CRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
作者: Jiaqi Wang, Xiao Yang, Kai Sun, Parth Suresh, Sanat Sharma, Adam Czyzewski, Derek Andersen, Surya Appini, Arkav Banerjee, Sajal Choudhary, Shervin Ghasemlou, Ziqiang Guan, Akil Iyer, Haidar Khan, Lingkun Kong, Roy Luo, Tiffany Ma, Zhen Qiao, David Tran, Wenfang Xu, Skyler Yeatman, Chen Zhou, Gunveer Gujral, Yinglong Xia, Shane Moon, Nicolas Scheffer, Nirav Shah, Eun Chang, Yue Liu, Florian Metze, Tammy Stark, Zhaleh Feizollahi, Andrea Jessee, Mangesh Pujari, Ahmed Aly, Babak Damavandi, Rakesh Wanga, Anuj Kumar, Rohit Patel, Wen-tau Yih, Xin Luna Dong
分类: cs.CV
发布日期: 2025-10-30
💡 一句话要点
提出CRAG-MM:一个用于可穿戴设备场景的多模态多轮对话RAG综合评测基准。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 多模态检索增强生成 可穿戴设备 评测基准 多轮对话 第一人称视角 知识图谱 图像理解
📋 核心要点
- 现有MM-RAG缺乏针对可穿戴设备场景的全面评测基准,限制了相关技术的发展。
- CRAG-MM通过构建包含真实场景图像和复杂问题的多模态多轮对话数据集,填补了这一空白。
- 实验表明,现有RAG方法在CRAG-MM上表现不佳,突显了该基准对未来研究的价值。
📝 摘要(中文)
本文提出了CRAG-MM,一个用于多模态多轮对话的综合RAG评测基准,尤其关注可穿戴设备场景。CRAG-MM包含6.5K个(图像,问题,答案)三元组和2K个基于视觉的多轮对话,覆盖13个领域,包括6.2K个模仿可穿戴设备拍摄的第一人称视角图像。问题经过精心设计,反映了真实场景和挑战,包括五种图像质量问题、六种问题类型、不同的实体流行度、不同的信息动态性和不同的对话轮数。设计了三个任务:单源增强、多源增强和多轮对话,每个任务都配有相关的检索语料库和API,用于图像-KG检索和网页检索。评估表明,简单的RAG方法在CRAG-MM的单轮和多轮问答中分别只有32%和43%的真实性,而最先进的行业解决方案具有相似的质量(32%/45%),表明仍有很大的改进空间。该基准已举办KDD Cup 2025,吸引了约1K参与者和5K提交,获胜解决方案将基线性能提高了28%,突显了其对推动该领域的早期影响。
🔬 方法详解
问题定义:论文旨在解决多模态检索增强生成(MM-RAG)领域缺乏针对可穿戴设备场景的综合评测基准的问题。现有方法难以评估在真实世界可穿戴设备应用中,RAG系统处理复杂视觉信息和多轮对话的能力。
核心思路:论文的核心思路是构建一个高质量、多样化的多模态多轮对话数据集CRAG-MM,该数据集模拟了可穿戴设备的使用场景,并包含了各种真实世界的挑战,例如图像质量问题、不同类型的问题、实体流行度差异以及信息动态性等。通过在该数据集上评估现有RAG方法,可以更全面地了解其性能瓶颈,并推动相关技术的发展。
技术框架:CRAG-MM基准包含三个主要任务:单源增强、多源增强和多轮对话。每个任务都配有相应的检索语料库和API,用于图像-KG检索和网页检索。用户可以使用这些API来构建自己的RAG系统,并在CRAG-MM上进行评估。整体流程包括:接收图像和问题,利用检索模块从知识图谱或网页中检索相关信息,然后利用生成模块生成答案。
关键创新:CRAG-MM的关键创新在于其数据集的设计,它专门针对可穿戴设备场景,并包含了各种真实世界的挑战。此外,该基准还提供了多种检索API,方便用户构建和评估不同的RAG系统。与现有数据集相比,CRAG-MM更注重模拟真实用户的使用场景和需求。
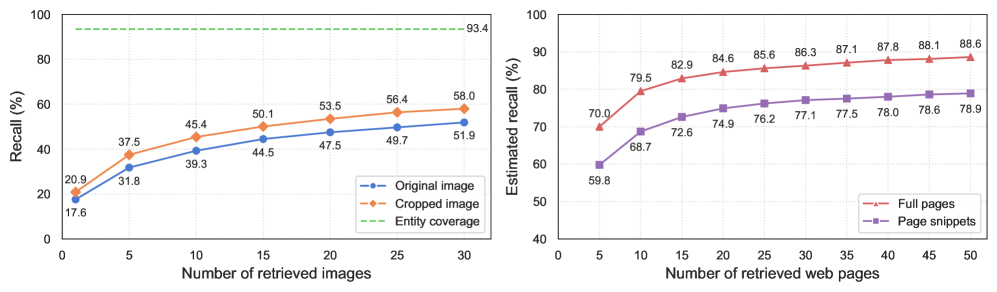
关键设计:CRAG-MM数据集包含6.5K个(图像,问题,答案)三元组和2K个基于视觉的多轮对话,覆盖13个领域。其中,6.2K个图像是第一人称视角图像,模拟了可穿戴设备的拍摄效果。问题类型包括识别、描述、推理等,涵盖了不同的信息需求。数据集还考虑了实体流行度和信息动态性等因素,以增加评测的难度和真实性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的RAG方法在CRAG-MM上的表现远未达到理想水平,单轮问答的真实性仅为32%,多轮问答的真实性为43%。即使是最先进的行业解决方案,其性能也与简单的RAG方法相当。KDD Cup 2025的获胜解决方案将基线性能提高了28%,证明了CRAG-MM对推动该领域发展的潜力。
🎯 应用场景
CRAG-MM的研究成果可应用于开发更智能、更实用的可穿戴设备应用,例如智能眼镜助手,可以帮助用户在日常生活中快速获取信息、解决问题。该基准还可以促进多模态RAG技术的发展,并应用于其他领域,如智能客服、教育等。
📄 摘要(原文)
Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.