Phased DMD: Few-step Distribution Matching Distillation via Score Matching within Subintervals
作者: Xiangyu Fan, Zesong Qiu, Zhuguanyu Wu, Fanzhou Wang, Zhiqian Lin, Tianxiang Ren, Dahua Lin, Ruihao Gong, Lei Yang
分类: cs.CV
发布日期: 2025-10-31
💡 一句话要点
提出Phased DMD,通过子区间内分数匹配蒸馏提升多步生成模型的性能和多样性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分布匹配蒸馏 多步生成模型 阶段性蒸馏 混合专家模型 分数匹配 图像生成 视频生成
📋 核心要点
- 现有DMD方法在复杂生成任务中,单步蒸馏模型性能受限,多步蒸馏则面临内存和计算压力,且多样性降低。
- Phased DMD通过渐进式分布匹配和子区间分数匹配,结合混合专家模型,降低学习难度并提升模型容量。
- 实验表明,Phased DMD在图像和视频生成任务中,相较于DMD,能更好地保持生成多样性并保留关键生成能力。
📝 摘要(中文)
分布匹配蒸馏(DMD)将基于分数的生成模型提炼成高效的单步生成器,无需与教师模型的采样轨迹一一对应。然而,有限的模型容量导致单步蒸馏模型在复杂的生成任务上表现不佳,例如在文本到视频生成中合成复杂的对象运动。直接将DMD扩展到多步蒸馏会增加内存使用和计算深度,导致不稳定和效率降低。虽然先前的工作提出了随机梯度截断作为潜在的解决方案,但我们观察到它大大降低了多步蒸馏模型的生成多样性,使其降至单步模型的水平。为了解决这些限制,我们提出了Phased DMD,这是一个多步蒸馏框架,它将阶段性蒸馏的思想与混合专家(MoE)相结合,降低了学习难度,同时增强了模型容量。Phased DMD建立在两个关键思想之上:渐进式分布匹配和子区间内的分数匹配。首先,我们的模型将信噪比(SNR)范围划分为子区间,逐步细化模型到更高的SNR水平,以更好地捕获复杂分布。接下来,为了确保每个子区间内的训练目标是准确的,我们进行了严格的数学推导。我们通过蒸馏最先进的图像和视频生成模型(包括Qwen-Image (20B参数)和Wan2.2 (28B参数))来验证Phased DMD。实验结果表明,Phased DMD比DMD更好地保留了输出多样性,同时保留了关键的生成能力。我们将发布我们的代码和模型。
🔬 方法详解
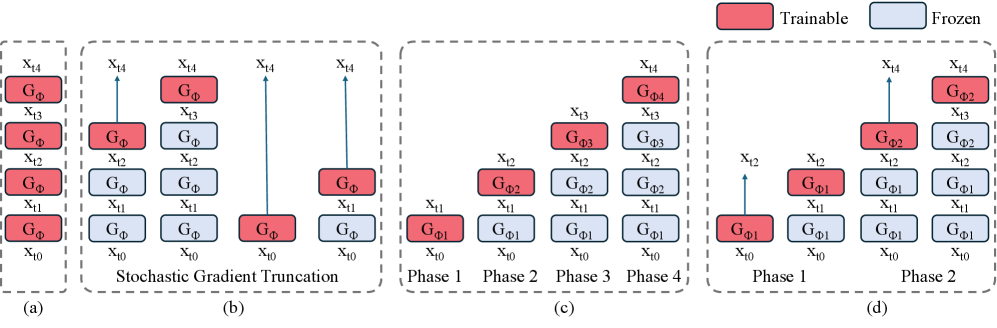
问题定义:论文旨在解决分布匹配蒸馏(DMD)在复杂生成任务中,将基于分数的生成模型蒸馏成高效多步生成器时遇到的问题。现有方法,特别是单步DMD,由于模型容量有限,在生成复杂内容(如视频中的复杂运动)时表现不佳。直接扩展到多步DMD虽然能提升性能,但会显著增加内存占用和计算复杂度,导致训练不稳定和效率降低。此外,现有的随机梯度截断方法虽然能缓解计算压力,但会严重降低生成结果的多样性。
核心思路:Phased DMD的核心思路是将蒸馏过程分解为多个阶段,每个阶段专注于信噪比(SNR)的一个子区间。通过逐步细化模型在不同SNR水平下的生成能力,从而更好地捕捉复杂的数据分布。同时,结合混合专家(MoE)模型,增加模型容量,以应对复杂生成任务的需求。这种分阶段、逐步细化的方式降低了学习难度,避免了直接训练一个庞大复杂模型的困难。
技术框架:Phased DMD的整体框架包含以下几个主要步骤:1) 将SNR范围划分为多个子区间。2) 在每个子区间内,使用分数匹配损失函数训练模型,优化模型在该SNR范围内的生成能力。3) 采用渐进式训练策略,从低SNR区间到高SNR区间逐步训练模型。4) 使用混合专家(MoE)模型,每个专家负责处理不同的SNR区间或不同的数据特征,从而增加模型容量和表达能力。
关键创新:Phased DMD的关键创新在于将阶段性蒸馏的思想与混合专家模型相结合,并将其应用于分布匹配蒸馏。与传统的DMD方法相比,Phased DMD能够更好地处理复杂的数据分布,并保持生成结果的多样性。此外,通过将训练过程分解为多个阶段,降低了学习难度,使得训练更加稳定和高效。
关键设计:在Phased DMD中,SNR子区间的划分方式、每个子区间内使用的分数匹配损失函数、以及混合专家模型的结构是关键的设计要素。论文通过严格的数学推导,确保每个子区间内的训练目标是准确的。此外,论文还可能采用了特定的网络结构和训练技巧,以提高模型的生成质量和效率。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Phased DMD在图像和视频生成任务中,相较于传统的DMD方法,能够更好地保留输出多样性,同时保持关键的生成能力。具体而言,通过蒸馏Qwen-Image (20B参数)和Wan2.2 (28B参数)等大型模型,Phased DMD在生成质量和多样性方面取得了显著的提升,证明了其有效性和优越性。具体的性能指标和提升幅度需要在论文中进一步查找。
🎯 应用场景
Phased DMD具有广泛的应用前景,包括图像生成、视频生成、音频生成等领域。它可以用于训练高效的文本到图像/视频生成模型,从而实现高质量的内容创作。此外,Phased DMD还可以应用于数据增强、图像修复、超分辨率等任务,提升相关应用的性能和用户体验。该研究的成果有望推动生成模型在实际应用中的普及。
📄 摘要(原文)
Distribution Matching Distillation (DMD) distills score-based generative models into efficient one-step generators, without requiring a one-to-one correspondence with the sampling trajectories of their teachers. However, limited model capacity causes one-step distilled models underperform on complex generative tasks, e.g., synthesizing intricate object motions in text-to-video generation. Directly extending DMD to multi-step distillation increases memory usage and computational depth, leading to instability and reduced efficiency. While prior works propose stochastic gradient truncation as a potential solution, we observe that it substantially reduces the generation diversity of multi-step distilled models, bringing it down to the level of their one-step counterparts. To address these limitations, we propose Phased DMD, a multi-step distillation framework that bridges the idea of phase-wise distillation with Mixture-of-Experts (MoE), reducing learning difficulty while enhancing model capacity. Phased DMD is built upon two key ideas: progressive distribution matching and score matching within subintervals. First, our model divides the SNR range into subintervals, progressively refining the model to higher SNR levels, to better capture complex distributions. Next, to ensure the training objective within each subinterval is accurate, we have conducted rigorous mathematical derivations. We validate Phased DMD by distilling state-of-the-art image and video generation models, including Qwen-Image (20B parameters) and Wan2.2 (28B parameters). Experimental results demonstrate that Phased DMD preserves output diversity better than DMD while retaining key generative capabilities. We will release our code and models.