Generating Accurate and Detailed Captions for High-Resolution Images
作者: Hankyeol Lee, Gawon Seo, Kyounggyu Lee, Dogun Kim, Kyungwoo Song, Jiyoung Jung
分类: cs.CV, cs.AI
发布日期: 2025-10-31
备注: Work conducted in 2024; released for archival purposes
💡 一句话要点
提出一种多阶段流程,融合视觉-语言模型、大语言模型和目标检测,为高分辨率图像生成更准确、详细的描述。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像描述生成 高分辨率图像 视觉-语言模型 大语言模型 目标检测 多模态融合 幻觉抑制
📋 核心要点
- 现有视觉-语言模型在高分辨率图像描述生成中,因预训练数据分辨率低,易丢失细节和遗漏重要对象。
- 该论文提出融合视觉-语言模型、大语言模型和目标检测的多阶段流程,提升描述质量并减少幻觉。
- 实验表明,该方法在高分辨率图像描述生成中,能产生更详细、可靠的描述,并有效减少幻觉现象。
📝 摘要(中文)
视觉-语言模型(VLMs)通常难以生成高分辨率图像的准确和详细描述,因为它们通常在低分辨率输入(例如,224x224或336x336像素)上进行预训练。将高分辨率图像缩小到这些尺寸可能会导致视觉细节的丢失和重要对象的遗漏。为了解决这个限制,我们提出了一种新的流程,该流程集成了视觉-语言模型、大型语言模型(LLMs)和目标检测系统,以提高描述质量。我们提出的流程通过一种新颖的多阶段过程来改进描述。给定一个高分辨率图像,首先使用VLM生成初始描述,然后由LLM识别图像中的关键对象。LLM预测可能与已识别的关键对象共同出现的其他对象,并且这些预测由目标检测系统验证。未在初始描述中提及的新检测到的对象会进行集中的、特定于区域的描述,以确保它们被包含在内。此过程丰富了描述细节,同时通过删除对未检测到的对象的引用来减少幻觉。我们使用成对比较和来自大型多模态模型的定量评分,以及幻觉检测的基准来评估增强的描述。在高分辨率图像的精选数据集上的实验表明,我们的流程可以生成更详细和可靠的图像描述,同时有效地减少幻觉。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLMs)在高分辨率图像描述生成中表现不佳的问题。现有VLMs通常在低分辨率图像上预训练,直接应用于高分辨率图像时,需要进行降采样,导致细节丢失和重要物体被忽略,最终影响描述的准确性和完整性。
核心思路:论文的核心思路是利用大语言模型(LLMs)的推理能力和目标检测系统的精确性,对VLM生成的初始描述进行增强和修正。通过LLM推断可能存在的相关物体,并利用目标检测系统进行验证,从而补充VLM遗漏的细节,同时减少幻觉。
技术框架:该方法包含以下几个主要阶段: 1. 初始描述生成:使用VLM对高分辨率图像生成初始描述。 2. 关键对象识别:使用LLM从初始描述中识别关键对象。 3. 相关对象预测:LLM基于关键对象预测可能共同出现的其他对象。 4. 对象检测验证:使用目标检测系统验证LLM预测的对象是否存在于图像中。 5. 区域特定描述:对于检测到但未在初始描述中提及的对象,进行区域特定描述,并将其融入最终描述。 6. 幻觉抑制:删除描述中提及但未检测到的对象,减少幻觉。
关键创新:该方法最重要的创新点在于融合了VLM、LLM和目标检测系统,形成一个互补的流程。LLM的推理能力用于扩展描述的范围,目标检测系统用于保证描述的准确性,从而克服了VLM在高分辨率图像描述生成中的局限性。
关键设计:论文中没有明确提及关键的参数设置、损失函数或网络结构等技术细节。但流程中的各个模块,如VLM、LLM和目标检测器的选择,以及区域特定描述的实现方式,都会影响最终的描述质量。具体实现细节未知。
🖼️ 关键图片

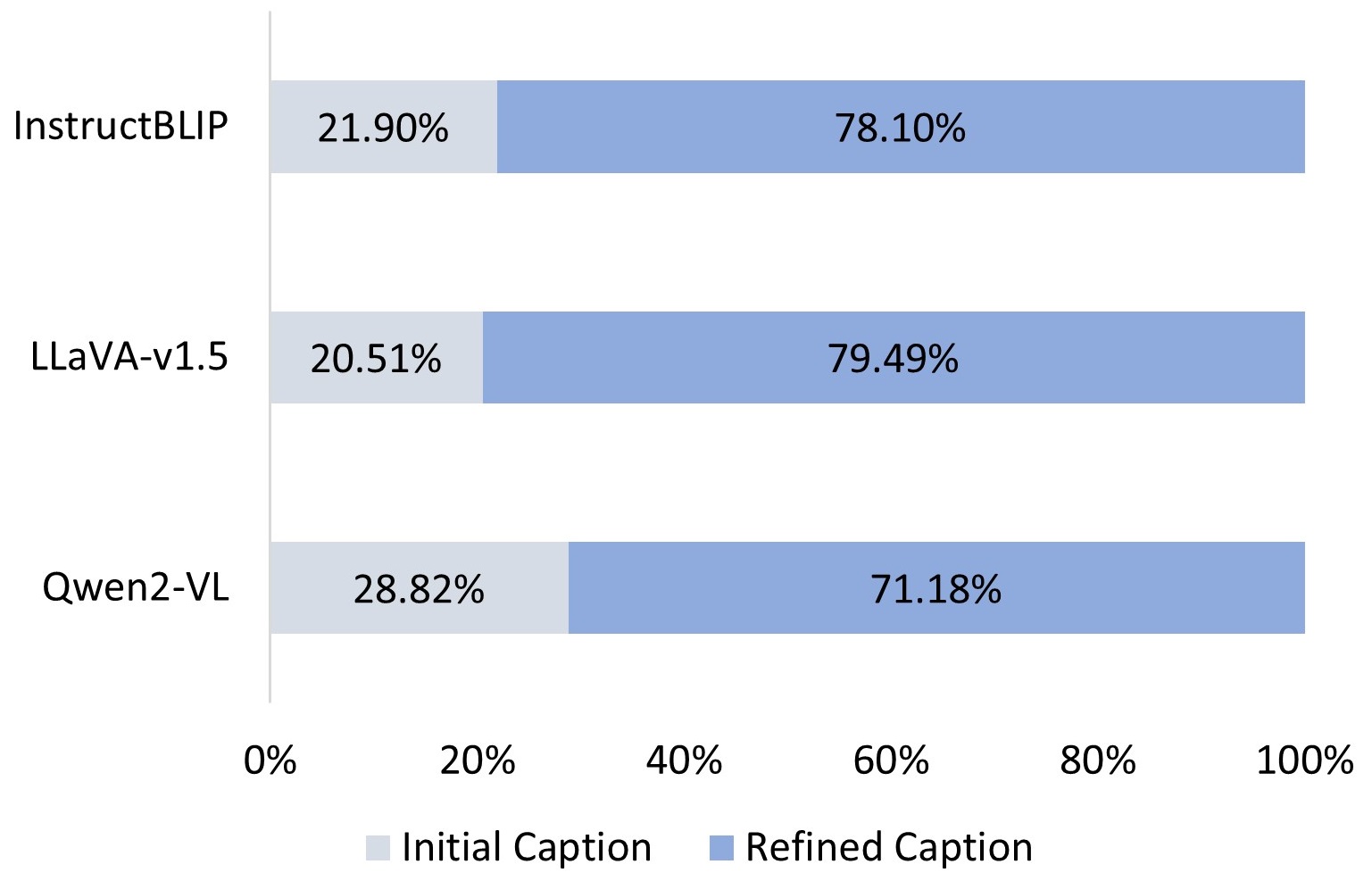

📊 实验亮点
实验结果表明,该方法能够生成更详细和可靠的图像描述,同时有效地减少幻觉。通过与其他基线方法进行对比,该方法在描述的准确性和完整性方面均取得了显著提升。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可广泛应用于智能相册、图像搜索引擎、辅助视觉等领域。通过生成更准确、详细的图像描述,可以提升用户体验,帮助视障人士理解图像内容,并为图像相关任务提供更丰富的信息。
📄 摘要(原文)
Vision-language models (VLMs) often struggle to generate accurate and detailed captions for high-resolution images since they are typically pre-trained on low-resolution inputs (e.g., 224x224 or 336x336 pixels). Downscaling high-resolution images to these dimensions may result in the loss of visual details and the omission of important objects. To address this limitation, we propose a novel pipeline that integrates vision-language models, large language models (LLMs), and object detection systems to enhance caption quality. Our proposed pipeline refines captions through a novel, multi-stage process. Given a high-resolution image, an initial caption is first generated using a VLM, and key objects in the image are then identified by an LLM. The LLM predicts additional objects likely to co-occur with the identified key objects, and these predictions are verified by object detection systems. Newly detected objects not mentioned in the initial caption undergo focused, region-specific captioning to ensure they are incorporated. This process enriches caption detail while reducing hallucinations by removing references to undetected objects. We evaluate the enhanced captions using pairwise comparison and quantitative scoring from large multimodal models, along with a benchmark for hallucination detection. Experiments on a curated dataset of high-resolution images demonstrate that our pipeline produces more detailed and reliable image captions while effectively minimizing hallucinations.