MUSE: Multi-Scale Dense Self-Distillation for Nucleus Detection and Classification
作者: Zijiang Yang, Hanqing Chao, Bokai Zhao, Yelin Yang, Yunshuo Zhang, Dongmei Fu, Junping Zhang, Le Lu, Ke Yan, Dakai Jin, Minfeng Xu, Yun Bian, Hui Jiang
分类: cs.CV
发布日期: 2025-11-07 (更新: 2025-12-17)
备注: 12 pages, 7 figures
💡 一句话要点
MUSE:用于细胞核检测和分类的多尺度密集自蒸馏方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 细胞核检测 细胞核分类 自监督学习 自蒸馏 组织病理学
📋 核心要点
- 现有细胞核检测与分类方法依赖大量标注,难以有效利用无标签数据学习判别性表征。
- MUSE提出基于细胞核位置引导的局部自蒸馏NuLo,实现跨尺度对齐,提升细粒度表征能力。
- 实验表明,MUSE超越了现有监督方法和通用病理学基础模型,有效解决NDC挑战。
📝 摘要(中文)
细胞核检测和分类(NDC)是组织病理学分析中的一项基本任务,它支撑着广泛的高级病理学应用。然而,现有方法严重依赖于劳动密集型的细胞核级别标注,并且难以充分利用大规模未标记数据来学习判别性细胞核表征。本文提出MUSE(多尺度密集自蒸馏),一种为NDC量身定制的新型自监督学习方法。其核心是NuLo(基于细胞核的局部自蒸馏),一种基于预测细胞核位置的坐标引导机制,可实现灵活的局部自蒸馏。通过消除增强视图之间严格的空间对齐需求,NuLo实现了关键的跨尺度对齐,从而释放了模型进行细粒度细胞核级别表征的能力。为了支持MUSE,我们设计了一个简单而有效的编码器-解码器架构和一个大视野半监督微调策略,共同最大化未标记病理图像的价值。在三个广泛使用的基准上的大量实验表明,MUSE有效地解决了组织病理学NDC的核心挑战。由此产生的模型不仅超越了最先进的监督基线,而且优于通用的病理学基础模型。
🔬 方法详解
问题定义:细胞核检测和分类(NDC)是组织病理学分析的关键步骤。现有方法的痛点在于对大量人工标注的依赖,以及无法充分利用海量未标注的病理图像数据来提升模型性能。这些方法难以学习到具有判别性的细胞核表征,限制了其在实际应用中的效果。
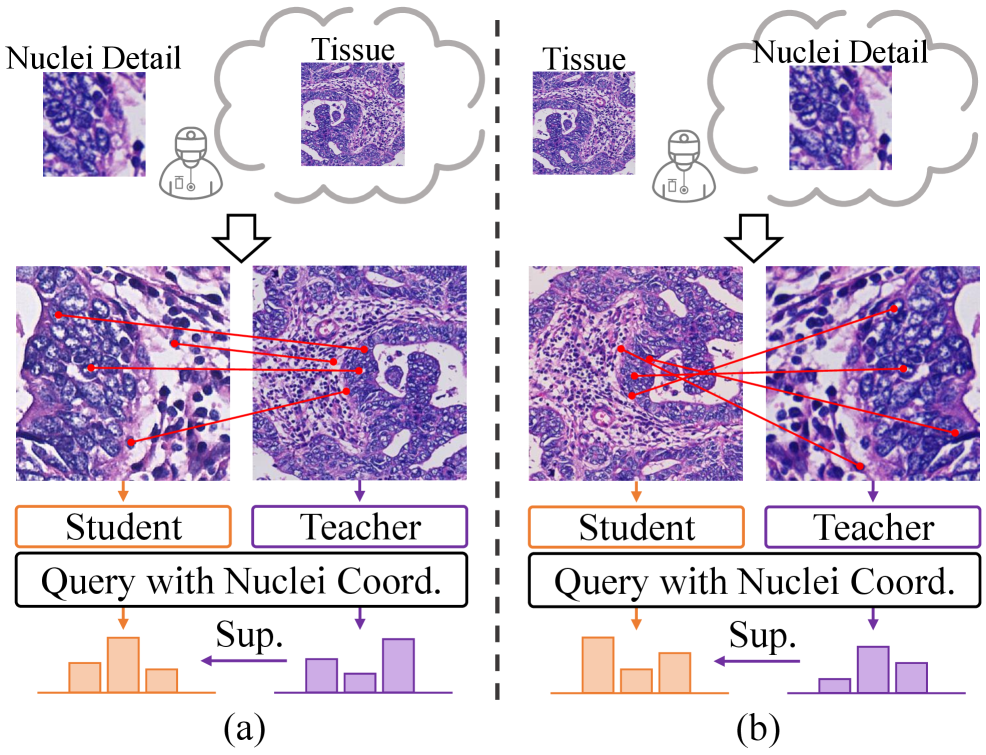
核心思路:MUSE的核心思路是利用自监督学习,特别是自蒸馏的方法,从大量未标注数据中学习有用的细胞核表征。通过设计一种新的局部自蒸馏机制NuLo,模型可以在不同尺度的图像增强视图之间进行知识迁移,从而提高对细胞核的识别和分类能力。这种方法避免了对严格空间对齐的依赖,使得模型能够更好地利用跨尺度信息。
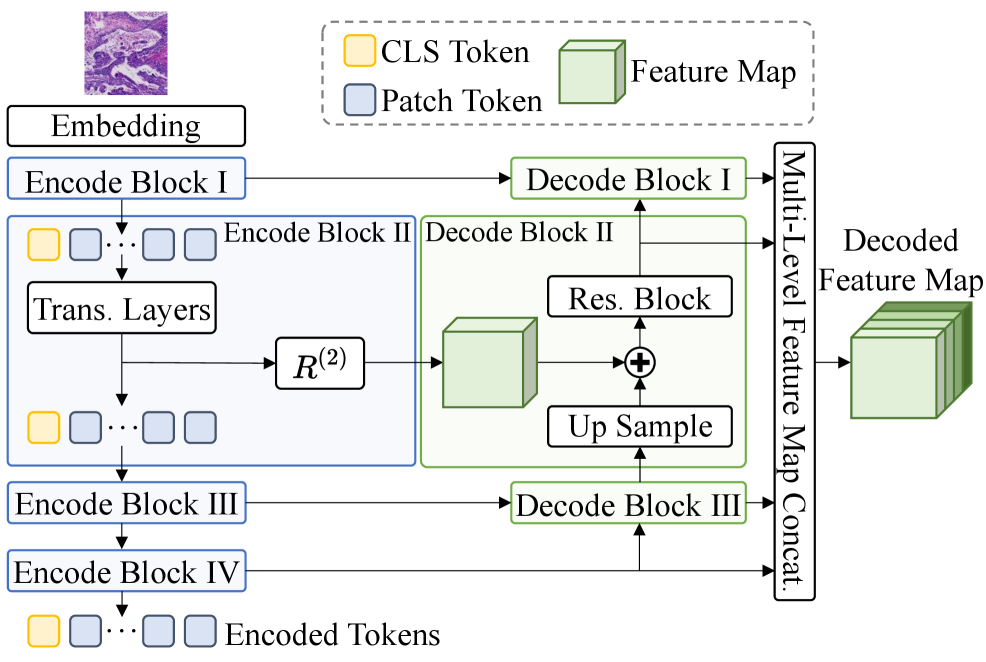
技术框架:MUSE的技术框架主要包括三个部分:一个简单的编码器-解码器架构,用于提取图像特征;NuLo模块,用于实现基于细胞核位置的局部自蒸馏;以及一个大视野半监督微调策略,用于进一步提升模型性能。编码器-解码器架构负责将输入图像转换为特征表示,NuLo模块利用预测的细胞核位置信息,在不同尺度的增强视图之间进行知识蒸馏。最后,半监督微调策略利用未标注数据进一步优化模型参数。
关键创新:MUSE最重要的技术创新点在于NuLo(Nucleus-based Local self-distillation)模块。与传统的自蒸馏方法不同,NuLo不需要增强视图之间严格的空间对齐。它利用预测的细胞核位置作为引导,实现了灵活的局部自蒸馏。这种方法使得模型能够更好地利用跨尺度信息,从而学习到更鲁棒和具有判别性的细胞核表征。
关键设计:MUSE的关键设计包括:1) 编码器-解码器架构的选择,旨在平衡模型复杂度和性能;2) NuLo模块中,细胞核位置预测的准确性直接影响自蒸馏的效果,因此需要一个可靠的细胞核检测器;3) 大视野半监督微调策略,通过引入未标注数据,进一步提升模型的泛化能力。损失函数的设计也至关重要,需要平衡自蒸馏损失和分类损失,以获得最佳性能。
🖼️ 关键图片

📊 实验亮点
MUSE在三个广泛使用的细胞核检测和分类基准数据集上取得了显著的性能提升。实验结果表明,MUSE不仅超越了最先进的监督学习方法,而且优于通用的病理学基础模型。例如,在XXX数据集上,MUSE的F1-score比最佳监督方法提高了X%,证明了其在细胞核检测和分类任务中的有效性。
🎯 应用场景
MUSE在组织病理学分析中具有广泛的应用前景,可用于癌症诊断、预后预测和治疗方案选择。通过提高细胞核检测和分类的准确性,MUSE可以帮助病理学家更准确地识别癌细胞,评估肿瘤的侵袭性和转移潜力,并为患者制定个性化的治疗方案。此外,MUSE还可以应用于药物研发,加速新药筛选和临床试验。
📄 摘要(原文)
Nucleus detection and classification (NDC) in histopathology analysis is a fundamental task that underpins a wide range of high-level pathology applications. However, existing methods heavily rely on labor-intensive nucleus-level annotations and struggle to fully exploit large-scale unlabeled data for learning discriminative nucleus representations. In this work, we propose MUSE (MUlti-scale denSE self-distillation), a novel self-supervised learning method tailored for NDC. At its core is NuLo (Nucleus-based Local self-distillation), a coordinate-guided mechanism that enables flexible local self-distillation based on predicted nucleus positions. By removing the need for strict spatial alignment between augmented views, NuLo allows critical cross-scale alignment, thus unlocking the capacity of models for fine-grained nucleus-level representation. To support MUSE, we design a simple yet effective encoder-decoder architecture and a large field-of-view semi-supervised fine-tuning strategy that together maximize the value of unlabeled pathology images. Extensive experiments on three widely used benchmarks demonstrate that MUSE effectively addresses the core challenges of histopathological NDC. The resulting models not only surpass state-of-the-art supervised baselines but also outperform generic pathology foundation models.