4D3R: Motion-Aware Neural Reconstruction and Rendering of Dynamic Scenes from Monocular Videos
作者: Mengqi Guo, Bo Xu, Yanyan Li, Gim Hee Lee
分类: cs.CV, cs.AI
发布日期: 2025-11-07
备注: 17 pages, 5 figures
期刊: NeurIPS 2025
💡 一句话要点
4D3R:提出运动感知神经重建与渲染框架,解决单目视频动态场景的新视角合成问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经渲染 动态场景重建 新视角合成 高斯溅射 运动感知 单目视频 相机姿态估计
📋 核心要点
- 现有方法在处理单目视频动态场景的新视角合成时,难以同时处理动态内容和未知的相机姿态。
- 4D3R通过两阶段方法解耦静态和动态组件,并提出运动感知捆绑调整和运动感知高斯溅射两种关键技术。
- 实验表明,4D3R在真实动态数据集上显著优于现有方法,尤其是在处理大型动态对象时,且计算效率更高。
📝 摘要(中文)
本文提出了一种名为4D3R的无姿态动态神经渲染框架,用于从单目视频中合成动态场景的新视角。该方法通过两阶段方法解耦静态和动态组件。首先,利用3D基础模型进行初始姿态和几何估计,然后进行运动感知细化。4D3R引入了两项关键技术创新:(1)运动感知捆绑调整(MA-BA)模块,结合基于Transformer的学习先验和SAM2,实现鲁棒的动态对象分割,从而更准确地细化相机姿态;(2)高效的运动感知高斯溅射(MA-GS)表示,使用带有变形场MLP和线性混合蒙皮的控制点来建模动态运动,在保持高质量重建的同时显著降低了计算成本。在真实动态数据集上的大量实验表明,我们的方法比最先进的方法实现了高达1.8dB PSNR的改进,尤其是在具有大型动态对象的具有挑战性的场景中,同时与以前的动态场景表示相比,计算需求降低了5倍。
🔬 方法详解
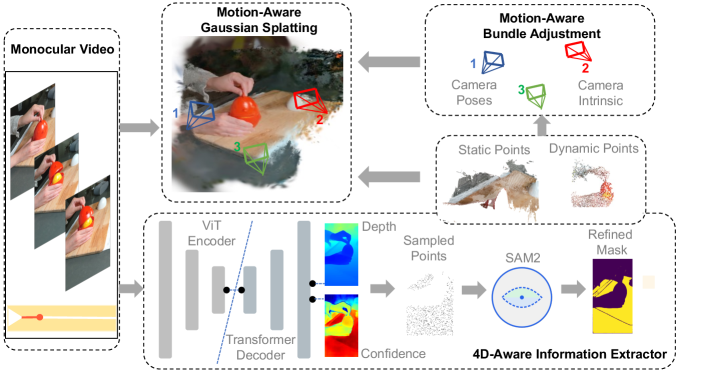
问题定义:论文旨在解决从单目视频中进行动态场景的新视角合成问题,尤其是在相机姿态未知的情况下。现有的NeRF和3DGS方法在静态场景中表现良好,但在处理动态内容时效果不佳,并且通常依赖于预先计算的相机姿态。因此,如何有效地表示和渲染动态场景,同时估计准确的相机姿态,是本研究要解决的核心问题。
核心思路:论文的核心思路是将动态场景分解为静态和动态两部分,并分别进行处理。首先利用3D基础模型进行初始姿态和几何估计,然后通过运动感知的细化模块来优化相机姿态和动态物体的运动。这种解耦的方法能够更好地处理复杂的动态场景,并提高渲染质量。
技术框架:4D3R框架主要包含两个阶段:初始估计阶段和运动感知细化阶段。在初始估计阶段,利用3D基础模型(具体模型未知)估计初始的相机姿态和场景几何。在运动感知细化阶段,首先使用运动感知捆绑调整(MA-BA)模块来优化相机姿态,该模块结合了Transformer学习的先验知识和SAM2进行动态对象分割。然后,使用运动感知高斯溅射(MA-GS)表示来建模动态运动,该表示使用控制点和变形场MLP以及线性混合蒙皮技术。
关键创新:论文的关键创新在于两个方面:一是运动感知捆绑调整(MA-BA)模块,它能够更准确地估计相机姿态,尤其是在存在动态对象的情况下。二是运动感知高斯溅射(MA-GS)表示,它能够高效地建模动态运动,并在保持高质量重建的同时显著降低计算成本。MA-BA通过结合Transformer先验和SAM2实现了更鲁棒的动态对象分割,从而提高了相机姿态估计的准确性。MA-GS通过使用控制点和变形场MLP以及线性混合蒙皮技术,有效地减少了需要优化的参数数量,从而提高了计算效率。
关键设计:关于MA-BA模块,Transformer先验的具体结构和训练方式未知,SAM2的具体使用方式也未知。关于MA-GS模块,控制点的数量和位置选择、变形场MLP的网络结构、以及线性混合蒙皮的权重计算方式等具体细节未知。损失函数的设计也未知,但推测可能包含渲染损失、几何一致性损失等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,4D3R在真实动态数据集上取得了显著的性能提升,相比于现有方法,PSNR指标提升高达1.8dB。此外,4D3R在计算效率方面也表现出色,计算需求降低了5倍。这些结果表明,4D3R在动态场景的新视角合成方面具有很强的竞争力。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、机器人导航、自动驾驶等领域。例如,在虚拟现实中,可以利用该技术从单目视频中重建动态场景,从而为用户提供更逼真的沉浸式体验。在自动驾驶中,可以利用该技术感知周围的动态环境,提高车辆的安全性。
📄 摘要(原文)
Novel view synthesis from monocular videos of dynamic scenes with unknown camera poses remains a fundamental challenge in computer vision and graphics. While recent advances in 3D representations such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have shown promising results for static scenes, they struggle with dynamic content and typically rely on pre-computed camera poses. We present 4D3R, a pose-free dynamic neural rendering framework that decouples static and dynamic components through a two-stage approach. Our method first leverages 3D foundational models for initial pose and geometry estimation, followed by motion-aware refinement. 4D3R introduces two key technical innovations: (1) a motion-aware bundle adjustment (MA-BA) module that combines transformer-based learned priors with SAM2 for robust dynamic object segmentation, enabling more accurate camera pose refinement; and (2) an efficient Motion-Aware Gaussian Splatting (MA-GS) representation that uses control points with a deformation field MLP and linear blend skinning to model dynamic motion, significantly reducing computational cost while maintaining high-quality reconstruction. Extensive experiments on real-world dynamic datasets demonstrate that our approach achieves up to 1.8dB PSNR improvement over state-of-the-art methods, particularly in challenging scenarios with large dynamic objects, while reducing computational requirements by 5x compared to previous dynamic scene representations.