Towards 1000-fold Electron Microscopy Image Compression for Connectomics via VQ-VAE with Transformer Prior
作者: Fuming Yang, Yicong Li, Hanspeter Pfister, Jeff W. Lichtman, Yaron Meirovitch
分类: cs.CV
发布日期: 2025-10-31 (更新: 2025-11-05)
💡 一句话要点
提出基于VQ-VAE和Transformer的电镜图像压缩框架,实现高达1000倍的压缩比。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 电镜图像压缩 VQ-VAE Transformer 连接组学 ROI重建
📋 核心要点
- 电镜数据集规模已达PB级别,对存储、传输和分析提出了严峻挑战。
- 论文提出VQ-VAE压缩框架,结合Transformer先验,在极高压缩比下保持图像纹理。
- 该框架支持ROI驱动的高分辨率重建,仅在感兴趣区域进行精细化处理。
📝 摘要(中文)
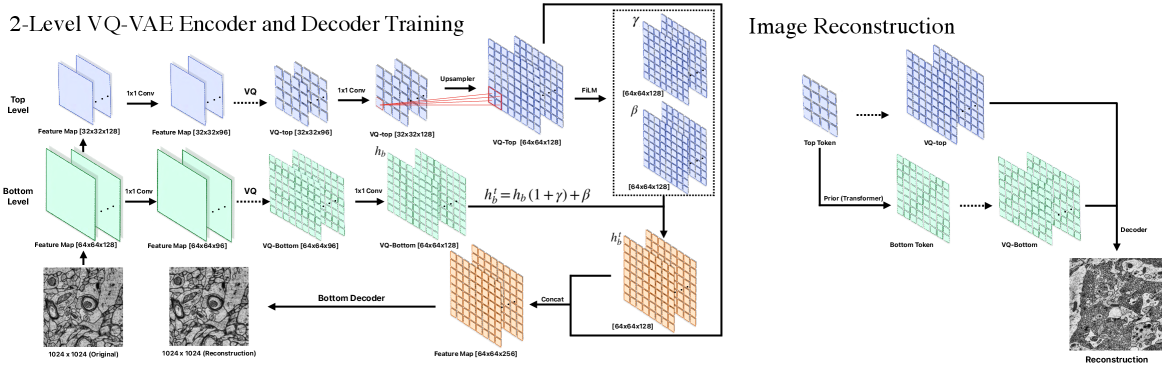
本文提出了一种基于向量量化变分自编码器(VQ-VAE)的电镜图像压缩框架,压缩比范围为16倍到1024倍。该框架支持“按需解码”:仅解码顶部token以实现极高压缩比,并可选择使用Transformer先验来预测底部token(不改变压缩比),通过特征线性调制(FiLM)和连接来恢复纹理。此外,本文还引入了一种ROI驱动的工作流程,仅在需要时从1024倍压缩的潜在空间中执行选择性的高分辨率重建。
🔬 方法详解
问题定义:电镜(EM)图像数据量巨大,存储、传输和分析成本高昂。现有压缩方法难以在极高压缩比下保持图像质量,特别是神经元等关键结构的纹理信息容易丢失,影响后续的连接组学分析。
核心思路:利用VQ-VAE学习图像的离散潜在表示,实现高压缩比。引入Transformer先验模型,预测VQ-VAE的底部token,从而在解码过程中恢复图像纹理细节。采用ROI驱动的解码策略,仅对感兴趣区域进行高分辨率重建,降低计算成本。
技术框架:该框架主要包含三个模块:VQ-VAE编码器、VQ-VAE解码器和Transformer先验。首先,VQ-VAE编码器将原始电镜图像压缩为离散的潜在表示。然后,Transformer先验模型学习潜在表示的分布,用于预测底部token。最后,VQ-VAE解码器根据顶部token和Transformer预测的底部token重建图像。对于ROI驱动的重建,首先确定感兴趣区域,然后仅对这些区域进行高分辨率解码。
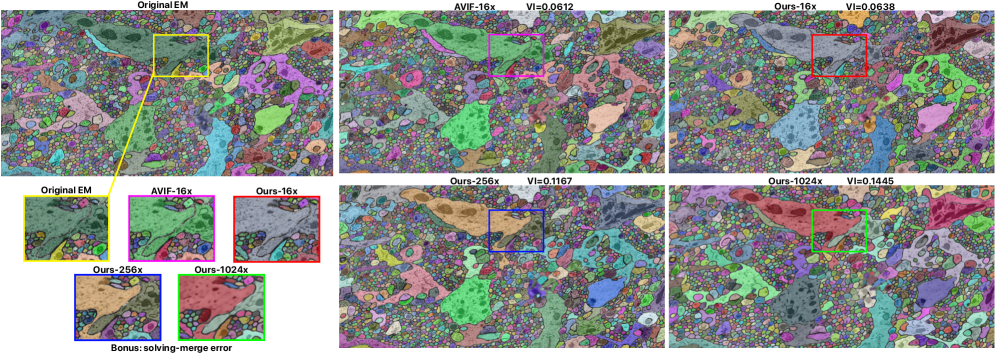
关键创新:主要创新点在于结合VQ-VAE和Transformer先验,在极高压缩比下有效恢复电镜图像的纹理信息。传统的VQ-VAE在高压缩比下容易丢失细节,而Transformer先验能够预测丢失的token,从而提升重建质量。此外,ROI驱动的重建策略能够显著降低计算成本,提高实用性。
关键设计:VQ-VAE采用标准的卷积神经网络结构,并使用向量量化层将连续的潜在表示转换为离散的token。Transformer先验模型采用自回归结构,学习潜在token的条件概率分布。特征线性调制(FiLM)用于将Transformer的输出融入到VQ-VAE解码器中,实现纹理恢复。损失函数包括重建损失、量化损失和Transformer的交叉熵损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够实现高达1024倍的压缩比,同时保持较好的图像质量。与传统的JPEG和JPEG2000等压缩方法相比,该方法在相同压缩比下能够更好地保留神经元等关键结构的纹理信息。ROI驱动的重建策略能够显著降低计算成本,使得该方法更具实用性。
🎯 应用场景
该研究成果可广泛应用于连接组学、神经科学等领域,能够有效降低电镜图像数据的存储和传输成本,加速大规模神经元连接图谱的构建和分析。同时,该方法也可应用于其他类型的大规模图像数据压缩,例如医学影像、遥感图像等。
📄 摘要(原文)
Petascale electron microscopy (EM) datasets push storage, transfer, and downstream analysis toward their current limits. We present a vector-quantized variational autoencoder-based (VQ-VAE) compression framework for EM that spans 16x to 1024x and enables pay-as-you-decode usage: top-only decoding for extreme compression, with an optional Transformer prior that predicts bottom tokens (without changing the compression ratio) to restore texture via feature-wise linear modulation (FiLM) and concatenation; we further introduce an ROI-driven workflow that performs selective high-resolution reconstruction from 1024x-compressed latents only where needed.