Informative Sample Selection Model for Skeleton-based Action Recognition with Limited Training Samples
作者: Zhigang Tu, Zhengbo Zhang, Jia Gong, Junsong Yuan, Bo Du
分类: cs.CV
发布日期: 2025-10-29
备注: Accepted by IEEE Transactions on Image Processing (TIP), 2025
💡 一句话要点
提出基于MDP的骨骼动作识别信息样本选择模型,提升有限样本下的识别精度。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 骨骼动作识别 半监督学习 主动学习 马尔可夫决策过程 强化学习 双曲空间 有限样本学习
📋 核心要点
- 现有主动学习方法在半监督3D动作识别中,倾向于选择最具代表性的样本,但这些样本可能对模型提升有限。
- 论文将半监督3D动作识别中的主动学习过程建模为MDP,训练信息样本选择模型,更智能地选择对模型提升大的样本。
- 通过双曲空间投影增强表征能力,并引入元调优加速部署。实验表明,该方法在多个数据集上有效。
📝 摘要(中文)
本文旨在解决有限训练样本下基于骨骼的动作识别问题,即半监督3D动作识别。针对现有主动学习方法选择最具代表性但对模型增益不大的样本问题,本文将半监督3D动作识别中的主动学习过程建模为马尔可夫决策过程(MDP)。通过训练一个信息样本选择模型,智能地指导骨骼序列的标注选择。为了增强状态-动作对中因素的表征能力,将它们从欧几里得空间投影到双曲空间。此外,引入元调优策略以加速该方法在实际场景中的部署。在三个3D动作识别基准数据集上的大量实验证明了该方法的有效性。
🔬 方法详解
问题定义:论文旨在解决在有限训练样本下,如何高效地进行基于骨骼的3D动作识别。现有方法,特别是基于主动学习的方法,通常选择最具代表性的样本进行标注,但这些样本可能与模型已学习的知识冗余,导致标注成本高但收益低。因此,如何选择对模型提升最大的信息样本是关键挑战。
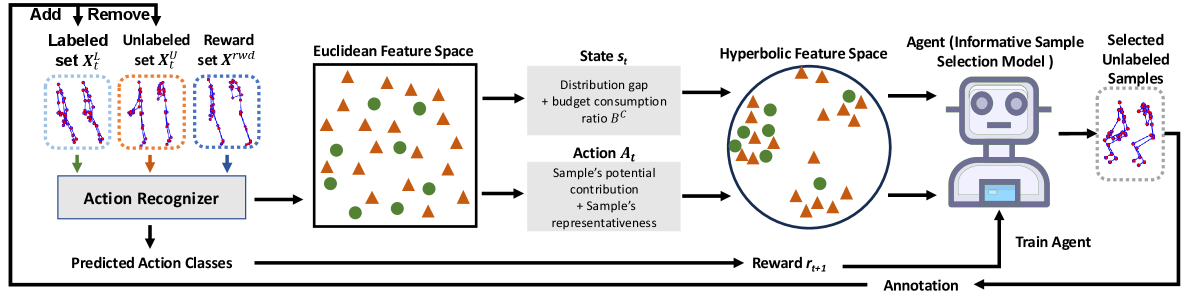
核心思路:论文的核心思路是将主动学习过程视为一个马尔可夫决策过程(MDP),通过训练一个策略网络(信息样本选择模型)来学习如何选择样本。该策略网络的目标是最大化长期回报,即选择能够显著提升模型性能的样本。通过这种方式,模型能够主动探索未知的样本空间,并选择最具信息量的样本进行标注。
技术框架:整体框架包含以下几个主要模块:1) 骨骼序列编码器:将骨骼序列嵌入到特征空间;2) MDP环境:定义状态空间(已标注和未标注样本的特征表示)、动作空间(选择哪个未标注样本进行标注)、奖励函数(标注新样本后模型性能的提升);3) 信息样本选择模型(策略网络):基于当前状态,选择一个动作(即选择一个未标注样本);4) 动作识别模型:用于评估标注新样本后的模型性能,并计算奖励。
关键创新:论文的关键创新在于将主动学习过程建模为MDP,并训练一个策略网络来指导样本选择。与传统的基于不确定性或代表性的选择策略不同,该方法能够学习到一种更智能的样本选择策略,从而更有效地利用有限的标注资源。此外,使用双曲空间投影来增强状态-动作对的表征能力,并引入元调优策略加速模型部署。
关键设计:奖励函数的设计至关重要,论文采用标注新样本后模型在验证集上的性能提升作为奖励。状态空间的构建包括已标注和未标注样本的特征表示,这些特征通过骨骼序列编码器提取。策略网络可以使用强化学习算法(如Q-learning或Policy Gradient)进行训练。双曲空间投影使用Poincaré ball模型,通过映射函数将欧几里得空间的特征向量映射到双曲空间。元调优策略则通过少量样本快速适应新任务。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在NTU-RGBD、Kinetics-Skeleton和NW-UCLA三个3D动作识别基准数据集上均取得了显著的性能提升。例如,在NTU-RGBD数据集上,使用较少的标注样本即可达到甚至超过传统监督学习方法的性能。与现有的主动学习方法相比,该方法能够更有效地利用有限的标注资源,实现更高的识别精度。
🎯 应用场景
该研究成果可应用于人机交互、智能监控、康复训练等领域。在这些场景中,获取大量标注的骨骼动作数据成本高昂,而该方法能够以较少的标注样本实现较高的动作识别精度,降低了数据标注成本,加速了相关技术的落地应用。未来,该方法可以进一步扩展到其他模态的数据,例如RGB视频或深度图像。
📄 摘要(原文)
Skeleton-based human action recognition aims to classify human skeletal sequences, which are spatiotemporal representations of actions, into predefined categories. To reduce the reliance on costly annotations of skeletal sequences while maintaining competitive recognition accuracy, the task of 3D Action Recognition with Limited Training Samples, also known as semi-supervised 3D Action Recognition, has been proposed. In addition, active learning, which aims to proactively select the most informative unlabeled samples for annotation, has been explored in semi-supervised 3D Action Recognition for training sample selection. Specifically, researchers adopt an encoder-decoder framework to embed skeleton sequences into a latent space, where clustering information, combined with a margin-based selection strategy using a multi-head mechanism, is utilized to identify the most informative sequences in the unlabeled set for annotation. However, the most representative skeleton sequences may not necessarily be the most informative for the action recognizer, as the model may have already acquired similar knowledge from previously seen skeleton samples. To solve it, we reformulate Semi-supervised 3D action recognition via active learning from a novel perspective by casting it as a Markov Decision Process (MDP). Built upon the MDP framework and its training paradigm, we train an informative sample selection model to intelligently guide the selection of skeleton sequences for annotation. To enhance the representational capacity of the factors in the state-action pairs within our method, we project them from Euclidean space to hyperbolic space. Furthermore, we introduce a meta tuning strategy to accelerate the deployment of our method in real-world scenarios. Extensive experiments on three 3D action recognition benchmarks demonstrate the effectiveness of our method.