Context-Gated Cross-Modal Perception with Visual Mamba for PET-CT Lung Tumor Segmentation
作者: Elena Mulero Ayllón, Linlin Shen, Pierangelo Veltri, Fabrizia Gelardi, Arturo Chiti, Paolo Soda, Matteo Tortora
分类: cs.CV, cs.AI
发布日期: 2025-10-31
🔗 代码/项目: GITHUB
💡 一句话要点
提出vMambaX,利用上下文门控跨模态感知和视觉Mamba进行PET-CT肺肿瘤分割
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 肺肿瘤分割 PET-CT 多模态融合 Visual Mamba 上下文门控 医学图像分析 深度学习
📋 核心要点
- 现有肺肿瘤分割方法难以有效融合PET和CT信息,限制了诊断和治疗计划的优化。
- vMambaX通过上下文门控跨模态感知模块,自适应地增强PET和CT图像特征的交互,抑制噪声。
- 在PCLT20K数据集上,vMambaX优于基线模型,同时保持较低的计算复杂度,验证了其有效性。
📝 摘要(中文)
精确的肺肿瘤分割对于改善诊断和治疗计划至关重要,而有效结合PET和CT的解剖和功能信息仍然是一个主要挑战。本研究提出了vMambaX,一个轻量级多模态框架,通过上下文门控跨模态感知模块(CGM)整合PET和CT扫描图像。vMambaX建立在Visual Mamba架构之上,自适应地增强模态间特征交互,强调信息丰富的区域,同时抑制噪声。在PCLT20K数据集上的评估表明,该模型优于基线模型,同时保持较低的计算复杂度。这些结果突出了自适应跨模态门控对于多模态肿瘤分割的有效性,并证明了vMambaX作为一种高效且可扩展的框架在高级肺癌分析中的潜力。代码可在https://github.com/arco-group/vMambaX获取。
🔬 方法详解
问题定义:论文旨在解决肺部肿瘤在PET-CT图像上的精确分割问题。现有方法在融合PET和CT两种模态信息时,往往难以有效提取和利用模态间的互补信息,容易受到噪声干扰,导致分割精度不高。此外,计算复杂度也是一个挑战,尤其是在处理大规模数据集时。
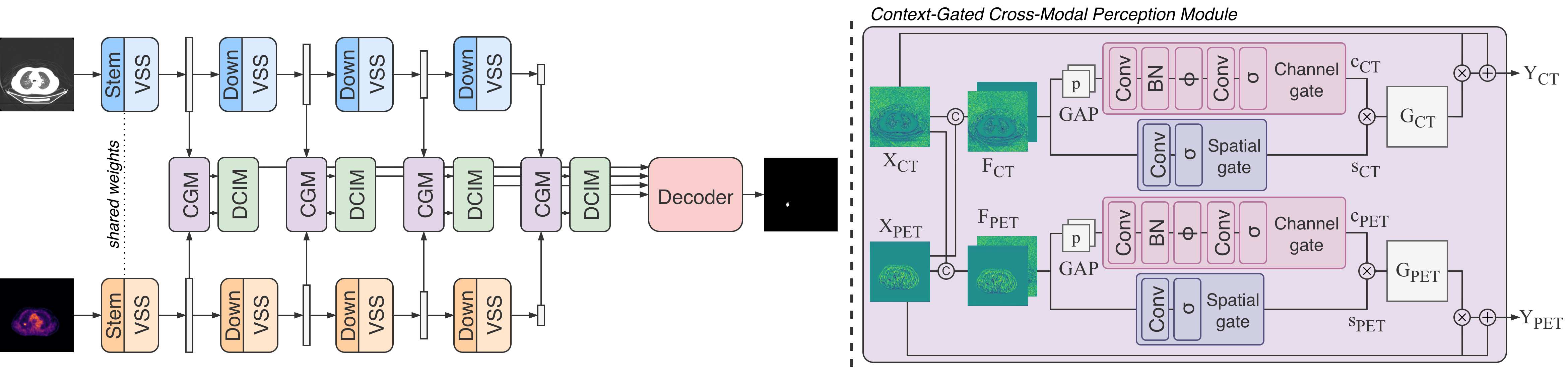
核心思路:论文的核心思路是利用Visual Mamba架构的强大序列建模能力,并引入上下文门控机制,实现PET和CT图像特征的自适应融合。通过上下文门控,模型能够动态地调整不同模态特征的权重,突出信息丰富的区域,抑制噪声,从而提高分割精度。
技术框架:vMambaX框架主要包括以下几个部分:首先,分别对PET和CT图像进行预处理和特征提取。然后,通过上下文门控跨模态感知模块(CGM)进行特征融合,该模块利用Visual Mamba架构进行序列建模,并根据上下文信息自适应地调整不同模态特征的权重。最后,利用分割头对融合后的特征进行分割预测。
关键创新:论文的关键创新在于提出了上下文门控跨模态感知模块(CGM),该模块能够自适应地增强模态间特征交互,强调信息丰富的区域,同时抑制噪声。与传统的特征融合方法相比,CGM能够更好地利用PET和CT图像的互补信息,提高分割精度。此外,采用Visual Mamba架构也降低了计算复杂度。
关键设计:CGM模块的关键设计包括:1) 使用Visual Mamba作为序列建模器,捕捉PET和CT图像特征之间的长程依赖关系;2) 引入上下文门控机制,根据上下文信息动态地调整不同模态特征的权重;3) 使用残差连接和归一化层,提高模型的稳定性和泛化能力。具体的参数设置和损失函数细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
vMambaX在PCLT20K数据集上进行了评估,实验结果表明,该模型在分割精度上优于基线模型,同时保持较低的计算复杂度。具体的性能提升数据(如Dice系数、IoU等)和对比基线的名称在论文中进行了详细描述(未知)。这些结果验证了上下文门控跨模态感知模块的有效性,并证明了vMambaX作为一种高效且可扩展的框架在高级肺癌分析中的潜力。
🎯 应用场景
该研究成果可应用于肺癌的计算机辅助诊断和治疗计划。通过精确的肺肿瘤分割,医生可以更准确地评估肿瘤的大小、形状和位置,从而制定更有效的治疗方案。此外,该方法还可以扩展到其他多模态医学图像分割任务,例如脑肿瘤分割和心脏分割,具有广泛的应用前景。
📄 摘要(原文)
Accurate lung tumor segmentation is vital for improving diagnosis and treatment planning, and effectively combining anatomical and functional information from PET and CT remains a major challenge. In this study, we propose vMambaX, a lightweight multimodal framework integrating PET and CT scan images through a Context-Gated Cross-Modal Perception Module (CGM). Built on the Visual Mamba architecture, vMambaX adaptively enhances inter-modality feature interaction, emphasizing informative regions while suppressing noise. Evaluated on the PCLT20K dataset, the model outperforms baseline models while maintaining lower computational complexity. These results highlight the effectiveness of adaptive cross-modal gating for multimodal tumor segmentation and demonstrate the potential of vMambaX as an efficient and scalable framework for advanced lung cancer analysis. The code is available at https://github.com/arco-group/vMambaX.