Brain-IT: Image Reconstruction from fMRI via Brain-Interaction Transformer
作者: Roman Beliy, Amit Zalcher, Jonathan Kogman, Navve Wasserman, Michal Irani
分类: cs.CV, cs.AI, q-bio.NC
发布日期: 2025-10-29
💡 一句话要点
提出Brain-IT以解决fMRI图像重建的信度问题
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: fMRI重建 脑交互变换器 图像重建 功能集群 非侵入性神经成像 深度学习 扩散模型
📋 核心要点
- 现有的fMRI图像重建方法在忠实度上存在不足,无法准确反映人们所见的图像内容。
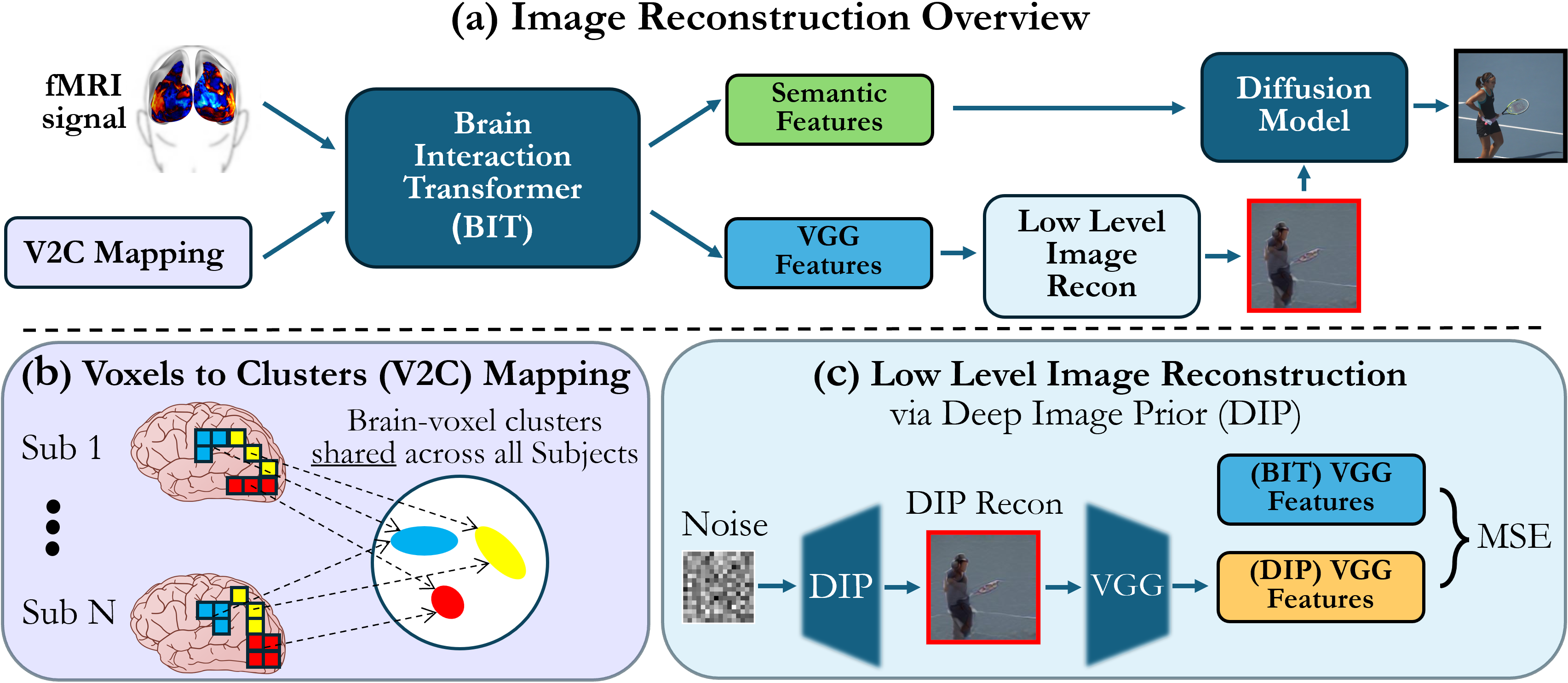
- 论文提出的Brain-IT通过脑交互变换器(BIT)实现功能相似脑体素的有效交互,提升图像重建的准确性。
- 实验结果表明,Brain-IT在图像重建的视觉效果和客观指标上均超越了当前最先进的方法,且数据需求显著降低。
📝 摘要(中文)
通过从fMRI脑部记录中重建人们所见图像,提供了一种非侵入性观察人脑的方式。尽管近期在扩散模型方面取得了一定进展,但现有方法往往缺乏对实际所见图像的忠实重建。我们提出了'Brain-IT',一种脑启发的方法,通过脑交互变换器(BIT)有效地处理功能相似脑体素之间的交互。这些功能集群被所有受试者共享,作为整合跨脑信息的基础。BIT预测两种互补的局部图像特征,指导图像重建,最终实现了对所见图像的忠实重建,并在视觉效果和标准客观指标上超越了当前的最先进方法。即使仅使用1小时的新受试者fMRI数据,我们的结果也与基于40小时完整录音的现有方法相当。
🔬 方法详解
问题定义:本论文旨在解决从fMRI脑部记录中重建图像的信度问题。现有方法在重建过程中常常无法忠实反映实际所见图像,导致重建效果不佳。
核心思路:论文的核心思路是通过脑交互变换器(BIT)实现功能相似脑体素之间的有效交互,利用共享的功能集群来整合信息,从而提升图像重建的准确性和忠实度。
技术框架:整体架构包括功能集群的构建、BIT的设计与训练、以及图像特征的预测。BIT通过预测高层语义特征和低层结构特征来引导扩散模型进行图像重建。
关键创新:最重要的技术创新在于BIT的设计,它允许信息直接从脑体素集群流向局部图像特征,显著提高了重建的信度和准确性。这与现有方法的设计思路有本质区别。
关键设计:在模型设计中,所有组件均为所有集群和受试者共享,允许在有限数据下进行高效训练。BIT预测的高层和低层特征分别引导扩散模型的语义内容和图像的粗略布局。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果显示,Brain-IT在图像重建的视觉效果和标准客观指标上超越了当前最先进的方法,且仅需1小时的fMRI数据便可达到与基于40小时录音的现有方法相当的效果,显示出显著的效率提升。
🎯 应用场景
该研究的潜在应用领域包括神经科学、心理学和人机交互等。通过非侵入性地重建人类所见图像,能够为理解人脑的视觉处理机制提供新的视角,同时也可能在医疗诊断和脑机接口等领域产生实际价值。
📄 摘要(原文)
Reconstructing images seen by people from their fMRI brain recordings provides a non-invasive window into the human brain. Despite recent progress enabled by diffusion models, current methods often lack faithfulness to the actual seen images. We present "Brain-IT", a brain-inspired approach that addresses this challenge through a Brain Interaction Transformer (BIT), allowing effective interactions between clusters of functionally-similar brain-voxels. These functional-clusters are shared by all subjects, serving as building blocks for integrating information both within and across brains. All model components are shared by all clusters & subjects, allowing efficient training with a limited amount of data. To guide the image reconstruction, BIT predicts two complementary localized patch-level image features: (i)high-level semantic features which steer the diffusion model toward the correct semantic content of the image; and (ii)low-level structural features which help to initialize the diffusion process with the correct coarse layout of the image. BIT's design enables direct flow of information from brain-voxel clusters to localized image features. Through these principles, our method achieves image reconstructions from fMRI that faithfully reconstruct the seen images, and surpass current SotA approaches both visually and by standard objective metrics. Moreover, with only 1-hour of fMRI data from a new subject, we achieve results comparable to current methods trained on full 40-hour recordings.