在SEED和SEED-IV数据集上,跨主体准确率分别达到88.69%和73.50%,跨时间准确率达到88.46%和77.54%,超越现有模型,证明了多模态对比学习在EEG情感识别中的有效性。代码可在https://github.com/Departure2021/EmotionCLIP获取。
🔬 方法详解
问题定义:本研究旨在解决基于EEG的情感识别中的特征利用不足和跨域泛化能力差的问题。现有方法往往无法有效利用EEG信号的多维特征,导致情感识别的准确性受到限制。
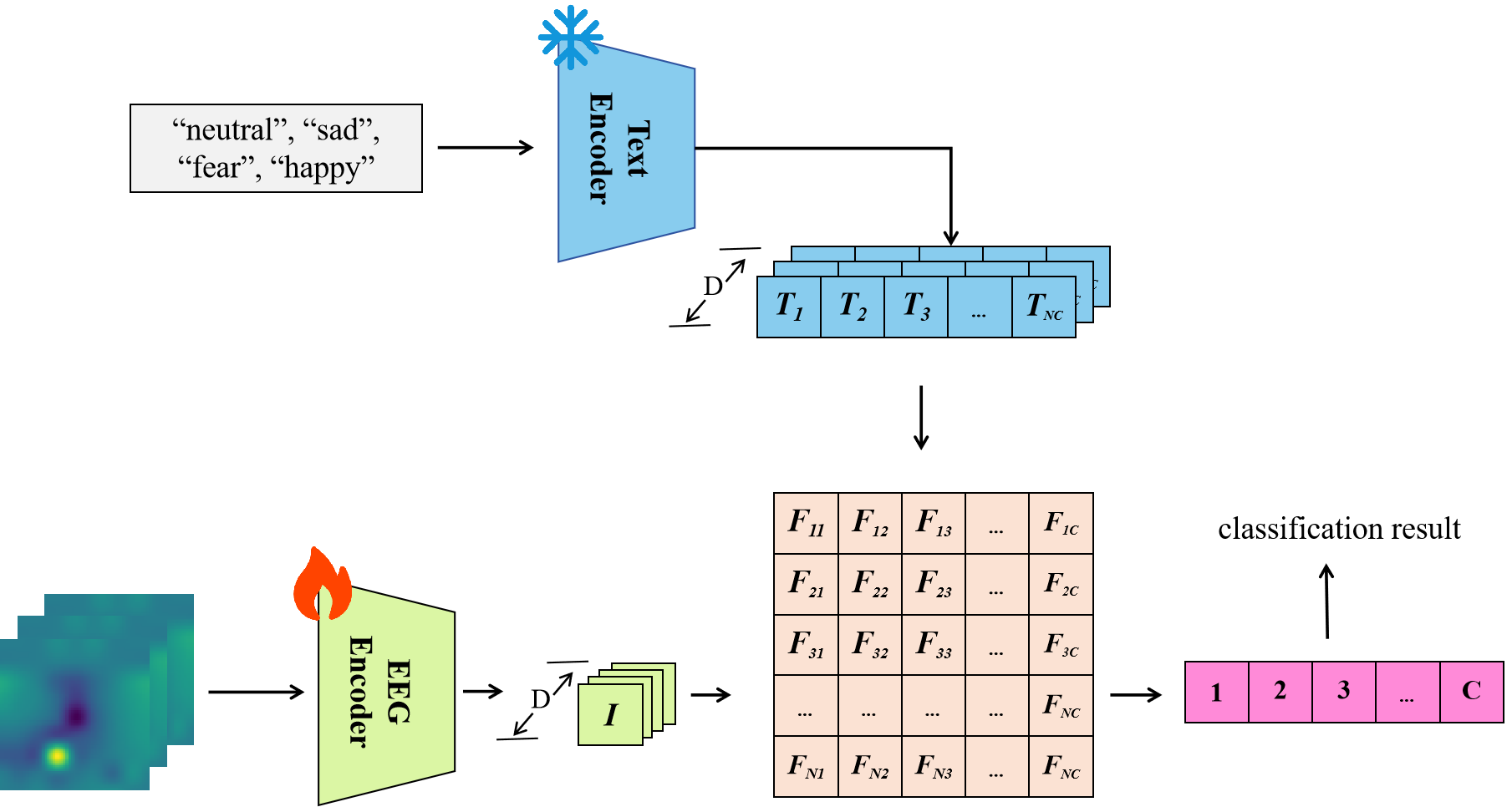
核心思路:论文的核心思路是将情感识别任务重新定义为EEG与文本的匹配任务,利用CLIP框架中的对比学习机制,以增强模型对不同域的适应能力。通过这种方式,模型能够更好地捕捉EEG信号与情感之间的关系。
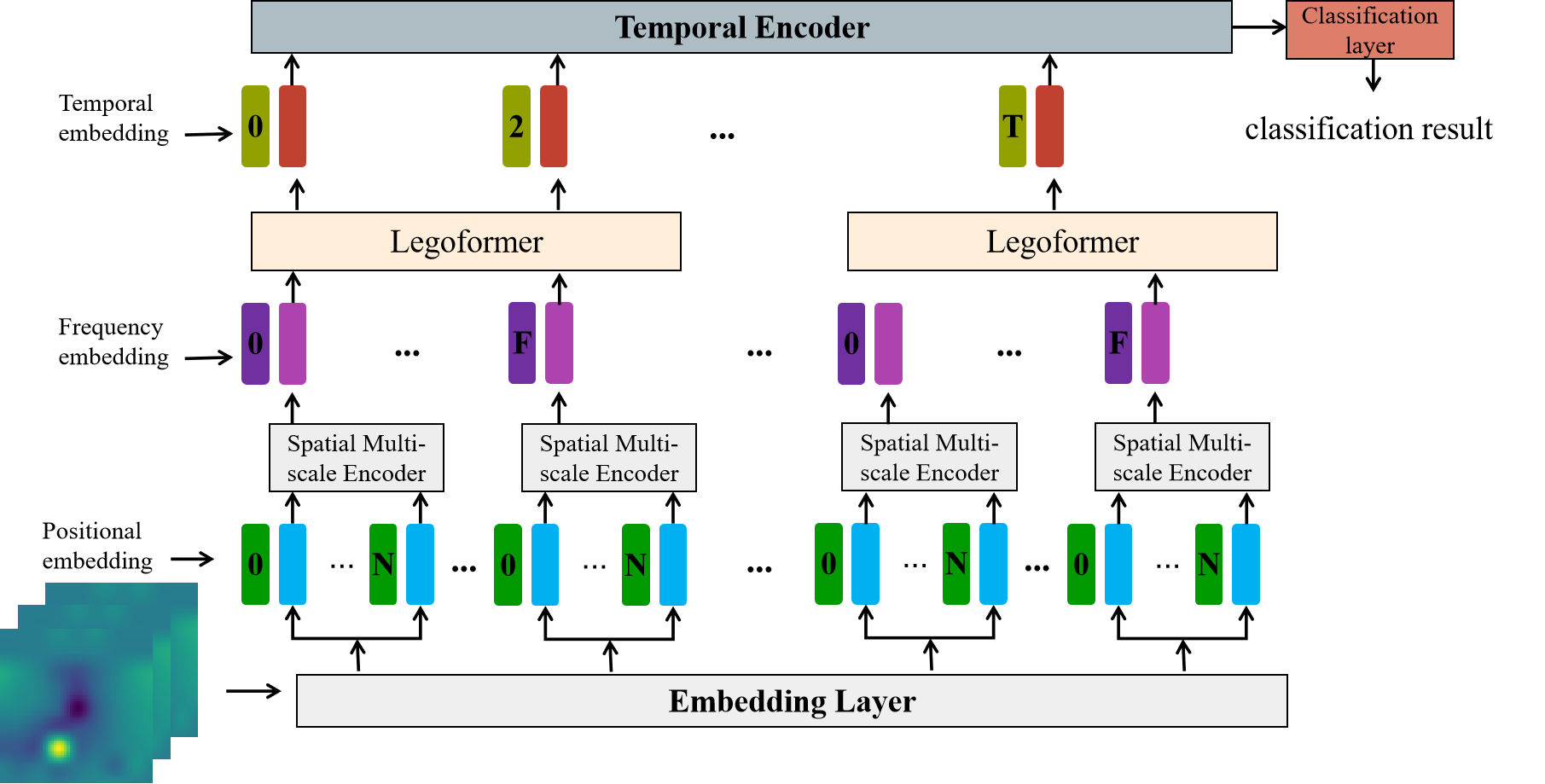
技术框架:整体架构包括一个定制的骨干网络SST-LegoViT,该网络结合了多尺度卷积和Transformer模块,能够有效提取EEG信号的空间、频谱和时间特征。模型的训练过程采用对比学习策略,优化EEG与文本之间的匹配度。
关键创新:最重要的技术创新在于将情感识别任务转化为对比学习框架下的匹配任务,这一方法显著提高了跨域情感识别的准确性,与传统方法相比具有本质上的区别。
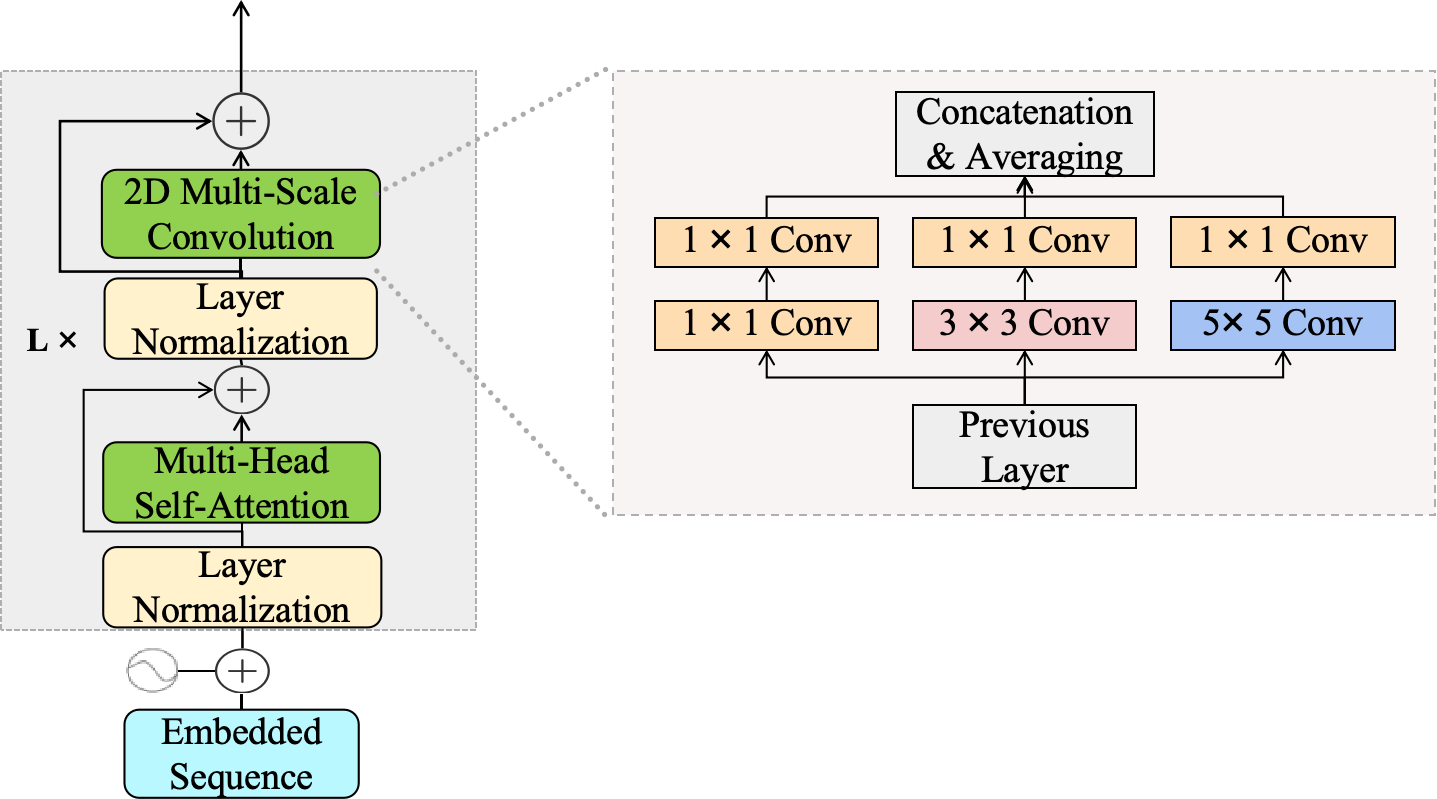
关键设计:在网络设计上,SST-LegoViT采用了多尺度卷积层以捕捉不同频段的特征,同时引入Transformer模块以增强时间序列特征的建模能力。损失函数设计为对比损失,旨在最大化正样本对的相似度,同时最小化负样本对的相似度。实验中还进行了超参数调优,以确保模型性能的最优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EmotionCLIP在SEED和SEED-IV数据集上实现了跨主体准确率分别为88.69%和73.50%,跨时间准确率为88.46%和77.54%。这些结果显著优于现有模型,验证了多模态对比学习在EEG情感识别中的有效性和鲁棒性。
🎯 应用场景
该研究的潜在应用领域包括情感计算、心理健康监测和人机交互等。通过提高EEG情感识别的准确性,EmotionCLIP能够为情感分析提供更可靠的工具,促进智能系统在情感理解方面的进步,未来可能在医疗、教育和娱乐等多个领域产生深远影响。
📄 摘要(原文)
Electroencephalogram (EEG)-based emotion recognition is vital for affective computing but faces challenges in feature utilization and cross-domain generalization. This work introduces EmotionCLIP, which reformulates recognition as an EEG-text matching task within the CLIP framework. A tailored backbone, SST-LegoViT, captures spatial, spectral, and temporal features using multi-scale convolution and Transformer modules. Experiments on SEED and SEED-IV datasets show superior cross-subject accuracies of 88.69\% and 73.50\%, and cross-time accuracies of 88.46\% and 77.54\%, outperforming existing models. Results demonstrate the effectiveness of multimodal contrastive learning for robust EEG emotion recognition. The code is available at https://github.com/Departure2021/EmotionCLIP.