Rethinking Facial Expression Recognition in the Era of Multimodal Large Language Models: Benchmark, Datasets, and Beyond
作者: Fan Zhang, Haoxuan Li, Shengju Qian, Xin Wang, Zheng Lian, Hao Wu, Zhihong Zhu, Yuan Gao, Qiankun Li, Yefeng Zheng, Zhouchen Lin, Pheng-Ann Heng
分类: cs.CV
发布日期: 2025-11-01
💡 一句话要点
提出UniFER-7B,提升多模态大语言模型在面部表情识别中的推理和可解释性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 面部表情识别 多模态大语言模型 视觉问答 后训练 强化学习 情感计算 可解释性
📋 核心要点
- 现有MLLM在面部表情识别任务中性能未充分探索,推理和可解释性存在局限。
- 通过将FER数据集转换为VQA格式,并利用后训练策略增强MLLM的推理能力。
- 构建了UniFER-7B模型,并在FERBench基准测试中超越了多个通用MLLM。
📝 摘要(中文)
多模态大语言模型(MLLMs)已经彻底改变了包括计算机视觉和情感计算在内的众多研究领域。作为该交叉领域中的一个关键挑战,面部表情识别(FER)已经从分离的、特定领域的模型发展到更统一的方法。一种有希望统一FER任务的途径是将传统的FER数据集转换为视觉问答(VQA)格式,从而能够直接应用强大的通用MLLM进行推理。然而,尽管最先进的MLLM在各种任务中取得了成功,但它们在FER任务中的性能在很大程度上仍未被探索。为了解决这一差距,我们提供了FERBench,这是一个系统性的基准,它包含了四个广泛使用的FER数据集上的20个最先进的MLLM。我们的结果表明,虽然MLLM表现出良好的分类性能,但它们在推理和可解释性方面仍然面临重大限制。为此,我们引入了旨在增强MLLM的面部表情推理能力的后训练策略。具体来说,我们策划了两个高质量和大规模的数据集:UniFER-CoT-230K用于冷启动初始化,UniFER-RLVR-360K用于具有可验证奖励的强化学习(RLVR)。在此基础上,我们开发了一个统一且可解释的FER基础模型,名为UniFER-7B,它优于许多开源和闭源的通用MLLM(例如,Gemini-2.5-Pro和Qwen2.5-VL-72B)。
🔬 方法详解
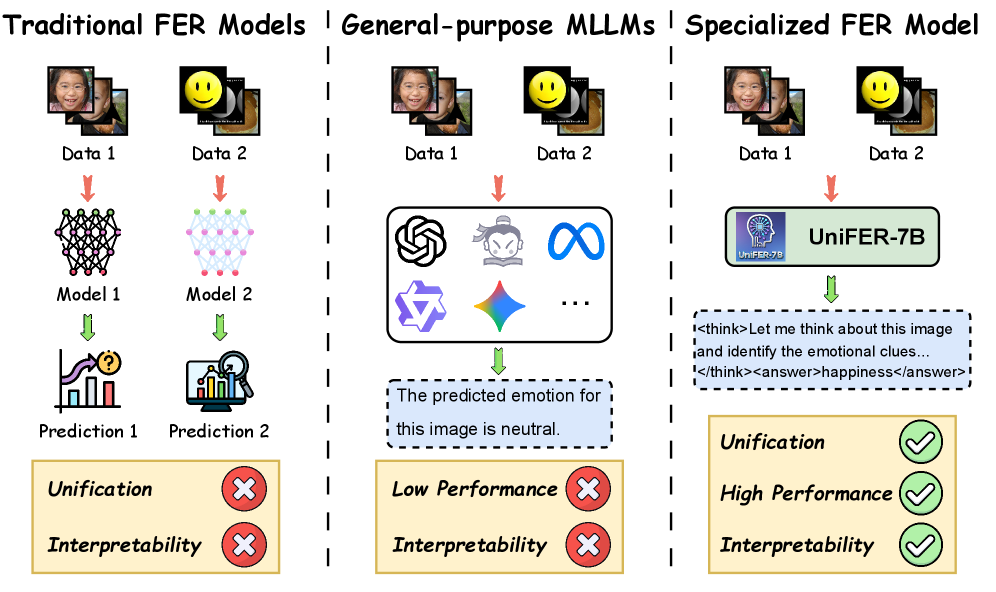
问题定义:论文旨在解决多模态大语言模型(MLLMs)在面部表情识别(FER)任务中推理能力不足和可解释性差的问题。现有方法通常是特定领域的模型,缺乏通用性和可扩展性,而直接应用通用MLLMs在FER任务上的性能尚未得到充分研究。
核心思路:论文的核心思路是将FER任务转化为视觉问答(VQA)的形式,从而能够利用MLLMs强大的视觉理解和语言推理能力。此外,通过后训练策略,使用专门构建的数据集来增强MLLMs在面部表情推理方面的能力,并提高模型的可解释性。
技术框架:整体框架包括以下几个主要阶段:1) 构建FERBench基准测试,评估现有MLLMs在FER任务上的性能;2) 收集并构建两个大规模数据集UniFER-CoT-230K和UniFER-RLVR-360K,分别用于冷启动初始化和强化学习;3) 基于这些数据集,通过后训练策略开发UniFER-7B模型;4) 在FERBench上评估UniFER-7B的性能,并与其他MLLMs进行比较。
关键创新:论文的关键创新在于:1) 系统性地评估了现有MLLMs在FER任务上的性能,揭示了其局限性;2) 构建了高质量、大规模的UniFER-CoT和UniFER-RLVR数据集,用于增强MLLMs的面部表情推理能力;3) 提出了UniFER-7B模型,这是一个统一且可解释的FER基础模型,在性能上超越了许多通用MLLMs。
关键设计:UniFER-CoT-230K数据集采用了Chain-of-Thought (CoT) 的方式,引导模型进行逐步推理。UniFER-RLVR-360K数据集则利用强化学习与可验证奖励(RLVR)机制,鼓励模型生成更准确和可信的答案。UniFER-7B模型的具体网络结构和损失函数细节未知,但强调了其统一性和可解释性。
🖼️ 关键图片

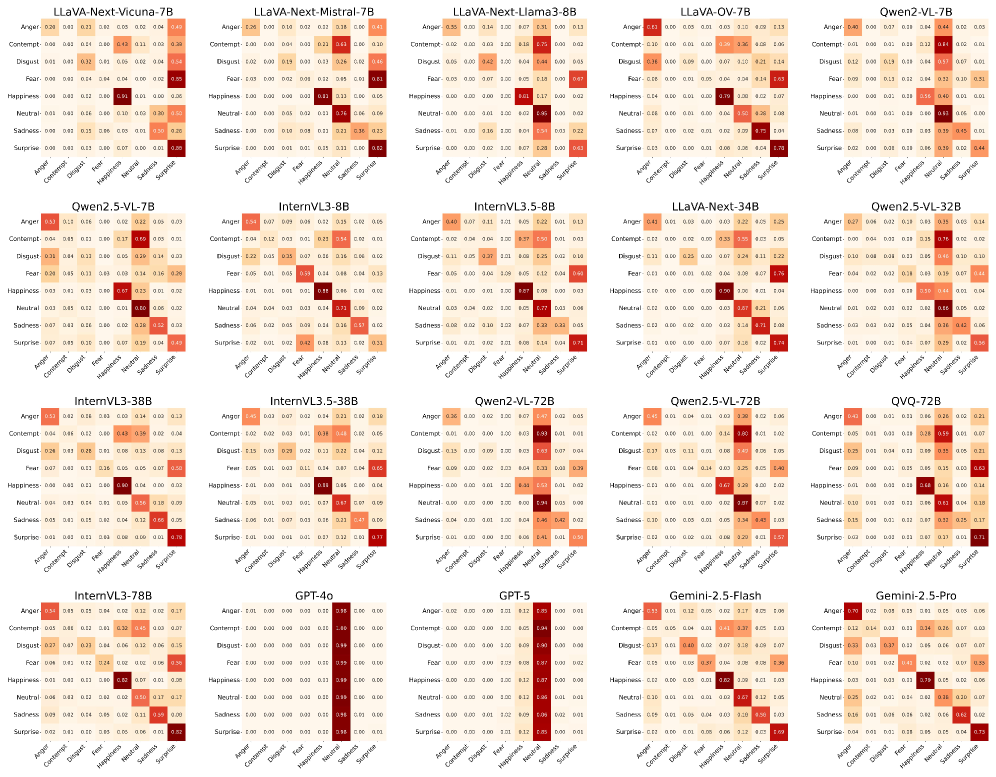
📊 实验亮点
实验结果表明,UniFER-7B模型在FERBench基准测试中取得了显著的性能提升,超越了包括Gemini-2.5-Pro和Qwen2.5-VL-72B在内的多个开源和闭源的通用MLLMs。这验证了论文提出的后训练策略和数据集构建方法的有效性,并为MLLMs在FER任务中的应用提供了新的方向。
🎯 应用场景
该研究成果可应用于人机交互、情感分析、智能监控、医疗诊断等领域。通过提升机器对面部表情的理解能力,可以改善用户体验,提高工作效率,并为心理健康评估提供辅助工具。未来,该技术有望在更广泛的场景中实现更自然、更智能的人机协作。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have revolutionized numerous research fields, including computer vision and affective computing. As a pivotal challenge in this interdisciplinary domain, facial expression recognition (FER) has evolved from separate, domain-specific models to more unified approaches. One promising avenue to unify FER tasks is converting conventional FER datasets into visual question-answering (VQA) formats, enabling the direct application of powerful generalist MLLMs for inference. However, despite the success of cutting-edge MLLMs in various tasks, their performance on FER tasks remains largely unexplored. To address this gap, we provide FERBench, a systematic benchmark that incorporates 20 state-of-the-art MLLMs across four widely used FER datasets. Our results reveal that, while MLLMs exhibit good classification performance, they still face significant limitations in reasoning and interpretability. To this end, we introduce post-training strategies aimed at enhancing the facial expression reasoning capabilities of MLLMs. Specifically, we curate two high-quality and large-scale datasets: UniFER-CoT-230K for cold-start initialization and UniFER-RLVR-360K for reinforcement learning with verifiable rewards (RLVR), respectively. Building upon them, we develop a unified and interpretable FER foundation model termed UniFER-7B, which outperforms many open-sourced and closed-source generalist MLLMs (e.g., Gemini-2.5-Pro and Qwen2.5-VL-72B).