DeepEyesV2: Toward Agentic Multimodal Model
作者: Jack Hong, Chenxiao Zhao, ChengLin Zhu, Weiheng Lu, Guohai Xu, Xing Yu
分类: cs.CV, cs.AI
发布日期: 2025-11-07 (更新: 2025-11-10)
备注: Homepage: https://visual-agent.github.io/
💡 一句话要点
DeepEyesV2:面向具身智能的多模态模型,提升工具调用能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 多模态模型 工具调用 强化学习 两阶段训练 RealX-Bench 任务自适应
📋 核心要点
- 现有具身多模态模型在工具使用方面存在鲁棒性不足的问题,难以有效整合外部工具进行复杂推理。
- DeepEyesV2通过两阶段训练流程,首先建立工具使用模式,然后通过强化学习优化工具调用,提升模型性能。
- DeepEyesV2在RealX-Bench等基准测试中表现出色,展示了其在真实世界理解、数学推理和搜索任务中的有效性。
📝 摘要(中文)
具身多模态模型不仅应理解文本和图像,还应主动调用外部工具(如代码执行环境和网络搜索),并将这些操作整合到推理中。本文介绍了DeepEyesV2,并从数据构建、训练方法和模型评估的角度探讨如何构建具身多模态模型。研究发现,直接强化学习难以诱导稳健的工具使用行为。因此,提出了一个两阶段训练流程:冷启动阶段建立工具使用模式,强化学习阶段进一步优化工具调用。构建了一个多样化的、具有一定挑战性的训练数据集,特别包括工具使用有益的示例。此外,引入了RealX-Bench,这是一个综合性的基准,旨在评估真实世界的多模态推理,这内在需要整合多种能力,包括感知、搜索和推理。在RealX-Bench和其他代表性基准上评估了DeepEyesV2,证明了其在真实世界理解、数学推理和搜索密集型任务中的有效性。此外,DeepEyesV2表现出任务自适应的工具调用,倾向于使用图像操作进行感知任务,使用数值计算进行推理任务。强化学习进一步实现了复杂的工具组合,并允许模型根据上下文选择性地调用工具。希望这项研究能为社区开发具身多模态模型提供指导。
🔬 方法详解
问题定义:现有具身多模态模型在复杂推理任务中,难以有效利用外部工具,例如代码执行环境和网络搜索。直接使用强化学习训练工具调用策略,往往难以收敛到理想的工具使用模式,导致模型鲁棒性较差。现有方法缺乏针对性的数据和训练策略,难以应对真实世界的多模态推理挑战。
核心思路:DeepEyesV2的核心思路是采用两阶段训练方法,首先通过“冷启动”阶段预训练模型,使其初步掌握工具的使用模式,然后利用强化学习进一步优化工具调用策略。这种方法旨在解决直接强化学习难以诱导稳健工具使用行为的问题,从而提升模型在复杂任务中的性能。
技术框架:DeepEyesV2的整体框架包含数据构建、两阶段训练和模型评估三个主要部分。数据构建阶段,作者构建了一个多样化的训练数据集,包含工具使用有益的示例。两阶段训练包括:1) 冷启动阶段,使用监督学习训练模型,使其初步掌握工具的使用模式;2) 强化学习阶段,使用强化学习算法(具体算法未知)进一步优化工具调用策略。模型评估阶段,使用RealX-Bench和其他基准测试评估模型性能。
关键创新:DeepEyesV2的关键创新在于其两阶段训练方法,该方法有效解决了直接强化学习在训练具身多模态模型时遇到的困难。通过冷启动阶段预训练模型,为后续的强化学习提供了一个良好的起点,从而提高了训练效率和模型性能。此外,RealX-Bench基准测试的引入,为评估真实世界的多模态推理能力提供了一个更全面的平台。
关键设计:论文中关于冷启动阶段和强化学习阶段的具体算法细节、损失函数设计、网络结构等信息未知。但是,强调了数据集的多样性,以及包含工具使用有益的示例。此外,模型能够根据任务类型自适应地选择工具,例如使用图像操作进行感知任务,使用数值计算进行推理任务。
🖼️ 关键图片
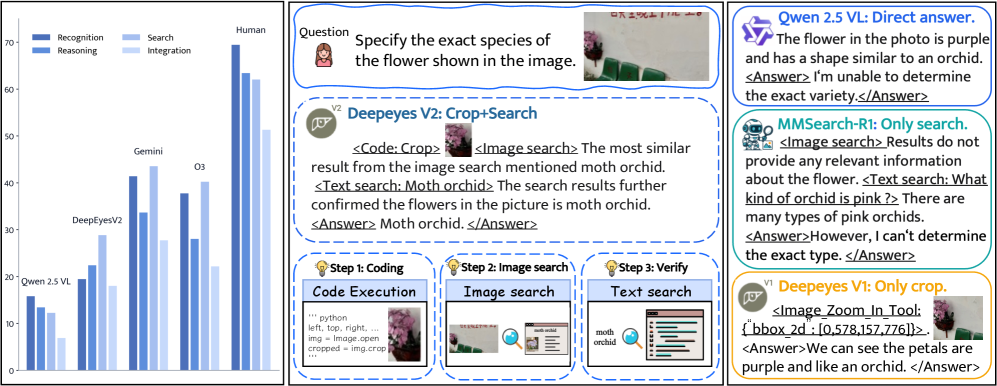
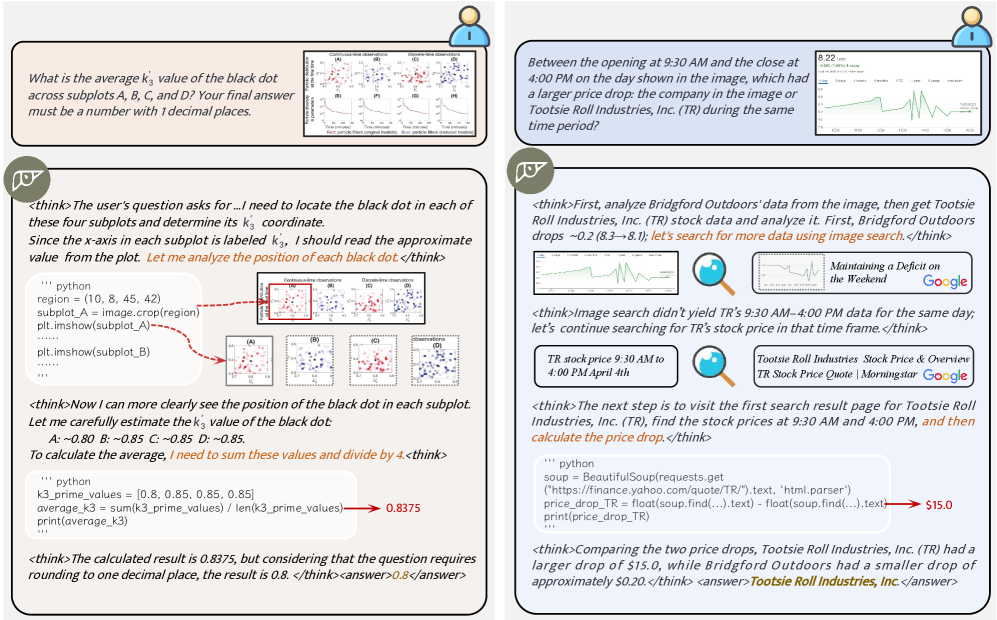

📊 实验亮点
DeepEyesV2在RealX-Bench等基准测试中表现出色,证明了其在真实世界理解、数学推理和搜索密集型任务中的有效性。模型能够根据任务类型自适应地选择工具,并能通过强化学习实现复杂的工具组合。具体的性能数据和提升幅度在摘要中未明确给出,需要在论文正文中查找。
🎯 应用场景
DeepEyesV2具有广泛的应用前景,例如智能助手、自动化报告生成、科学研究辅助等。它可以帮助用户更高效地完成需要多模态信息处理和工具使用的任务。未来,该研究可以进一步扩展到机器人控制、自动驾驶等领域,实现更智能化的决策和操作。
📄 摘要(原文)
Agentic multimodal models should not only comprehend text and images, but also actively invoke external tools, such as code execution environments and web search, and integrate these operations into reasoning. In this work, we introduce DeepEyesV2 and explore how to build an agentic multimodal model from the perspectives of data construction, training methods, and model evaluation. We observe that direct reinforcement learning alone fails to induce robust tool-use behavior. This phenomenon motivates a two-stage training pipeline: a cold-start stage to establish tool-use patterns, and reinforcement learning stage to further refine tool invocation. We curate a diverse, moderately challenging training dataset, specifically including examples where tool use is beneficial. We further introduce RealX-Bench, a comprehensive benchmark designed to evaluate real-world multimodal reasoning, which inherently requires the integration of multiple capabilities, including perception, search, and reasoning. We evaluate DeepEyesV2 on RealX-Bench and other representative benchmarks, demonstrating its effectiveness across real-world understanding, mathematical reasoning, and search-intensive tasks. Moreover, DeepEyesV2 exhibits task-adaptive tool invocation, tending to use image operations for perception tasks and numerical computations for reasoning tasks. Reinforcement learning further enables complex tool combinations and allows model to selectively invoke tools based on context. We hope our study can provide guidance for community in developing agentic multimodal models.