Are Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
作者: Ziyu Guo, Xinyan Chen, Renrui Zhang, Ruichuan An, Yu Qi, Dongzhi Jiang, Xiangtai Li, Manyuan Zhang, Hongsheng Li, Pheng-Ann Heng
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-10-30
备注: Project Page: https://video-cof.github.io
💡 一句话要点
评估视频模型零样本推理能力:提出MME-CoF基准并分析Veo-3的局限性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 视频模型 零样本推理 视觉推理 MME-CoF基准 Veo-3 因果推理 几何约束
📋 核心要点
- 现有视频生成模型展现出强大的视觉感知能力,但其在复杂推理任务中的表现尚不明确,需要系统性评估。
- 论文通过构建MME-CoF基准,针对空间、几何、物理等12个维度,对视频模型Veo-3的推理能力进行全面评估。
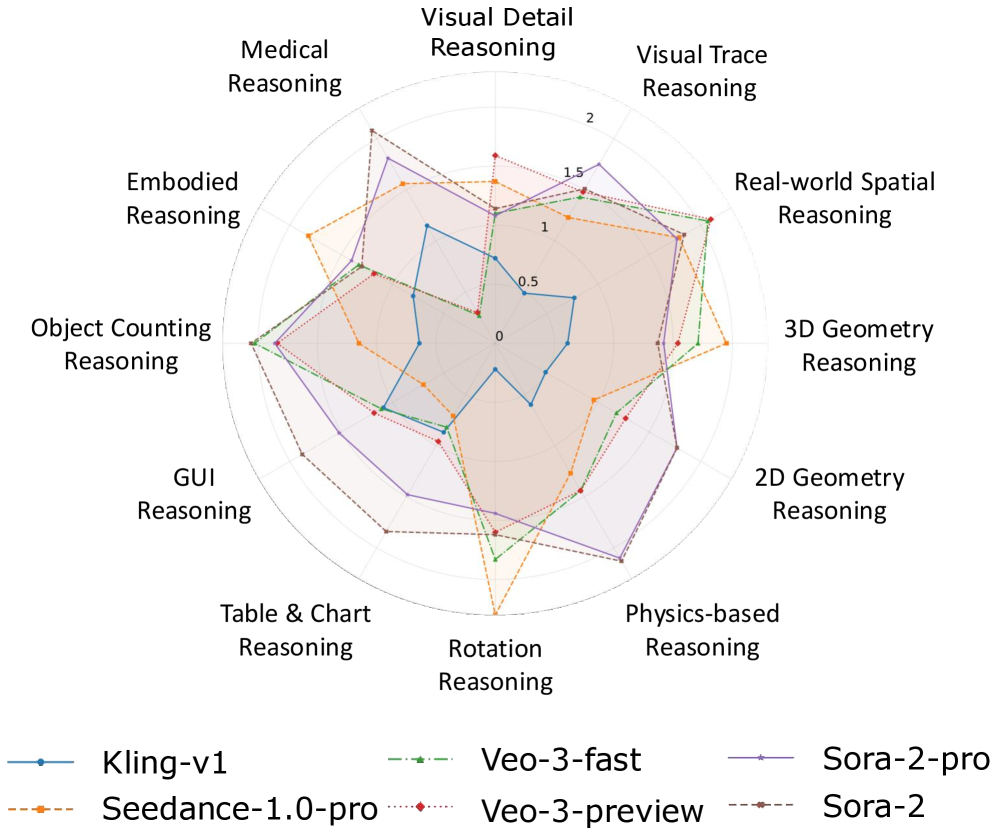
- 实验表明,Veo-3在短时程空间连贯性方面表现良好,但在长时程因果推理和抽象逻辑方面存在局限性。
📝 摘要(中文)
最近的视频生成模型能够产生高保真、时间连贯的视频,表明它们可能编码了大量的世界知识。除了逼真的合成之外,它们还表现出视觉感知、建模和操作的新兴行为。然而,一个重要的问题仍然存在:视频模型是否已准备好在具有挑战性的视觉推理场景中充当零样本推理器?在这项工作中,我们进行了一项实证研究,以全面调查这个问题,重点关注领先且流行的Veo-3。我们评估了它在12个维度上的推理行为,包括空间、几何、物理、时间和具身逻辑,系统地描述了它的优势和失败模式。为了标准化这项研究,我们将评估数据整理成MME-CoF,这是一个紧凑的基准,可以对帧链(CoF)推理进行深入而彻底的评估。我们的研究结果表明,虽然当前的视频模型在短时程空间连贯性、细粒度 grounding 和局部一致的动态方面表现出有希望的推理模式,但它们在长时程因果推理、严格的几何约束和抽象逻辑方面仍然受到限制。总的来说,它们还不能作为独立的零样本推理器,但作为专用推理模型的补充视觉引擎,表现出令人鼓舞的迹象。
🔬 方法详解
问题定义:论文旨在评估当前先进的视频生成模型(如Veo-3)是否具备在复杂视觉推理场景中进行零样本推理的能力。现有方法缺乏对视频模型推理能力的系统性评估,难以了解其优势和局限性。
核心思路:论文的核心思路是通过构建一个专门的评估基准(MME-CoF),并设计一系列具有挑战性的推理任务,来系统性地测试视频模型在不同维度上的推理能力。通过观察模型在这些任务上的表现,可以深入了解其推理能力,并发现其潜在的局限性。
技术框架:论文的技术框架主要包括两个部分:一是MME-CoF基准的构建,二是基于MME-CoF对Veo-3进行评估。MME-CoF基准包含12个维度,涵盖空间、几何、物理、时间和具身逻辑等多个方面。评估过程通过设计不同的提示词,引导Veo-3生成视频,并分析生成的视频是否符合预期的推理结果。
关键创新:论文的关键创新在于提出了MME-CoF基准,这是一个专门用于评估视频模型推理能力的紧凑型基准。与现有的视频理解数据集相比,MME-CoF更加关注模型的推理能力,而不是简单的识别或分类。此外,论文还系统性地分析了Veo-3在不同维度上的推理能力,揭示了其优势和局限性。
关键设计:MME-CoF基准的关键设计在于其12个维度的划分,每个维度都对应着不同的推理能力。例如,空间维度考察模型对物体空间关系的理解,几何维度考察模型对几何约束的理解,物理维度考察模型对物理规律的理解。此外,论文还设计了一系列具有挑战性的推理任务,例如长时程因果推理和抽象逻辑推理,以更全面地评估模型的推理能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Veo-3在短时程空间连贯性、细粒度 grounding 和局部一致的动态方面表现出较好的推理能力。然而,在长时程因果推理、严格的几何约束和抽象逻辑方面,Veo-3的表现仍然有限。MME-CoF基准的构建为后续研究提供了标准化的评估工具。
🎯 应用场景
该研究成果可应用于视频生成模型的改进和评估,帮助研究人员更好地了解模型的推理能力,并针对性地进行优化。此外,该研究还可以促进视频模型在机器人、自动驾驶等领域的应用,使其能够更好地理解和推理周围环境。
📄 摘要(原文)
Recent video generation models can produce high-fidelity, temporally coherent videos, indicating that they may encode substantial world knowledge. Beyond realistic synthesis, they also exhibit emerging behaviors indicative of visual perception, modeling, and manipulation. Yet, an important question still remains: Are video models ready to serve as zero-shot reasoners in challenging visual reasoning scenarios? In this work, we conduct an empirical study to comprehensively investigate this question, focusing on the leading and popular Veo-3. We evaluate its reasoning behavior across 12 dimensions, including spatial, geometric, physical, temporal, and embodied logic, systematically characterizing both its strengths and failure modes. To standardize this study, we curate the evaluation data into MME-CoF, a compact benchmark that enables in-depth and thorough assessment of Chain-of-Frame (CoF) reasoning. Our findings reveal that while current video models demonstrate promising reasoning patterns on short-horizon spatial coherence, fine-grained grounding, and locally consistent dynamics, they remain limited in long-horizon causal reasoning, strict geometric constraints, and abstract logic. Overall, they are not yet reliable as standalone zero-shot reasoners, but exhibit encouraging signs as complementary visual engines alongside dedicated reasoning models. Project page: https://video-cof.github.io