Another BRIXEL in the Wall: Towards Cheaper Dense Features
作者: Alexander Lappe, Martin A. Giese
分类: cs.CV, cs.LG
发布日期: 2025-11-07
🔗 代码/项目: GITHUB
💡 一句话要点
提出BRIXEL,通过知识蒸馏降低密集特征计算成本,提升下游任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 密集特征 视觉Transformer 自监督学习 计算效率 高分辨率 DINOv3
📋 核心要点
- DINOv3等模型虽能生成精细特征图,但计算复杂度高,对高分辨率图像需求大,计算成本高昂。
- BRIXEL通过知识蒸馏,让学生模型学习在高分辨率下复现自身特征,降低计算成本。
- 实验表明,BRIXEL在固定分辨率下,下游任务性能显著优于DINOv3,且计算成本更低。
📝 摘要(中文)
视觉基础模型在全局和局部密集下游任务中表现出色。DINOv3模型家族预训练于大型图像,能够生成非常精细的密集特征图,从而实现最先进的性能。然而,计算这些特征图需要高分辨率的输入图像,并且由于Transformer架构的平方复杂度,需要大量的计算资源。为了解决这些问题,我们提出了一种简单的知识蒸馏方法BRIXEL,让学生模型学习以更高的分辨率重现其自身的特征图。尽管方法简单,但在分辨率保持不变的情况下,BRIXEL在下游任务上的表现明显优于基线DINOv3模型。此外,它能够以较低的计算成本生成与教师模型非常相似的特征图。代码和模型权重可在https://github.com/alexanderlappe/BRIXEL获取。
🔬 方法详解
问题定义:论文旨在解决视觉Transformer模型,如DINOv3,在生成高分辨率密集特征图时计算成本过高的问题。现有方法需要高分辨率输入图像和大量的计算资源,限制了其在资源受限场景下的应用。
核心思路:论文的核心思路是利用知识蒸馏,训练一个学生模型,使其能够以较低的计算成本生成与教师模型(如DINOv3)相似的高分辨率特征图。学生模型学习在高分辨率下重现自身的低分辨率特征图,从而在不显著增加计算量的情况下,获得更精细的特征表示。
技术框架:BRIXEL的整体框架包括一个预训练的教师模型(例如DINOv3)和一个学生模型。教师模型生成低分辨率的特征图,然后学生模型学习将这些低分辨率特征图上采样到更高的分辨率,并尽可能地匹配教师模型在高分辨率下的特征。这个过程通过最小化学生模型和教师模型特征之间的差异来实现。
关键创新:BRIXEL的关键创新在于其简单有效的知识蒸馏策略,即让学生模型学习重现自身特征图的高分辨率版本。这种自蒸馏的方式避免了直接模仿教师模型,而是专注于提升学生模型自身的特征表达能力。
关键设计:BRIXEL的关键设计包括:1) 使用Transformer架构作为学生模型;2) 设计合适的损失函数,例如L1或L2损失,来衡量学生模型和教师模型特征图之间的差异;3) 探索不同的上采样方法,例如双线性插值或可学习的上采样层,以提高特征图的分辨率。具体的参数设置和网络结构可能需要根据具体的任务和数据集进行调整。
🖼️ 关键图片


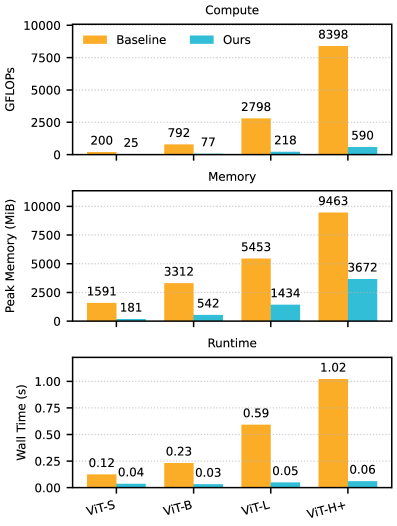
📊 实验亮点
实验结果表明,在保持分辨率不变的情况下,BRIXEL在下游任务上的性能显著优于基线DINOv3模型。此外,BRIXEL能够以远低于教师模型的计算成本生成相似的特征图。这些结果验证了BRIXEL在降低计算成本和提升性能方面的有效性。
🎯 应用场景
BRIXEL可应用于各种需要密集特征表示的计算机视觉任务,如语义分割、目标检测、图像检索等。其降低计算成本的特性使其更适用于移动设备或嵌入式系统等资源受限的场景。该方法有望推动视觉基础模型在更广泛的应用领域落地。
📄 摘要(原文)
Vision foundation models achieve strong performance on both global and locally dense downstream tasks. Pretrained on large images, the recent DINOv3 model family is able to produce very fine-grained dense feature maps, enabling state-of-the-art performance. However, computing these feature maps requires the input image to be available at very high resolution, as well as large amounts of compute due to the squared complexity of the transformer architecture. To address these issues, we propose BRIXEL, a simple knowledge distillation approach that has the student learn to reproduce its own feature maps at higher resolution. Despite its simplicity, BRIXEL outperforms the baseline DINOv3 models by large margins on downstream tasks when the resolution is kept fixed. Moreover, it is able to produce feature maps that are very similar to those of the teacher at a fraction of the computational cost. Code and model weights are available at https://github.com/alexanderlappe/BRIXEL.