OracleAgent: A Multimodal Reasoning Agent for Oracle Bone Script Research
作者: Caoshuo Li, Zengmao Ding, Xiaobin Hu, Bang Li, Donghao Luo, Xu Peng, Taisong Jin, Yongge Liu, Shengwei Han, Jing Yang, Xiaoping He, Feng Gao, AndyPian Wu, SevenShu, Chaoyang Wang, Chengjie Wang
分类: cs.CV
发布日期: 2025-10-30
💡 一句话要点
OracleAgent:用于甲骨文研究的多模态推理Agent系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 甲骨文研究 多模态Agent 大型语言模型 知识库 信息检索
📋 核心要点
- 甲骨文研究面临释义流程复杂和信息检索效率低的挑战,现有方法难以有效整合多模态信息。
- OracleAgent通过集成甲骨文分析工具和构建领域知识库,利用大型语言模型实现甲骨文信息的结构化管理和检索。
- 实验表明,OracleAgent在多模态推理和生成任务中超越主流MLLM,并通过案例研究验证了其在辅助专家研究中的有效性。
📝 摘要(中文)
甲骨文(OBS)作为最早的文字系统之一,保存了古代文明的文化和知识遗产。然而,当前的甲骨文研究面临两大挑战:(1)甲骨文的释义涉及一个复杂的流程,包含多个串行和并行的子任务;(2)甲骨文信息组织和检索的效率仍然是一个关键瓶颈,学者们经常花费大量精力搜索、编译和管理相关资源。为了应对这些挑战,我们提出了OracleAgent,这是第一个为甲骨文相关信息的结构化管理和检索而设计的Agent系统。OracleAgent无缝集成了多种甲骨文分析工具,并由大型语言模型(LLM)提供支持,可以灵活地编排这些组件。此外,我们还构建了一个全面的、特定领域的多模态甲骨文知识库,该知识库是通过多年的数据收集、清洗和专家标注的严格过程构建的。该知识库包含超过140万张单字拓片图像和8万条释义文本。OracleAgent通过其多模态工具利用这些资源,以协助专家进行字符、文档、释义文本和拓片图像的检索任务。大量的实验表明,OracleAgent在一系列多模态推理和生成任务中取得了优异的性能,超过了领先的主流多模态大型语言模型(MLLM)(例如,GPT-4o)。此外,我们的案例研究表明,OracleAgent可以有效地协助领域专家,显著降低甲骨文研究的时间成本。这些结果表明,OracleAgent是朝着甲骨文辅助研究和自动释义系统的实际部署迈出的重要一步。
🔬 方法详解
问题定义:甲骨文研究面临的主要问题是甲骨文释义流程复杂,涉及多个串行和并行的子任务,并且甲骨文信息的组织和检索效率低下,学者需要花费大量时间搜索和整理相关资料。现有方法难以有效地整合多模态信息,无法满足甲骨文研究的需求。
核心思路:OracleAgent的核心思路是构建一个基于大型语言模型(LLM)的多模态Agent系统,该系统能够无缝集成多种甲骨文分析工具,并利用一个全面的、特定领域的多模态甲骨文知识库。通过这种方式,OracleAgent可以灵活地编排各种工具,并利用知识库中的信息,从而提高甲骨文研究的效率和准确性。
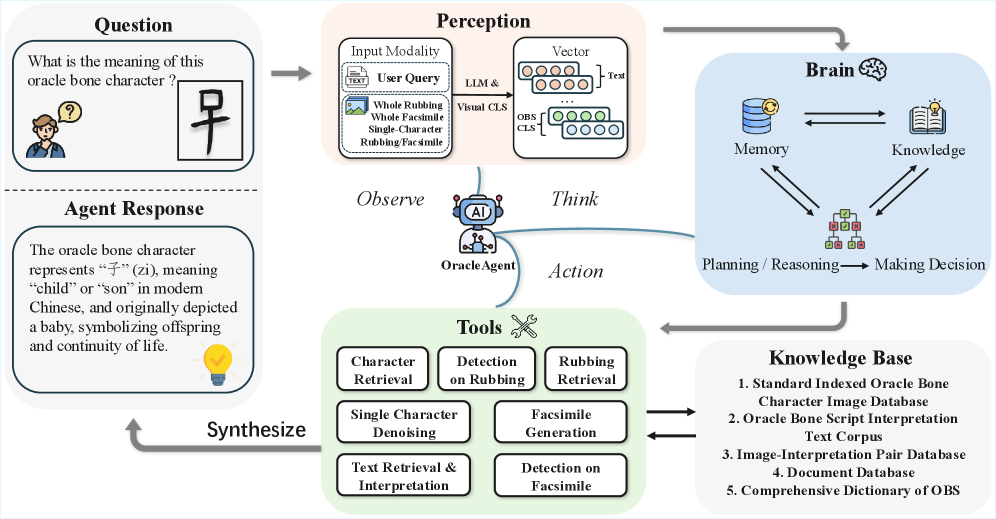
技术框架:OracleAgent的整体架构包含以下几个主要模块:(1) 多模态甲骨文知识库:包含超过140万张单字拓片图像和8万条释义文本;(2) 集成的甲骨文分析工具:包括字符识别、语义理解等工具;(3) 基于LLM的Agent:负责协调各个模块,并执行用户的查询和任务。整个流程包括用户输入查询,Agent解析查询并调用相应的工具和知识库,最后将结果返回给用户。
关键创新:OracleAgent最重要的技术创新点在于其将大型语言模型与特定领域的知识库和工具相结合,构建了一个专门用于甲骨文研究的Agent系统。与通用的多模态大型语言模型相比,OracleAgent能够更好地理解甲骨文的特点和研究需求,从而提供更准确和高效的服务。
关键设计:论文中没有详细描述关键的参数设置、损失函数、网络结构等技术细节。但可以推测,知识库的构建和维护、Agent的指令学习和工具调用策略、以及多模态信息的融合方式是关键的设计要素。具体的技术细节可能涉及图像处理、自然语言处理和知识图谱等领域的技术。
🖼️ 关键图片


📊 实验亮点
实验结果表明,OracleAgent在多模态推理和生成任务中表现优异,超越了GPT-4o等主流MLLM。案例研究表明,OracleAgent能够有效协助领域专家,显著降低甲骨文研究的时间成本。这些结果验证了OracleAgent在甲骨文研究中的实用价值。
🎯 应用场景
OracleAgent可应用于甲骨文研究的多个领域,包括甲骨文字符识别、释义、文献检索和知识管理。它能显著提高研究效率,降低时间成本,并促进甲骨文知识的传播和传承。未来,该系统有望扩展到其他古文字研究领域,为文化遗产的保护和研究做出贡献。
📄 摘要(原文)
As one of the earliest writing systems, Oracle Bone Script (OBS) preserves the cultural and intellectual heritage of ancient civilizations. However, current OBS research faces two major challenges: (1) the interpretation of OBS involves a complex workflow comprising multiple serial and parallel sub-tasks, and (2) the efficiency of OBS information organization and retrieval remains a critical bottleneck, as scholars often spend substantial effort searching for, compiling, and managing relevant resources. To address these challenges, we present OracleAgent, the first agent system designed for the structured management and retrieval of OBS-related information. OracleAgent seamlessly integrates multiple OBS analysis tools, empowered by large language models (LLMs), and can flexibly orchestrate these components. Additionally, we construct a comprehensive domain-specific multimodal knowledge base for OBS, which is built through a rigorous multi-year process of data collection, cleaning, and expert annotation. The knowledge base comprises over 1.4M single-character rubbing images and 80K interpretation texts. OracleAgent leverages this resource through its multimodal tools to assist experts in retrieval tasks of character, document, interpretation text, and rubbing image. Extensive experiments demonstrate that OracleAgent achieves superior performance across a range of multimodal reasoning and generation tasks, surpassing leading mainstream multimodal large language models (MLLMs) (e.g., GPT-4o). Furthermore, our case study illustrates that OracleAgent can effectively assist domain experts, significantly reducing the time cost of OBS research. These results highlight OracleAgent as a significant step toward the practical deployment of OBS-assisted research and automated interpretation systems.