CompAgent: An Agentic Framework for Visual Compliance Verification
作者: Rahul Ghosh, Baishali Chaudhury, Hari Prasanna Das, Meghana Ashok, Ryan Razkenari, Sungmin Hong, Chun-Hao Liu
分类: cs.CV
发布日期: 2025-10-31 (更新: 2025-11-19)
备注: Under review
💡 一句话要点
提出CompAgent框架以解决视觉合规验证问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉合规验证 多模态大型语言模型 智能代理 动态规划 工具增强推理 深度学习 内容审核
📋 核心要点
- 核心问题:现有的视觉合规验证方法依赖于手动标注的数据集,构建成本高且泛化能力差,难以适应复杂的政策规则。
- 方法要点:CompAgent框架通过增强多模态大型语言模型,结合视觉工具和动态规划代理,实现了灵活的合规验证。
- 实验或效果:CompAgent在UnsafeBench数据集上取得了76%的F1分数,较现有技术提升了10%,展示了其有效性。
📝 摘要(中文)
视觉合规验证是计算机视觉领域中的一个重要但未被充分探索的问题,尤其在媒体、娱乐和广告等领域,内容必须遵循复杂且不断变化的政策规则。现有方法通常依赖于针对特定任务的深度学习模型,这些模型需要手动标注的数据集,构建成本高且泛化能力有限。尽管最近的多模态大型语言模型(MLLMs)提供了广泛的现实世界知识和政策理解,但它们在细粒度视觉细节推理和有效应用结构化合规规则方面存在困难。本文提出了CompAgent,这是第一个用于视觉合规验证的智能框架。CompAgent通过一系列视觉工具(如物体检测器、面部分析器、NSFW检测器和字幕生成模型)增强了MLLMs,并引入了一个规划代理,根据合规政策动态选择适当的工具。合规验证代理则整合图像、工具输出和政策上下文进行多模态推理。实验结果表明,CompAgent在公共基准测试上超越了专门分类器、直接MLLM提示和策划路由基线,在UnsafeBench数据集上达到了76%的F1分数,比现有技术提高了10%。
🔬 方法详解
问题定义:本文旨在解决视觉合规验证这一具体问题,现有方法的痛点在于依赖于昂贵的手动标注数据集,且缺乏对复杂政策规则的适应性。
核心思路:CompAgent框架的核心思路是通过增强多模态大型语言模型(MLLMs),结合一系列视觉工具和动态规划代理,来实现灵活且高效的合规验证。这样的设计使得系统能够根据不同的合规政策选择合适的工具,从而提高验证的准确性和适应性。
技术框架:CompAgent的整体架构包括多个主要模块:首先是视觉工具模块,包含物体检测器、面部分析器、NSFW检测器和字幕生成模型;其次是规划代理模块,负责根据合规政策动态选择工具;最后是合规验证代理模块,整合图像、工具输出和政策上下文进行多模态推理。
关键创新:CompAgent的最重要创新在于引入了规划代理,使得系统能够根据具体的合规政策动态选择工具,这一设计与现有方法的静态工具选择方式形成了本质区别。
关键设计:在关键设计方面,CompAgent采用了多种视觉工具的组合,利用深度学习模型进行特征提取和推理,同时在损失函数和参数设置上进行了优化,以确保系统在不同场景下的鲁棒性和准确性。
🖼️ 关键图片
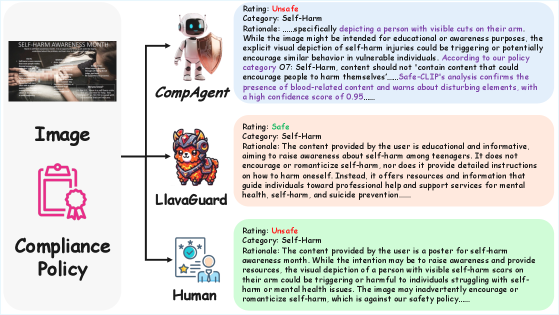


📊 实验亮点
实验结果显示,CompAgent在UnsafeBench数据集上达到了76%的F1分数,较现有技术提高了10%。这一成果表明了智能规划和工具增强推理在可扩展、准确和适应性强的视觉合规验证中的有效性。
🎯 应用场景
该研究的潜在应用领域包括媒体、广告和娱乐等行业,能够帮助这些领域的内容创作者和监管机构确保其内容符合复杂的政策要求。未来,CompAgent框架有望扩展到其他需要合规验证的视觉内容领域,提升内容审核的效率和准确性。
📄 摘要(原文)
Visual compliance verification is a critical yet underexplored problem in computer vision, especially in domains such as media, entertainment, and advertising where content must adhere to complex and evolving policy rules. Existing methods often rely on task-specific deep learning models trained on manually labeled datasets, which are costly to build and limited in generalizability. While recent Multimodal Large Language Models (MLLMs) offer broad real-world knowledge and policy understanding, they struggle to reason over fine-grained visual details and apply structured compliance rules effectively on their own. In this paper, we propose CompAgent, the first agentic framework for visual compliance verification. CompAgent augments MLLMs with a suite of visual tools-such as object detectors, face analyzers, NSFW detectors, and captioning models-and introduces a planning agent that dynamically selects appropriate tools based on the compliance policy. A compliance verification agent then integrates image, tool outputs, and policy context to perform multimodal reasoning. Experiments on public benchmarks show that CompAgent outperforms specialized classifiers, direct MLLM prompting, and curated routing baselines, achieving up to 76% F1 score and a 10% improvement over the state-of-the-art on the UnsafeBench dataset. Our results demonstrate the effectiveness of agentic planning and robust tool-augmented reasoning for scalable, accurate, and adaptable visual compliance verification.