Audio-Visual Speech Enhancement In Complex Scenarios With Separation And Dereverberation Joint Modeling
作者: Jiarong Du, Zhan Jin, Peijun Yang, Juan Liu, Zhuo Li, Xin Liu, Ming Li
分类: cs.SD, cs.CV, cs.MM, eess.AS
发布日期: 2025-10-29
💡 一句话要点
提出分离-去混响联合建模的AVSE系统,提升复杂场景语音质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频语音增强 语音分离 语音去混响 复杂声学环境 多模态学习
📋 核心要点
- 现有AVSE方法难以应对复杂声学环境下的干扰和混响,导致语音增强效果不佳。
- 论文提出“分离优先于去混响”的AVSE流水线,有效应对复杂声学环境。
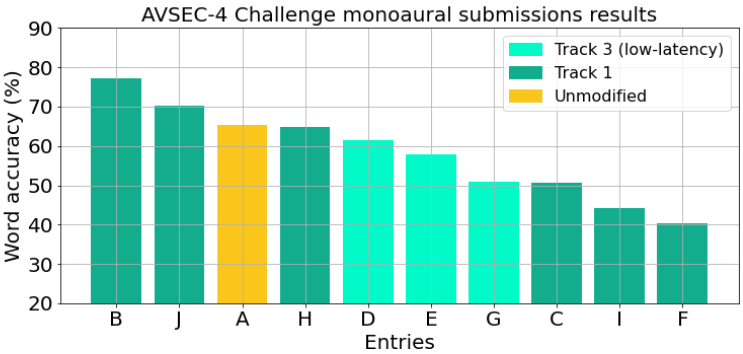
- 在AVSEC-4挑战赛中,该系统在客观指标和主观听力测试中均取得领先成绩。
📝 摘要(中文)
本文提出了一种有效的音视频语音增强(AVSE)系统,旨在复杂声学环境下提取目标说话人的语音。在实际场景中,通常存在各种干扰声音和混响,导致以往方法提取的语音感知质量较差。本文设计了一种“分离优先于去混响”的流水线,该流水线可以扩展到其他AVSE网络。该系统在第四届COGMHEAR音视频语音增强挑战赛(AVSEC)中进行了验证,在三个客观指标上均取得了优异的成绩,并在主观听力测试中获得了第一名。
🔬 方法详解
问题定义:音视频语音增强(AVSE)旨在利用视觉信息从混合音频中提取目标说话人的语音。然而,实际场景中存在多种干扰声音和混响,使得传统AVSE方法难以有效提取高质量的语音,导致感知质量下降。因此,如何在复杂声学环境下实现鲁棒的AVSE是本文要解决的问题。
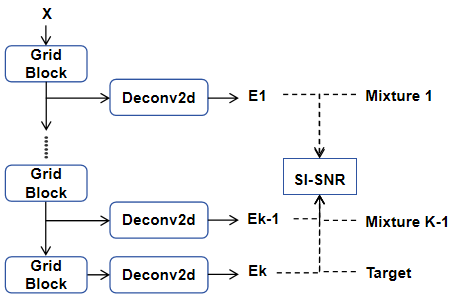
核心思路:本文的核心思路是采用“分离优先于去混响”的策略。首先,利用音视频信息将目标说话人的语音从混合音频中分离出来,降低干扰噪声的影响;然后,对分离后的语音进行去混响处理,进一步提升语音的清晰度和质量。这种策略能够有效应对复杂声学环境下的干扰和混响。
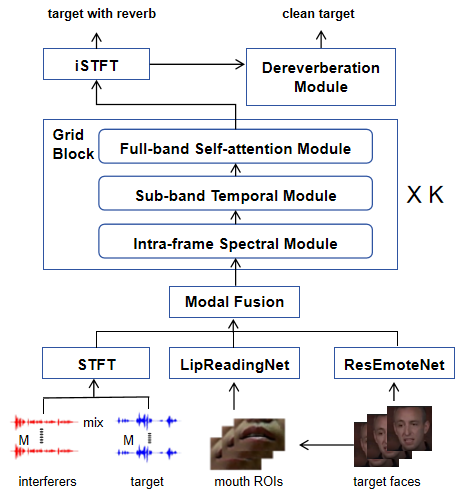
技术框架:该AVSE系统采用“分离优先于去混响”的流水线结构。首先,利用音视频信息进行语音分离,得到初步增强的语音信号。然后,对分离后的语音信号进行去混响处理,进一步提升语音质量。整个框架可以灵活地与其他AVSE网络结合使用。
关键创新:该论文的关键创新在于提出了“分离优先于去混响”的AVSE流水线。与传统的先去混响后分离的方法相比,该方法能够更好地应对复杂声学环境下的干扰和混响,从而提升语音增强的效果。这种策略的有效性已在实验中得到验证。
关键设计:具体的网络结构和损失函数等技术细节在论文中没有详细描述,属于未知信息。但“分离优先于去混响”的策略是该系统的核心设计理念。
🖼️ 关键图片
📊 实验亮点
该系统在AVSEC-4挑战赛中取得了显著成果,在三个客观指标上均表现出色,并在主观听力测试中获得第一名。这表明该系统在复杂声学环境下的语音增强性能优于其他方法,具有很强的实用价值。
🎯 应用场景
该研究成果可应用于各种实际场景,如视频会议、智能家居、车载语音助手等。通过提升复杂声学环境下的语音质量,可以改善用户体验,提高语音交互的可靠性。未来,该技术有望在助听器、语音识别等领域发挥重要作用。
📄 摘要(原文)
Audio-visual speech enhancement (AVSE) is a task that uses visual auxiliary information to extract a target speaker's speech from mixed audio. In real-world scenarios, there often exist complex acoustic environments, accompanied by various interfering sounds and reverberation. Most previous methods struggle to cope with such complex conditions, resulting in poor perceptual quality of the extracted speech. In this paper, we propose an effective AVSE system that performs well in complex acoustic environments. Specifically, we design a "separation before dereverberation" pipeline that can be extended to other AVSE networks. The 4th COGMHEAR Audio-Visual Speech Enhancement Challenge (AVSEC) aims to explore new approaches to speech processing in multimodal complex environments. We validated the performance of our system in AVSEC-4: we achieved excellent results in the three objective metrics on the competition leaderboard, and ultimately secured first place in the human subjective listening test.