FLoC: Facility Location-Based Efficient Visual Token Compression for Long Video Understanding
作者: Janghoon Cho, Jungsoo Lee, Munawar Hayat, Kyuwoong Hwang, Fatih Porikli, Sungha Choi
分类: cs.CV, cs.AI
发布日期: 2025-10-31
💡 一句话要点
FLoC:基于设施选址的长视频高效视觉Token压缩方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 视觉Token压缩 设施选址 惰性贪婪算法 视频-LLM 多模态学习 模型无关 免训练
📋 核心要点
- 长视频理解面临海量视觉Token带来的计算瓶颈,限制了大型多模态模型(LMMs)的应用。
- FLoC利用设施选址函数和惰性贪婪算法,在Token数量预算下,高效选择最具代表性和多样性的Token子集。
- 实验表明,FLoC在多个长视频理解基准测试中超越现有压缩方法,同时保持了处理速度的优势。
📝 摘要(中文)
本文提出FLoC,一种高效的视觉Token压缩框架,它基于设施选址函数,以一种原则性的方式在预定义的Token数量预算内快速选择一个紧凑但具有高度代表性和多样性的视觉Token子集。通过集成惰性贪婪算法,我们的方法通过快速选择紧凑的Token子集来实现显著的效率提升,从而大幅减少视觉Token的数量,同时保证接近最优的性能。值得注意的是,我们的方法是免训练的、模型无关的、查询无关的,提供了一种通用的解决方案,可以无缝集成到各种视频-LLM和现有工作流程中。在Video-MME、MLVU和LongVideoBench等大规模基准上的广泛评估表明,我们的框架始终优于最近的压缩技术,突出了其在解决长视频理解的关键挑战方面的有效性和鲁棒性,以及其在处理速度方面的效率。
🔬 方法详解
问题定义:长视频理解任务中,从视频序列提取的视觉Token数量巨大,导致计算成本过高,限制了视频-LLM处理长视频的能力。现有的压缩方法可能无法在保证性能的同时,有效地减少Token数量,或者需要针对特定模型进行训练,泛化性较差。
核心思路:FLoC的核心思想是将视觉Token压缩问题转化为一个设施选址问题。每个视觉Token被视为一个潜在的“设施”,目标是从中选择一个子集,使得选出的Token能够最大程度地代表整个Token集合,同时满足Token数量的预算约束。通过最大化选址函数,保证选出的Token具有代表性和多样性。
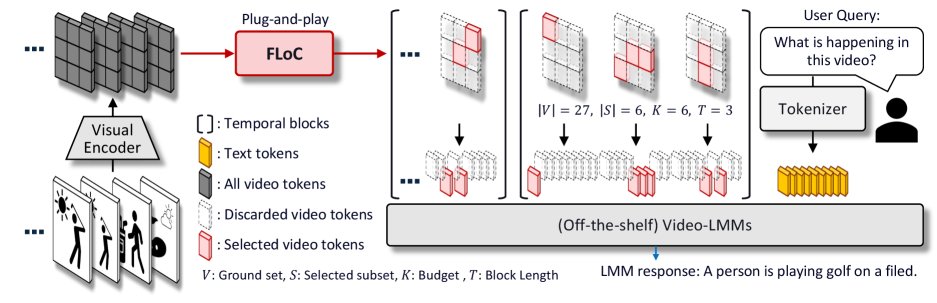
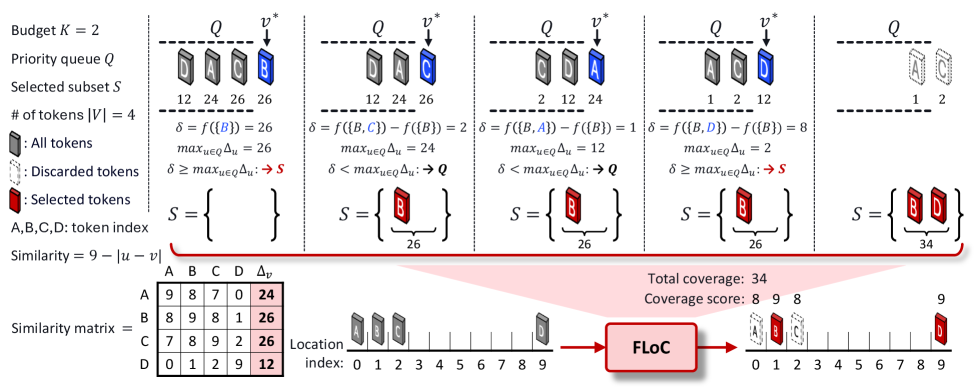
技术框架:FLoC框架主要包含以下步骤:1) 特征提取:使用预训练的视觉编码器提取视频帧的视觉特征,得到初始的视觉Token集合。2) 相似度计算:计算Token之间的相似度,构建相似度矩阵。3) 设施选址:利用惰性贪婪算法,基于设施选址函数,迭代地选择Token子集,直到达到Token数量预算。4) Token传递:将选出的Token子集传递给下游的视频-LLM进行处理。
关键创新:FLoC的关键创新在于将视觉Token压缩问题建模为设施选址问题,并利用惰性贪婪算法高效地求解。与传统的聚类或采样方法相比,FLoC能够更好地平衡Token的代表性和多样性,从而在压缩Token数量的同时,保持较高的性能。此外,FLoC是免训练的、模型无关的、查询无关的,具有很强的通用性。
关键设计:设施选址函数的设计是FLoC的关键。论文中使用的设施选址函数旨在最大化选出的Token子集对整个Token集合的覆盖程度,同时鼓励选择具有多样性的Token。惰性贪婪算法用于加速设施选址过程,通过维护一个优先级队列,避免重复计算,从而显著提高效率。具体的相似度度量方式和Token数量预算需要根据具体的应用场景进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FLoC在Video-MME、MLVU和LongVideoBench等大规模基准测试中,显著优于现有的Token压缩方法。例如,在Video-MME数据集上,FLoC在压缩Token数量的同时,仍然能够保持甚至提升模型的性能。此外,FLoC的处理速度也明显快于其他方法,证明了其高效性。
🎯 应用场景
FLoC可广泛应用于需要处理长视频的各种场景,例如视频摘要、视频检索、视频问答、视频编辑等。通过降低计算成本,FLoC使得视频-LLM能够处理更长的视频序列,从而提升相关应用的性能和用户体验。此外,FLoC的通用性使其可以方便地集成到现有的视频处理流程中,具有很高的实际应用价值。
📄 摘要(原文)
Recent studies in long video understanding have harnessed the advanced visual-language reasoning capabilities of Large Multimodal Models (LMMs), driving the evolution of video-LMMs specialized for processing extended video sequences. However, the scalability of these models is severely limited by the overwhelming volume of visual tokens generated from extended video sequences. To address this challenge, this paper proposes FLoC, an efficient visual token compression framework based on the facility location function, a principled approach that swiftly selects a compact yet highly representative and diverse subset of visual tokens within a predefined budget on the number of visual tokens. By integrating the lazy greedy algorithm, our method achieves remarkable efficiency gains by swiftly selecting a compact subset of tokens, drastically reducing the number of visual tokens while guaranteeing near-optimal performance. Notably, our approach is training-free, model-agnostic, and query-agnostic, providing a versatile solution that seamlessly integrates with diverse video-LLMs and existing workflows. Extensive evaluations on large-scale benchmarks, such as Video-MME, MLVU, and LongVideoBench, demonstrate that our framework consistently surpasses recent compression techniques, highlighting not only its effectiveness and robustness in addressing the critical challenges of long video understanding, but also its efficiency in processing speed.