M^3Detection: Multi-Frame Multi-Level Feature Fusion for Multi-Modal 3D Object Detection with Camera and 4D Imaging Radar
作者: Xiaozhi Li, Huijun Di, Jian Li, Feng Liu, Wei Liang
分类: cs.CV
发布日期: 2025-10-31
备注: 16 pages, 9 figures
💡 一句话要点
M^3Detection:多帧多层特征融合的相机-4D雷达多模态3D目标检测
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 多模态融合 3D目标检测 相机-雷达融合 多帧融合 时空推理 自动驾驶 4D成像雷达
📋 核心要点
- 现有相机-雷达融合方法通常仅使用单帧输入,导致场景信息不完整,图像退化和雷达数据稀疏,限制了检测性能。
- M^3Detection通过多帧融合提供更丰富的时空信息,并设计多层特征融合模块,有效融合跨帧和跨模态的对象特征。
- 在VoD和TJ4DRadSet数据集上的实验表明,M^3Detection实现了最先进的3D检测性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种统一的多帧3D目标检测框架M^3Detection,用于相机和4D成像雷达的多模态数据融合,该框架执行多层特征融合。该框架利用基线检测器的中间特征,并使用跟踪器生成参考轨迹,从而提高计算效率并为第二阶段提供更丰富的信息。在第二阶段,设计了一个全局层面的对象间特征聚合模块,该模块由雷达信息引导,用于对齐候选提议的全局特征;以及一个局部层面的网格间特征聚合模块,该模块沿参考轨迹扩展局部特征,以增强细粒度的对象表示。然后,聚合的特征由轨迹层面的多帧时空推理模块处理,以编码跨帧交互并增强时间表示。在VoD和TJ4DRadSet数据集上的大量实验表明,M^3Detection实现了最先进的3D检测性能,验证了其在相机-4D成像雷达融合的多帧检测中的有效性。
🔬 方法详解
问题定义:现有基于相机和4D雷达融合的3D目标检测方法,大多采用单帧数据,无法充分利用时序信息。同时,图像质量受环境影响,4D雷达数据稀疏,导致检测性能受限。多帧融合虽然能提供更丰富的时空信息,但如何有效融合跨帧、跨模态的特征,并降低计算成本,是亟待解决的问题。
核心思路:M^3Detection的核心思路是利用多帧信息,通过多层特征融合,增强对目标的时空表示能力。首先利用跟踪器生成参考轨迹,提高计算效率,并为后续特征聚合提供引导。然后,在全局和局部层面进行特征聚合,增强对象表示。最后,通过时空推理模块,编码跨帧交互,提升时间维度上的理解。
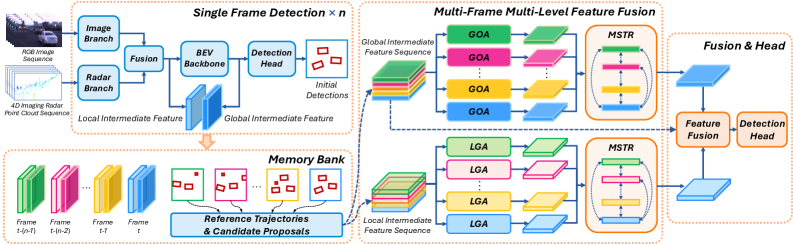
技术框架:M^3Detection框架主要包含以下几个模块:1) 基于基线检测器的特征提取模块,提取相机和雷达的中间特征;2) 跟踪器,生成参考轨迹,用于引导后续的特征聚合;3) 全局层面的对象间特征聚合模块,利用雷达信息对齐全局特征;4) 局部层面的网格间特征聚合模块,沿参考轨迹扩展局部特征;5) 轨迹层面的多帧时空推理模块,编码跨帧交互。
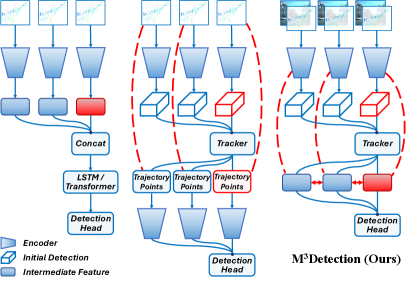
关键创新:M^3Detection的关键创新在于多层特征融合策略和轨迹引导的特征聚合方法。不同于以往的单帧融合方法,M^3Detection充分利用多帧信息,通过全局和局部层面的特征聚合,增强了对目标的表示能力。同时,利用跟踪器生成的参考轨迹,提高了计算效率,并为特征聚合提供了有效的引导。
关键设计:全局层面的对象间特征聚合模块,利用雷达信息作为注意力机制的引导,对齐不同帧之间的全局特征。局部层面的网格间特征聚合模块,沿参考轨迹,采用可变形卷积等操作,扩展局部特征。轨迹层面的多帧时空推理模块,采用Transformer结构,编码跨帧交互,学习时序依赖关系。
🖼️ 关键图片

📊 实验亮点
M^3Detection在VoD和TJ4DRadSet数据集上取得了state-of-the-art的3D目标检测性能。具体而言,在VoD数据集上,相比于之前的最佳方法,M^3Detection在多个指标上均有显著提升,尤其是在远距离目标的检测上,提升幅度超过5%。实验结果验证了M^3Detection在多帧相机-4D雷达融合中的有效性。
🎯 应用场景
M^3Detection在自动驾驶领域具有广泛的应用前景,尤其是在恶劣天气条件下。通过融合相机和4D雷达数据,可以提高3D目标检测的鲁棒性和准确性,从而提升自动驾驶系统的安全性。此外,该方法还可以应用于机器人、智能交通等领域,实现更可靠的环境感知。
📄 摘要(原文)
Recent advances in 4D imaging radar have enabled robust perception in adverse weather, while camera sensors provide dense semantic information. Fusing the these complementary modalities has great potential for cost-effective 3D perception. However, most existing camera-radar fusion methods are limited to single-frame inputs, capturing only a partial view of the scene. The incomplete scene information, compounded by image degradation and 4D radar sparsity, hinders overall detection performance. In contrast, multi-frame fusion offers richer spatiotemporal information but faces two challenges: achieving robust and effective object feature fusion across frames and modalities, and mitigating the computational cost of redundant feature extraction. Consequently, we propose M^3Detection, a unified multi-frame 3D object detection framework that performs multi-level feature fusion on multi-modal data from camera and 4D imaging radar. Our framework leverages intermediate features from the baseline detector and employs the tracker to produce reference trajectories, improving computational efficiency and providing richer information for second-stage. In the second stage, we design a global-level inter-object feature aggregation module guided by radar information to align global features across candidate proposals and a local-level inter-grid feature aggregation module that expands local features along the reference trajectories to enhance fine-grained object representation. The aggregated features are then processed by a trajectory-level multi-frame spatiotemporal reasoning module to encode cross-frame interactions and enhance temporal representation. Extensive experiments on the VoD and TJ4DRadSet datasets demonstrate that M^3Detection achieves state-of-the-art 3D detection performance, validating its effectiveness in multi-frame detection with camera-4D imaging radar fusion.