SpinalSAM-R1: A Vision-Language Multimodal Interactive System for Spine CT Segmentation
作者: Jiaming Liu, Dingwei Fan, Junyong Zhao, Chunlin Li, Haipeng Si, Liang Sun
分类: cs.CV, cs.AI
发布日期: 2025-10-30
备注: 2 Tables,5 Figures,16 Equations
🔗 代码/项目: GITHUB
💡 一句话要点
SpinalSAM-R1:用于脊柱CT分割的视觉-语言多模态交互系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脊柱CT分割 视觉-语言模型 多模态交互 Segment Anything Model DeepSeek-R1
📋 核心要点
- 脊柱CT图像分割面临低对比度和复杂边界的挑战,现有方法需要大量标注且领域适应性差。
- SpinalSAM-R1通过微调SAM并结合DeepSeek-R1,利用解剖引导注意力机制和语义驱动交互协议,提升分割精度。
- 实验结果表明,SpinalSAM-R1实现了优越的分割性能,并开发了支持多种交互方式的PyQt5软件。
📝 摘要(中文)
脊柱及其邻近结构的CT图像分割是脊柱疾病诊断和治疗的关键步骤。然而,CT图像的分割受到低对比度和复杂椎体边界的阻碍。尽管诸如Segment Anything Model (SAM)等先进模型在各种分割任务中显示出潜力,但它们在脊柱CT成像中的性能受到高标注需求和较差领域适应性的限制。为了解决这些限制,我们提出SpinalSAM-R1,一个多模态视觉-语言交互系统,它集成了微调的SAM与DeepSeek-R1,用于脊柱CT图像分割。具体来说,我们的SpinalSAM-R1引入了一种解剖引导的注意力机制来提高脊柱分割性能,以及一个由DeepSeek-R1驱动的语义驱动的交互协议,从而实现自然语言引导的细化。SpinalSAM-R1使用低秩适应(LoRA)进行高效的适应。我们在脊柱CT图像上验证了SpinalSAM-R1。实验结果表明,我们的方法实现了优越的分割性能。同时,我们开发了一个基于PyQt5的交互式软件,它支持点、框和基于文本的提示。该系统支持11个临床操作,解析精度为94.3%,响应时间低于800毫秒。该软件已在https://github.com/6jm233333/spinalsam-r1上发布。
🔬 方法详解
问题定义:论文旨在解决脊柱CT图像分割问题,现有方法如直接应用SAM模型,面临标注成本高、领域适应性差的问题,难以准确分割低对比度和复杂边界的脊柱结构。因此,需要一种能够有效利用少量标注信息,并能结合临床医生知识进行交互式分割的方法。
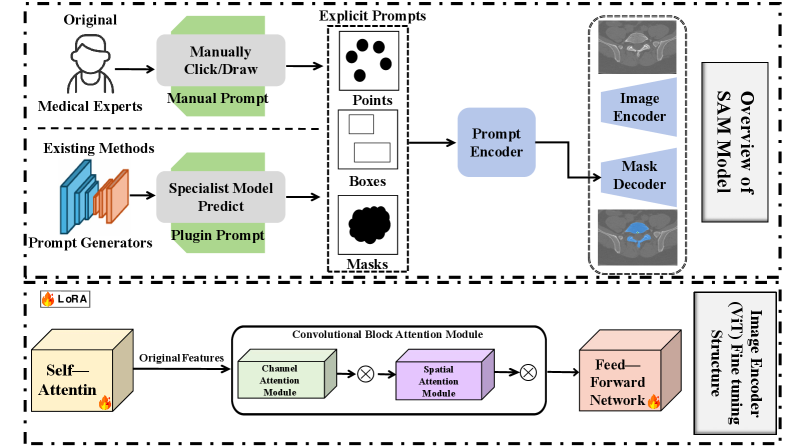
核心思路:论文的核心思路是将预训练的SAM模型与大型语言模型DeepSeek-R1相结合,通过微调SAM模型使其适应脊柱CT图像分割任务,并利用DeepSeek-R1的语义理解能力,实现基于自然语言的交互式分割。解剖引导的注意力机制用于增强模型对脊柱结构的关注。
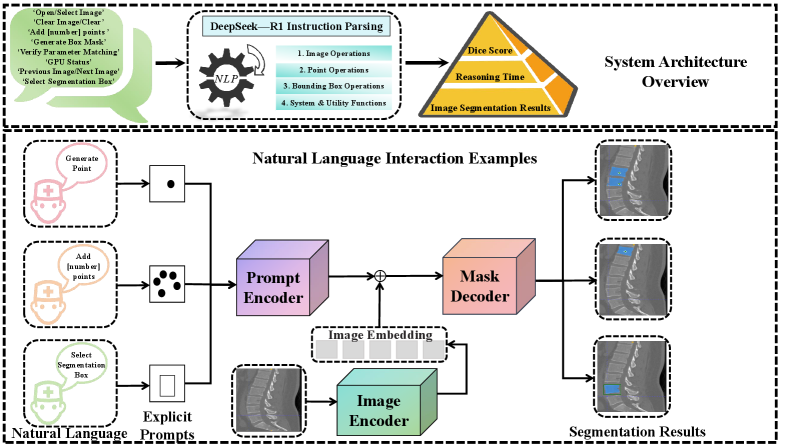
技术框架:SpinalSAM-R1系统包含以下主要模块:1) 微调的SAM模型,用于初始分割;2) 解剖引导的注意力模块,用于提高分割精度;3) DeepSeek-R1驱动的语义交互模块,用于根据用户输入的自然语言提示进行分割结果的细化。整个流程为:用户输入图像和提示(点、框或文本),SAM模型生成初始分割结果,解剖引导注意力模块优化分割,语义交互模块根据文本提示进一步细化分割结果。
关键创新:论文的关键创新在于:1) 提出了一种解剖引导的注意力机制,能够有效提升脊柱结构的分割精度;2) 将大型语言模型DeepSeek-R1引入到医学图像分割任务中,实现了基于自然语言的交互式分割,降低了对专业标注人员的依赖。与现有方法相比,SpinalSAM-R1能够更好地利用临床医生的知识,实现更精确的分割。
关键设计:SpinalSAM-R1使用LoRA(Low-Rank Adaptation)进行高效的微调,降低了计算成本。解剖引导的注意力模块的具体实现细节(例如注意力权重的计算方式)以及DeepSeek-R1的prompt设计(如何将自然语言提示转化为模型可理解的输入)是关键的设计细节,但论文摘要中未详细说明。
🖼️ 关键图片

📊 实验亮点
SpinalSAM-R1在脊柱CT图像分割任务上取得了优越的性能,但具体的性能指标和对比基线未在摘要中明确给出。该系统开发的PyQt5交互式软件支持11个临床操作,解析精度达到94.3%,响应时间低于800毫秒,表明该系统具有良好的实用性和交互性。
🎯 应用场景
SpinalSAM-R1可应用于脊柱疾病的诊断、手术规划和术后评估等多个临床场景。通过提供精确的脊柱结构分割,该系统能够辅助医生进行更准确的诊断,制定更合理的手术方案,并评估手术效果。该研究有望提高脊柱疾病的诊疗水平,并降低对专业标注人员的依赖。
📄 摘要(原文)
The anatomical structure segmentation of the spine and adjacent structures from computed tomography (CT) images is a key step for spinal disease diagnosis and treatment. However, the segmentation of CT images is impeded by low contrast and complex vertebral boundaries. Although advanced models such as the Segment Anything Model (SAM) have shown promise in various segmentation tasks, their performance in spinal CT imaging is limited by high annotation requirements and poor domain adaptability. To address these limitations, we propose SpinalSAM-R1, a multimodal vision-language interactive system that integrates a fine-tuned SAM with DeepSeek-R1, for spine CT image segmentation. Specifically, our SpinalSAM-R1 introduces an anatomy-guided attention mechanism to improve spine segmentation performance, and a semantics-driven interaction protocol powered by DeepSeek-R1, enabling natural language-guided refinement. The SpinalSAM-R1 is fine-tuned using Low-Rank Adaptation (LoRA) for efficient adaptation. We validate our SpinalSAM-R1 on the spine anatomical structure with CT images. Experimental results suggest that our method achieves superior segmentation performance. Meanwhile, we develop a PyQt5-based interactive software, which supports point, box, and text-based prompts. The system supports 11 clinical operations with 94.3\% parsing accuracy and sub-800 ms response times. The software is released on https://github.com/6jm233333/spinalsam-r1.