All You Need for Object Detection: From Pixels, Points, and Prompts to Next-Gen Fusion and Multimodal LLMs/VLMs in Autonomous Vehicles
作者: Sayed Pedram Haeri Boroujeni, Niloufar Mehrabi, Hazim Alzorgan, Mahlagha Fazeli, Abolfazl Razi
分类: cs.CV
发布日期: 2025-10-30 (更新: 2025-12-02)
💡 一句话要点
面向自动驾驶,综述基于多模态LLM/VLM的下一代融合目标检测技术
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 目标检测 多模态融合 视觉-语言模型 大型语言模型 传感器融合 Transformer 深度学习
📋 核心要点
- 现有自动驾驶目标检测方法在多模态感知、上下文推理和协同智能方面存在知识碎片化的问题,限制了其性能。
- 该综述着重分析了视觉-语言模型(VLMs)、大型语言模型(LLMs)和生成式AI等新兴范式在自动驾驶目标检测中的应用。
- 该综述系统地回顾了自动驾驶车辆的传感器及其融合策略,并对数据集进行了结构化分类和交叉分析。
📝 摘要(中文)
自动驾驶汽车(AVs)正通过智能感知、决策和控制系统的进步改变交通运输的未来。然而,它们的成功与一项核心能力息息相关,即在复杂和多模态环境中可靠的目标检测。尽管计算机视觉(CV)和人工智能(AI)的最新突破推动了显著的进展,但该领域仍然面临着一个关键挑战,即知识仍然分散在多模态感知、上下文推理和协同智能中。本综述通过对AV中目标检测的前瞻性分析来弥合这一差距,强调了视觉-语言模型(VLMs)、大型语言模型(LLMs)和生成式AI等新兴范式,而不是重新审视过时的技术。我们首先系统地回顾了AV传感器的基本频谱(摄像头、超声波、激光雷达和雷达)及其融合策略,不仅强调了它们在动态驾驶环境中的能力和局限性,还强调了它们与LLM/VLM驱动的感知框架集成的潜力。接下来,我们介绍了一种结构化的AV数据集分类,它超越了简单的数据集集合,定位了自我车辆、基于基础设施和协同数据集(例如,V2V、V2I、V2X、I2I),然后对数据结构和特征进行交叉分析。最后,我们分析了最先进的检测方法,从2D和3D流水线到混合传感器融合,特别关注由视觉Transformer(ViT)、大型和小型语言模型(SLM)以及VLM驱动的新兴Transformer驱动方法。通过综合这些观点,我们的综述提供了一个关于当前能力、开放挑战和未来机遇的清晰路线图。
🔬 方法详解
问题定义:自动驾驶车辆需要在复杂和多变的环境中进行可靠的目标检测,而现有的方法在多模态数据融合、上下文理解和协同感知方面存在不足,导致检测精度和鲁棒性受限。知识碎片化是阻碍该领域发展的关键问题。
核心思路:该综述的核心思路是整合计算机视觉、自然语言处理和多传感器融合领域的最新进展,特别是关注视觉-语言模型(VLMs)和大型语言模型(LLMs)在自动驾驶目标检测中的应用。通过分析这些新兴技术,为未来的研究方向提供指导。
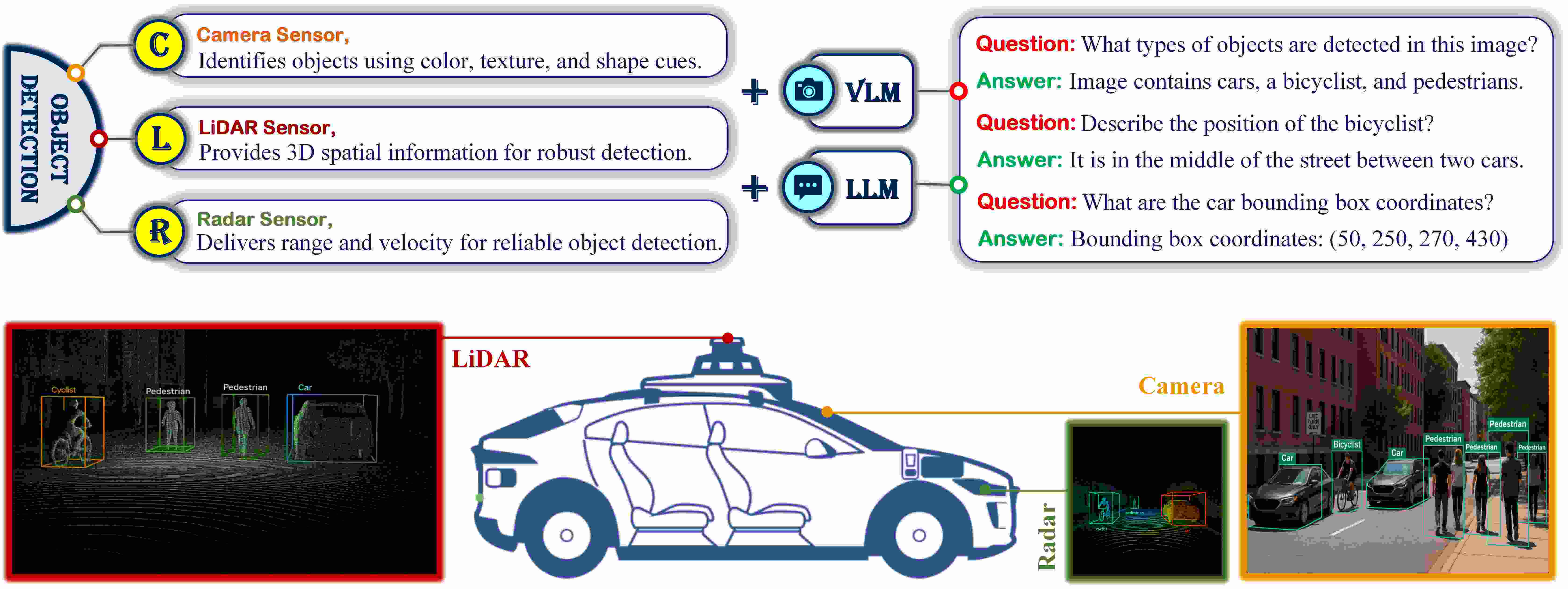
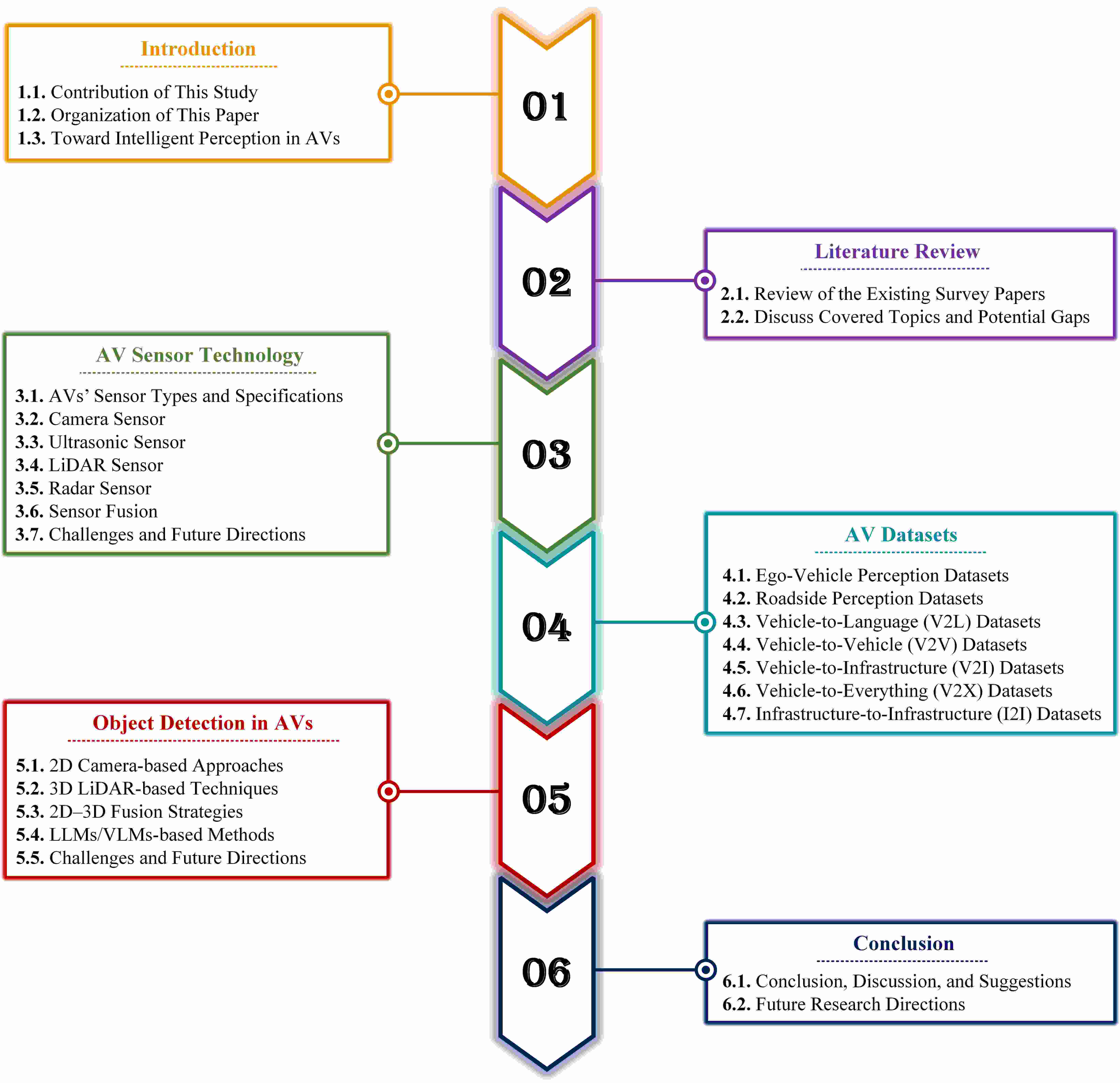
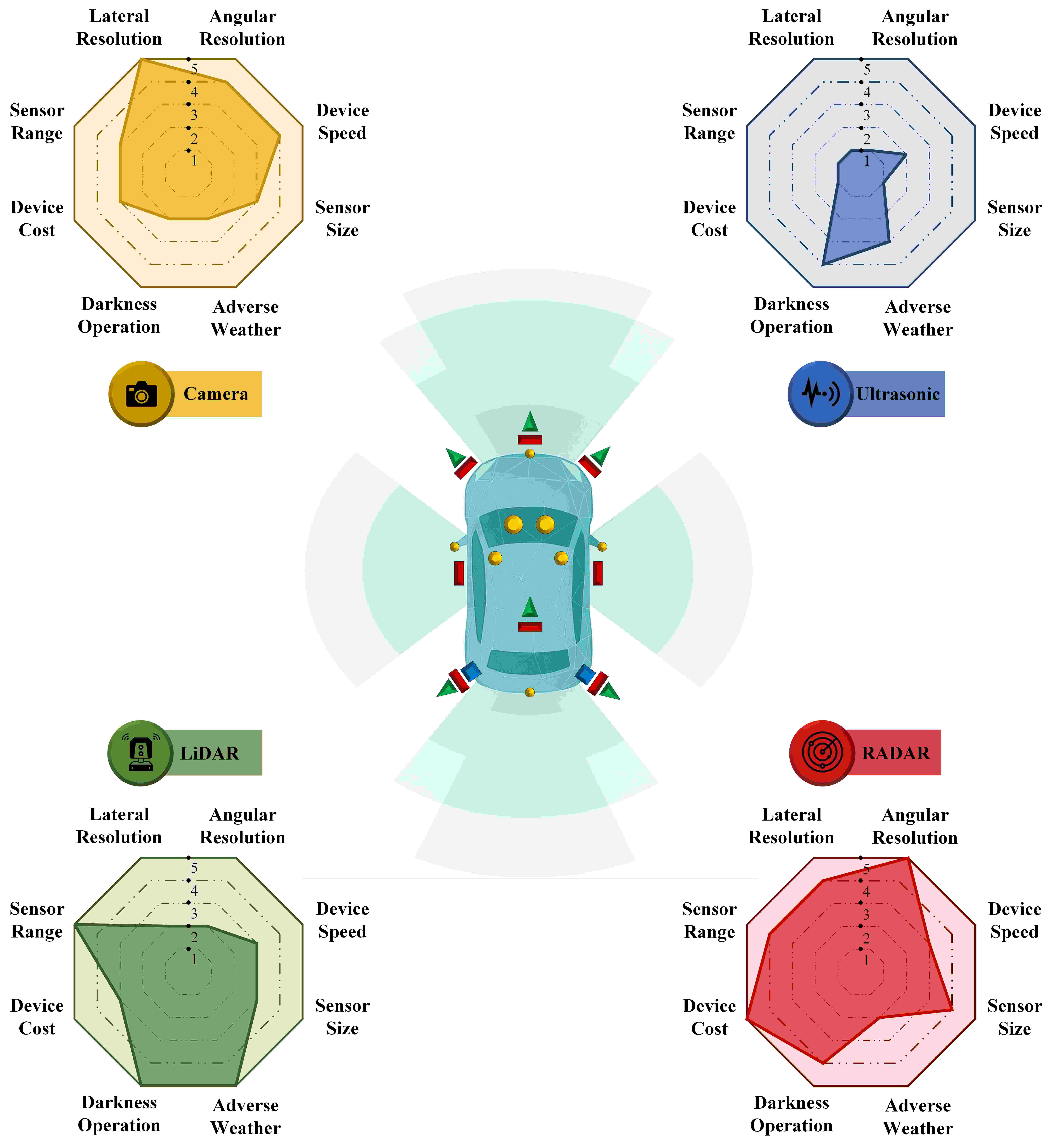
技术框架:该综述首先回顾了自动驾驶车辆常用的传感器类型(摄像头、超声波、激光雷达、雷达)及其融合策略。然后,对现有的自动驾驶数据集进行了结构化分类,包括自我车辆数据集、基于基础设施的数据集和协同数据集。最后,分析了2D、3D和混合传感器融合的目标检测方法,重点关注基于Transformer的模型,如ViT、LLM和VLM。
关键创新:该综述的关键创新在于它将视觉-语言模型和大型语言模型引入到自动驾驶目标检测领域,并分析了它们在多模态数据融合和上下文理解方面的潜力。此外,该综述还对现有的自动驾驶数据集进行了全面的分类和分析,为研究人员提供了有价值的资源。
关键设计:该综述没有提出新的算法或模型,而是对现有技术进行了系统的回顾和分析。它强调了Transformer架构在目标检测中的重要性,并讨论了如何利用LLM和VLM来提高检测性能。具体的技术细节包括不同传感器融合策略的优缺点、不同数据集的特点以及各种Transformer模型的适用性。
🖼️ 关键图片
📊 实验亮点
该综述全面回顾了自动驾驶目标检测领域的最新进展,特别是对基于Transformer的视觉-语言模型和大型语言模型进行了深入分析。它强调了这些模型在多模态数据融合和上下文理解方面的潜力,并为未来的研究方向提供了清晰的路线图。该综述还对现有的自动驾驶数据集进行了结构化分类,为研究人员提供了有价值的资源。
🎯 应用场景
该研究成果可应用于自动驾驶汽车、智能交通系统、机器人等领域,提升目标检测的准确性和鲁棒性,从而提高自动驾驶的安全性和可靠性。未来,基于多模态LLM/VLM的目标检测技术有望实现更高级别的自动驾驶功能,例如复杂场景理解和预测。
📄 摘要(原文)
Autonomous Vehicles (AVs) are transforming the future of transportation through advances in intelligent perception, decision-making, and control systems. However, their success is tied to one core capability, reliable object detection in complex and multimodal environments. While recent breakthroughs in Computer Vision (CV) and Artificial Intelligence (AI) have driven remarkable progress, the field still faces a critical challenge as knowledge remains fragmented across multimodal perception, contextual reasoning, and cooperative intelligence. This survey bridges that gap by delivering a forward-looking analysis of object detection in AVs, emphasizing emerging paradigms such as Vision-Language Models (VLMs), Large Language Models (LLMs), and Generative AI rather than re-examining outdated techniques. We begin by systematically reviewing the fundamental spectrum of AV sensors (camera, ultrasonic, LiDAR, and Radar) and their fusion strategies, highlighting not only their capabilities and limitations in dynamic driving environments but also their potential to integrate with recent advances in LLM/VLM-driven perception frameworks. Next, we introduce a structured categorization of AV datasets that moves beyond simple collections, positioning ego-vehicle, infrastructure-based, and cooperative datasets (e.g., V2V, V2I, V2X, I2I), followed by a cross-analysis of data structures and characteristics. Ultimately, we analyze cutting-edge detection methodologies, ranging from 2D and 3D pipelines to hybrid sensor fusion, with particular attention to emerging transformer-driven approaches powered by Vision Transformers (ViTs), Large and Small Language Models (SLMs), and VLMs. By synthesizing these perspectives, our survey delivers a clear roadmap of current capabilities, open challenges, and future opportunities.