LangHOPS: Language Grounded Hierarchical Open-Vocabulary Part Segmentation
作者: Yang Miao, Jan-Nico Zaech, Xi Wang, Fabien Despinoy, Danda Pani Paudel, Luc Van Gool
分类: cs.CV
发布日期: 2025-10-29 (更新: 2026-01-12)
备注: 10 pages, 5 figures, 14 tables, Neurips 2025
💡 一句话要点
提出LangHOPS,首个基于MLLM的开放词汇层级物体部件分割框架。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放词汇分割 物体部件分割 多模态大语言模型 层级结构 语言引导
📋 核心要点
- 现有物体部件分割方法依赖启发式或可学习的视觉分组,缺乏对语言知识的有效利用。
- LangHOPS将MLLM融入物体部件解析流程,利用其知识和推理能力,在语言空间中构建层级结构。
- 实验表明,LangHOPS在多个场景下超越现有方法,在PartImageNet和ADE20K数据集上均取得显著提升。
📝 摘要(中文)
本文提出LangHOPS,这是首个基于多模态大型语言模型(MLLM)的开放词汇物体部件实例分割框架。给定图像,LangHOPS可以联合检测和分割来自开放词汇候选类别的层级物体和部件实例。与依赖于启发式或可学习的视觉分组的先前方法不同,我们的方法将物体-部件层级结构建立在语言空间中。它将MLLM集成到物体-部件解析流程中,以利用其丰富的知识和推理能力,并链接层级结构中的多粒度概念。我们在多个具有挑战性的场景中评估LangHOPS,包括域内和跨数据集的物体-部件实例分割,以及零样本语义分割。LangHOPS取得了最先进的结果,在PartImageNet数据集上,域内平均精度(AP)超过先前方法5.5%,跨数据集平均精度超过4.8%,在ADE20K中未见过的物体部件上的平均交并比(mIOU)超过2.5%(零样本)。消融研究进一步验证了语言引导的层级结构和MLLM驱动的部件查询细化策略的有效性。代码将会开源。
🔬 方法详解
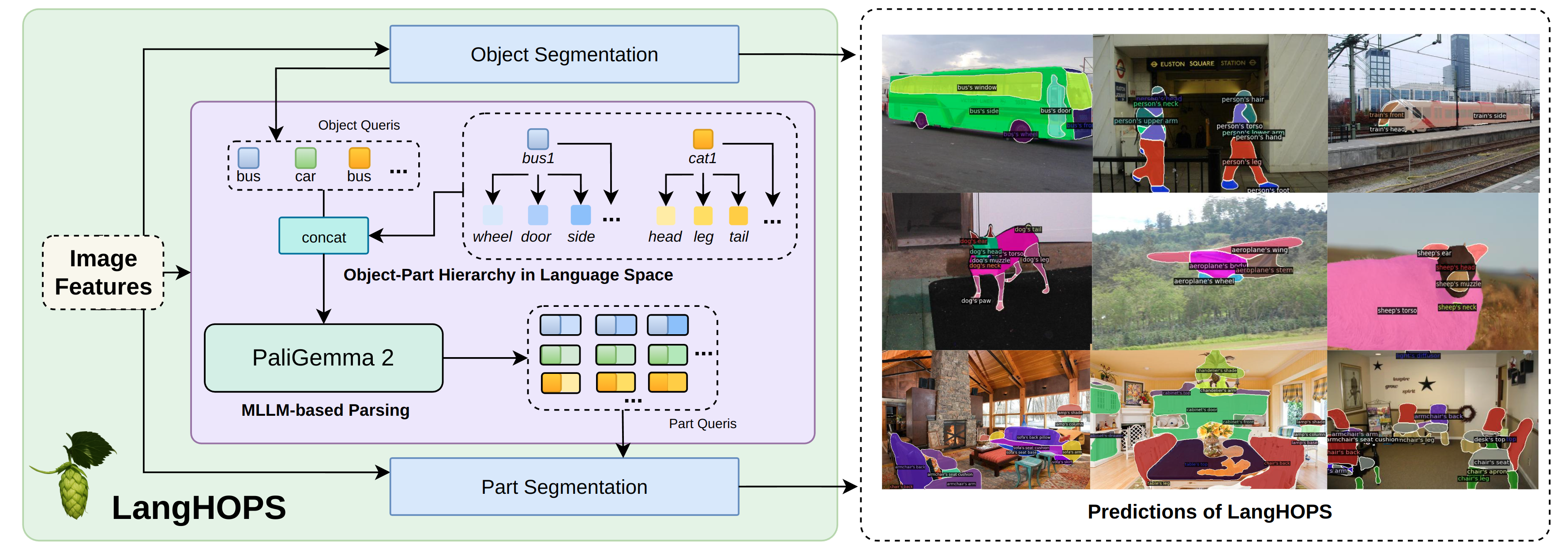
问题定义:论文旨在解决开放词汇物体部件实例分割问题,即在没有预定义类别的情况下,检测和分割图像中物体及其部件的实例,并构建它们之间的层级关系。现有方法主要依赖于视觉特征进行分组,缺乏对语言知识的有效利用,难以处理开放词汇场景,泛化能力受限。
核心思路:论文的核心思路是将物体部件的层级关系建立在语言空间中,利用MLLM的知识和推理能力来指导视觉特征的提取和分组。通过语言描述来定义物体和部件,并利用MLLM来推理它们之间的关系,从而实现更准确和鲁棒的分割。
技术框架:LangHOPS框架主要包含以下几个模块:1) 图像编码器:提取图像的视觉特征。2) 文本编码器:将物体和部件的文本描述编码为语言特征。3) MLLM:利用图像和文本特征,推理物体和部件之间的关系,并生成部件查询。4) 分割模块:根据部件查询,分割图像中的物体和部件实例。整体流程是,首先利用图像编码器和文本编码器分别提取图像和文本特征,然后将这些特征输入到MLLM中,MLLM根据语言知识生成部件查询,最后利用分割模块根据部件查询分割图像中的物体和部件实例。
关键创新:论文的关键创新在于将MLLM引入到物体部件分割任务中,并利用语言知识来指导视觉特征的提取和分组。与现有方法相比,LangHOPS能够更好地处理开放词汇场景,并具有更强的泛化能力。此外,论文还提出了语言引导的层级结构和MLLM驱动的部件查询细化策略,进一步提升了分割性能。
关键设计:论文中使用了预训练的CLIP模型作为图像和文本编码器。MLLM部分使用了BLIP-2模型。分割模块使用了Mask2Former模型。损失函数包括分割损失和对比学习损失。对比学习损失用于拉近同一物体或部件的视觉和语言特征,推远不同物体或部件的视觉和语言特征。
🖼️ 关键图片


📊 实验亮点
LangHOPS在PartImageNet数据集上取得了显著的性能提升,域内平均精度(AP)超过先前方法5.5%,跨数据集平均精度超过4.8%。在ADE20K数据集上,LangHOPS在未见过的物体部件上的平均交并比(mIOU)超过2.5%(零样本)。消融实验验证了语言引导的层级结构和MLLM驱动的部件查询细化策略的有效性。
🎯 应用场景
LangHOPS可应用于机器人视觉、图像编辑、自动驾驶等领域。例如,机器人可以利用LangHOPS理解场景中的物体及其部件,从而更好地完成任务。在图像编辑中,用户可以通过自然语言描述来选择和编辑图像中的特定部件。自动驾驶系统可以利用LangHOPS识别车辆的各个部件,从而提高安全性。
📄 摘要(原文)
We propose LangHOPS, the first Multimodal Large Language Model (MLLM) based framework for open-vocabulary object-part instance segmentation. Given an image, LangHOPS can jointly detect and segment hierarchical object and part instances from open-vocabulary candidate categories. Unlike prior approaches that rely on heuristic or learnable visual grouping, our approach grounds object-part hierarchies in language space. It integrates the MLLM into the object-part parsing pipeline to leverage its rich knowledge and reasoning capabilities, and link multi-granularity concepts within the hierarchies. We evaluate LangHOPS across multiple challenging scenarios, including in-domain and cross-dataset object-part instance segmentation, and zero-shot semantic segmentation. LangHOPS achieves state-of-the-art results, surpassing previous methods by 5.5% Average Precision (AP) (in-domain) and 4.8% (cross-dataset) on the PartImageNet dataset and by 2.5% mIOU on unseen object parts in ADE20K (zero-shot). Ablation studies further validate the effectiveness of the language-grounded hierarchy and MLLM driven part query refinement strategy. The code will be released here.