JOGS: Joint Optimization of Pose Estimation and 3D Gaussian Splatting
作者: Xianben Yang, Yuxuan Li, Tao Wang, Tao Wang, Yi Jin, Yidong Li, Haibin Ling
分类: cs.CV
发布日期: 2025-10-30 (更新: 2026-01-15)
💡 一句话要点
提出JOGS,联合优化位姿估计和3D高斯溅射,无需预校准输入。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 新视角合成 位姿估计 3D高斯溅射 联合优化 可微渲染
📋 核心要点
- 传统新视角合成依赖COLMAP等位姿估计工具,存在计算瓶颈和误差传递问题。
- 提出JOGS框架,通过协同优化3D高斯点和相机位姿,实现场景重建和位姿估计的同步提升。
- 实验表明,该方法在重建质量上优于无COLMAP技术,甚至超越了基于COLMAP的基线。
📝 摘要(中文)
本文提出了一种统一的框架,用于联合优化3D高斯点和相机位姿,无需预校准输入,从而解决传统新视角合成方法对COLMAP等外部相机位姿估计工具的依赖问题,这些工具常常引入计算瓶颈并传播误差。该方法通过一种新颖的协同优化策略迭代地细化3D高斯参数并更新相机位姿,确保场景重建保真度和位姿估计精度的同步提升。其关键创新在于将联合优化解耦为两个交错的阶段:首先,通过固定位姿的可微渲染更新3D高斯参数;其次,使用定制的3D光流算法细化相机位姿,该算法结合了几何和光度约束。这种公式逐步减少了投影误差,特别是在具有大视点变化和稀疏特征分布的挑战性场景中,传统方法在这些场景中表现不佳。在多个数据集上的大量评估表明,该方法在重建质量方面显著优于现有的无COLMAP技术,并且在一般情况下也优于标准的基于COLMAP的基线。
🔬 方法详解
问题定义:传统新视角合成方法依赖于外部相机位姿估计工具,如COLMAP。这些工具计算成本高昂,且估计误差会传递到后续的渲染过程中,影响最终的合成质量。尤其是在视角变化大、特征稀疏的场景中,位姿估计的准确性会显著下降,导致重建效果不佳。
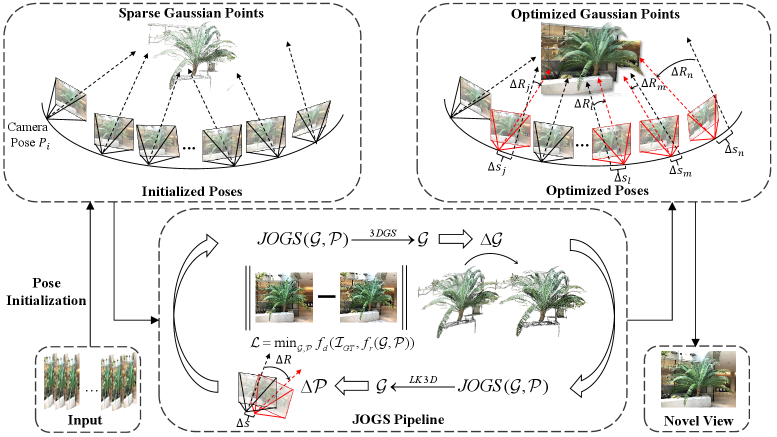
核心思路:JOGS的核心思想是将相机位姿估计和3D场景重建(使用3D高斯溅射表示)进行联合优化。通过迭代地更新3D高斯参数和相机位姿,使得两者相互促进,共同提升。避免了对预先计算的、可能存在误差的位姿的依赖。
技术框架:JOGS框架包含两个主要阶段,这两个阶段交替进行:1) 3D高斯参数更新阶段:在该阶段,相机位姿固定,利用可微渲染技术,根据图像和当前位姿,优化3D高斯参数,以最小化渲染图像与真实图像之间的差异。2) 相机位姿更新阶段:在该阶段,3D高斯参数固定,利用定制的3D光流算法,根据几何和光度约束,优化相机位姿,以最小化投影误差。
关键创新:JOGS的关键创新在于将位姿估计和3D高斯溅射的优化过程进行了解耦,并通过交替迭代的方式进行联合优化。此外,定制的3D光流算法能够有效地利用几何和光度信息,提高位姿估计的准确性,尤其是在视角变化大和特征稀疏的场景中。与现有方法相比,JOGS无需预先计算的位姿,避免了误差传递,并且能够实现更高的重建质量。
关键设计:在3D高斯参数更新阶段,使用可微渲染技术,例如基于高斯分布的渲染方法,并采用合适的损失函数(如L1损失、SSIM损失等)来衡量渲染图像与真实图像之间的差异。在相机位姿更新阶段,定制的3D光流算法需要仔细设计几何和光度约束,例如,可以使用点到平面的距离作为几何约束,使用像素颜色差异作为光度约束。此外,还需要合理设置各个损失项的权重,以平衡不同约束之间的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,JOGS在多个数据集上显著优于现有的无COLMAP技术,在重建质量上取得了明显的提升。同时,JOGS在一般情况下也超越了标准的基于COLMAP的基线方法,证明了其在位姿估计和场景重建方面的优越性能。具体性能数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、虚拟现实/增强现实等领域。在这些应用中,准确的位姿估计和高质量的场景重建至关重要。JOGS方法无需预校准输入,能够适应各种环境,并提供更鲁棒和精确的场景表示,从而提升相关应用的性能和用户体验。
📄 摘要(原文)
Traditional novel view synthesis methods heavily rely on external camera pose estimation tools such as COLMAP, which often introduce computational bottlenecks and propagate errors. To address these challenges, we propose a unified framework that jointly optimizes 3D Gaussian points and camera poses without requiring pre-calibrated inputs. Our approach iteratively refines 3D Gaussian parameters and updates camera poses through a novel co-optimization strategy, ensuring simultaneous improvements in scene reconstruction fidelity and pose estimation accuracy. The key innovation lies in decoupling the joint optimization into two interleaved phases: first, updating 3D Gaussian parameters via differentiable rendering with fixed poses, and second, refining camera poses using a customized 3D optical flow algorithm that incorporates geometric and photometric constraints. This formulation progressively reduces projection errors, particularly in challenging scenarios with large viewpoint variations and sparse feature distributions, where traditional methods struggle. Extensive evaluations on multiple datasets demonstrate that our approach significantly outperforms existing COLMAP-free techniques in reconstruction quality, and also surpasses the standard COLMAP-based baseline in general.