Dual-Stream Diffusion for World-Model Augmented Vision-Language-Action Model
作者: John Won, Kyungmin Lee, Huiwon Jang, Dongyoung Kim, Jinwoo Shin
分类: cs.CV, cs.RO
发布日期: 2025-10-31 (更新: 2025-11-04)
备注: 20 pages, 10 figures
💡 一句话要点
提出双流扩散模型DUST,增强世界模型在视觉-语言-动作模型中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 世界模型 扩散模型 双流架构 机器人学习 跨模态学习 解耦训练
📋 核心要点
- 视觉-语言-动作模型结合世界模型在机器人策略学习中展现潜力,但不同模态的联合预测仍具挑战。
- DUST框架通过双流扩散Transformer架构,显式维护模态流并解耦训练,实现跨模态知识共享和双向学习。
- 实验表明,DUST在模拟和真实机器人任务中均优于基线方法,且大规模预训练能进一步提升性能。
📝 摘要(中文)
本文提出了一种名为双流扩散(DUST)的框架,用于增强具有世界模型的视觉-语言-动作模型(VLA)。该框架旨在解决预测下一状态观测和动作序列时,由于模态差异而带来的挑战。DUST采用多模态扩散Transformer架构,显式地维护独立的模态流,同时实现跨模态知识共享。此外,论文还提出了独立的噪声扰动和解耦的流匹配损失等训练技术,使模型能够以双向方式学习联合分布,而无需统一的潜在空间。基于解耦训练框架,论文还引入了一种异步采样方法,在不同速率下对动作和视觉token进行采样,从而通过推理时缩放来提高性能。在RoboCasa和GR-1等模拟基准测试中,DUST比标准VLA基线和隐式世界建模方法提高了高达6%的性能,推理时缩放方法还额外提供了2-5%的成功率提升。在Franka Research 3的真实世界任务中,DUST的成功率比基线高出13%,验证了其有效性。最后,论文证明了DUST在BridgeV2的无动作视频的大规模预训练中的有效性,迁移到RoboCasa基准测试时带来了显著的性能提升。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作模型(VLA)在结合世界模型时,由于视觉观测和动作序列这两种模态的固有差异,导致联合预测性能受限的问题。现有方法难以有效处理这种模态冲突,限制了VLA在复杂机器人任务中的应用。
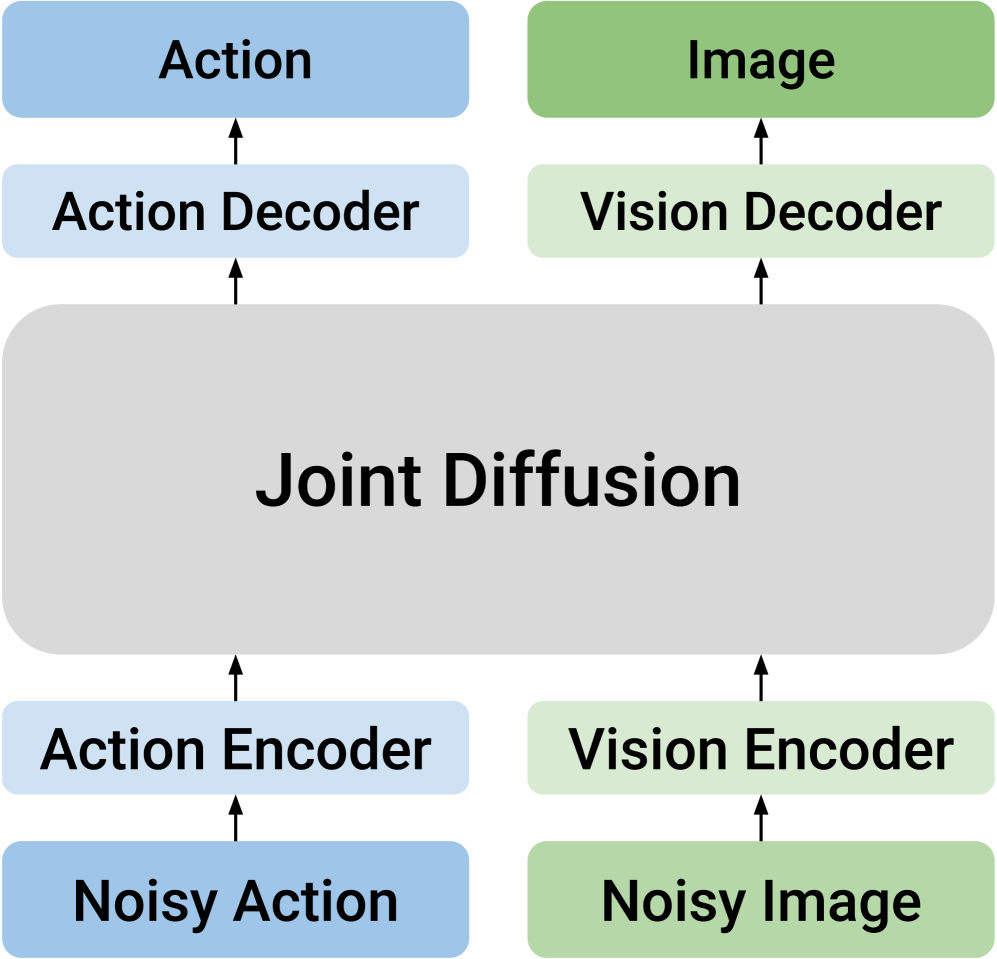
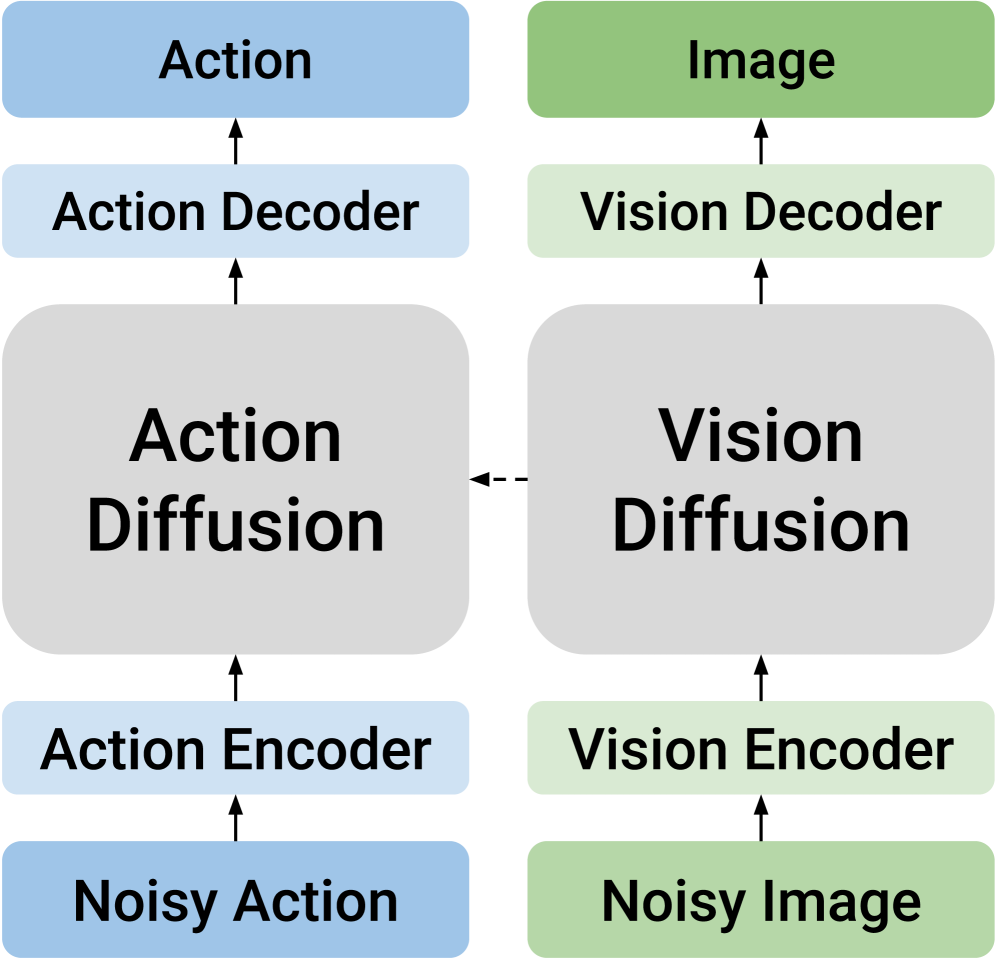
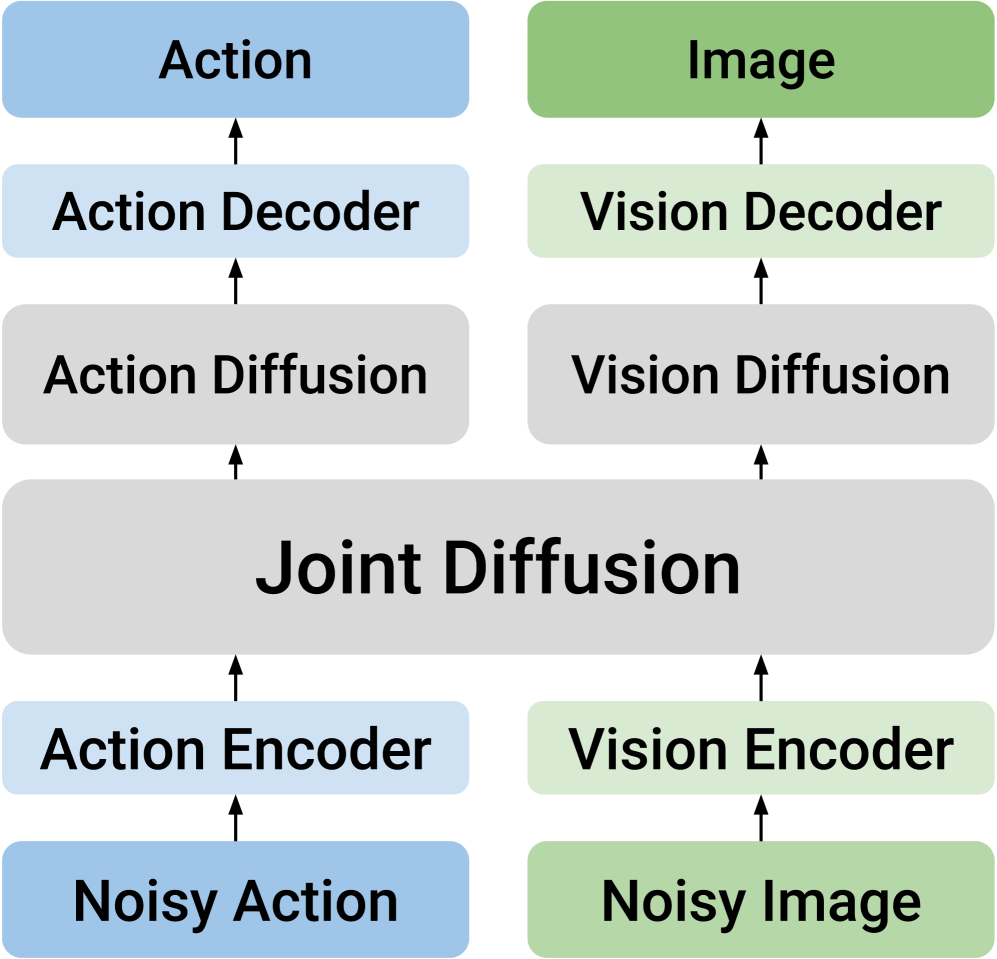
核心思路:论文的核心思路是采用双流扩散模型,显式地将视觉和动作模态分离成两个独立的流进行处理,同时通过跨模态Transformer实现知识共享。这种设计避免了将不同模态强行映射到统一潜在空间,从而更好地保留了各自的特性,并允许模型以更灵活的方式学习它们之间的关系。
技术框架:DUST框架主要包含以下几个模块:1) 多模态扩散Transformer:这是DUST的核心架构,包含两个独立的模态流(视觉流和动作流),每个流都由Transformer层组成。2) 跨模态连接:通过交叉注意力机制,允许两个模态流之间进行信息交互和知识共享。3) 解耦训练:采用独立的噪声扰动和解耦的流匹配损失,使得模型能够以双向方式学习联合分布。4) 异步采样:在推理阶段,以不同的速率对动作和视觉token进行采样,实现推理时缩放。
关键创新:DUST最重要的技术创新点在于其双流架构和解耦训练方法。与传统的单流模型相比,双流架构能够更好地处理不同模态之间的差异,避免信息损失。解耦训练方法则允许模型以更灵活的方式学习联合分布,而无需统一的潜在空间,从而提高了模型的表达能力和泛化性能。
关键设计:DUST的关键设计包括:1) 独立的噪声扰动:对视觉和动作模态分别施加不同的噪声,以更好地适应各自的特性。2) 解耦的流匹配损失:分别计算视觉流和动作流的损失,避免了模态之间的干扰。3) 异步采样:在推理阶段,通过调整视觉和动作token的采样速率,实现推理时缩放,进一步提高性能。4) 交叉注意力机制:在Transformer层中引入交叉注意力,实现跨模态知识共享。
🖼️ 关键图片
📊 实验亮点
DUST在RoboCasa和GR-1等模拟环境中,相较于标准VLA基线和隐式世界建模方法,成功率提升高达6%,通过推理时缩放,额外提升2-5%。在真实世界的Franka Research 3机器人任务中,DUST的成功率比基线高出13%。此外,通过在BridgeV2数据集上进行大规模预训练,DUST在迁移到RoboCasa基准测试时获得了显著的性能提升。
🎯 应用场景
该研究成果可应用于各种机器人任务,例如家庭服务机器人、工业自动化机器人和自动驾驶等。通过增强VLA模型的世界建模能力,可以使机器人更好地理解环境、预测未来状态,并做出更合理的决策,从而提高机器人的自主性和适应性。此外,该方法在视频预训练方面的潜力也使其可以应用于更广泛的视觉-语言任务。
📄 摘要(原文)
Recently, augmenting vision-language-action models (VLAs) with world-models has shown promise in robotic policy learning. However, it remains challenging to jointly predict next-state observations and action sequences because of the inherent difference between the two modalities. To address this, we propose DUal-STream diffusion (DUST), a world-model augmented VLA framework that handles the modality conflict and enhances the performance of VLAs across diverse tasks. Specifically, we propose a multimodal diffusion transformer architecture that explicitly maintains separate modality streams while enabling cross-modal knowledge sharing. In addition, we propose training techniques such as independent noise perturbations for each modality and a decoupled flow matching loss, which enables the model to learn the joint distribution in a bidirectional manner while avoiding the need for a unified latent space. Furthermore, based on the decoupled training framework, we introduce a sampling method where we sample action and vision tokens asynchronously at different rates, which shows improvement through inference-time scaling. Through experiments on simulated benchmarks such as RoboCasa and GR-1, DUST achieves up to 6% gains over a standard VLA baseline and implicit world-modeling methods, with our inference-time scaling approach providing an additional 2-5% gain on success rate. On real-world tasks with the Franka Research 3, DUST outperforms baselines in success rate by 13%, confirming its effectiveness beyond simulation. Lastly, we demonstrate the effectiveness of DUST in large-scale pretraining with action-free videos from BridgeV2, where DUST leads to significant gain when transferred to the RoboCasa benchmark.