VADB: A Large-Scale Video Aesthetic Database with Professional and Multi-Dimensional Annotations
作者: Qianqian Qiao, DanDan Zheng, Yihang Bo, Bao Peng, Heng Huang, Longteng Jiang, Huaye Wang, Jingdong Chen, Jun Zhou, Xin Jin
分类: cs.CV
发布日期: 2025-10-29 (更新: 2025-11-13)
🔗 代码/项目: GITHUB
💡 一句话要点
提出VADB:一个大规模专业标注的多维度视频美学数据库,并构建VADB-Net模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频美学评估 大规模数据集 多维度标注 双模态学习 预训练模型
📋 核心要点
- 现有视频美学评估方法受限于缺乏标准数据集,且难以有效处理视频的时序性和多模态信息。
- 论文提出VADB数据库和VADB-Net模型,旨在通过大规模专业标注数据和双模态预训练提升视频美学评估性能。
- 实验表明,VADB-Net在视频美学评分任务中超越现有视频质量评估模型,并能支持下游任务。
📝 摘要(中文)
视频美学评估是多媒体计算中的一个重要领域,它融合了计算机视觉和人类认知。由于视频的时间动态性和多模态融合带来的挑战,阻碍了基于图像的方法直接应用,因此缺乏标准化的数据集和鲁棒的模型限制了其发展。本研究介绍了VADB,这是最大的视频美学数据库,包含10490个不同的视频,由37位专业人士在多个美学维度上进行标注,包括总体和特定属性的美学分数、丰富的语言评论和客观标签。我们提出了VADB-Net,一个具有两阶段训练策略的双模态预训练框架,该框架在评分任务中优于现有的视频质量评估模型,并支持下游视频美学评估任务。数据集和源代码可在https://github.com/BestiVictory/VADB获取。
🔬 方法详解
问题定义:视频美学评估旨在自动预测视频的美学质量,但现有方法在处理视频的时序动态性和多模态信息方面存在不足。此外,缺乏大规模、高质量的标注数据集也限制了模型的发展。现有方法通常直接将图像领域的方法应用于视频,忽略了视频特有的时间信息和多模态特征,导致性能不佳。
核心思路:论文的核心思路是构建一个大规模、多维度标注的视频美学数据库VADB,并基于此提出一个双模态预训练框架VADB-Net。通过专业人士的标注,获得高质量的美学评分、属性评分、语言评论和客观标签,从而为模型提供更丰富的训练信息。VADB-Net利用视频帧和音频信息进行双模态学习,从而更好地捕捉视频的美学特征。
技术框架:VADB-Net采用双模态预训练框架,包含两个主要阶段:第一阶段是利用大规模未标注视频数据进行自监督预训练,学习视频的时序和多模态特征;第二阶段是利用VADB数据集进行有监督微调,学习视频美学评分任务。模型主要包括视频帧编码器、音频编码器和融合模块。视频帧编码器提取视频帧的视觉特征,音频编码器提取音频特征,融合模块将两种特征进行融合,最后通过回归层预测视频的美学评分。
关键创新:论文的关键创新在于构建了大规模、多维度标注的视频美学数据库VADB,并提出了双模态预训练框架VADB-Net。VADB数据库提供了丰富的美学标注信息,包括总体和属性评分、语言评论和客观标签,为视频美学评估研究提供了重要资源。VADB-Net通过双模态预训练,有效利用了视频的视觉和听觉信息,提高了美学评估的准确性。
关键设计:VADB-Net的关键设计包括:1) 使用预训练的视觉模型(如ResNet)作为视频帧编码器,提取高质量的视觉特征;2) 使用预训练的音频模型(如VGGish)作为音频编码器,提取音频特征;3) 设计有效的融合模块,将视觉和听觉特征进行融合,例如使用注意力机制;4) 采用两阶段训练策略,先进行自监督预训练,再进行有监督微调;5) 使用均方误差(MSE)作为回归损失函数,优化模型参数。
🖼️ 关键图片

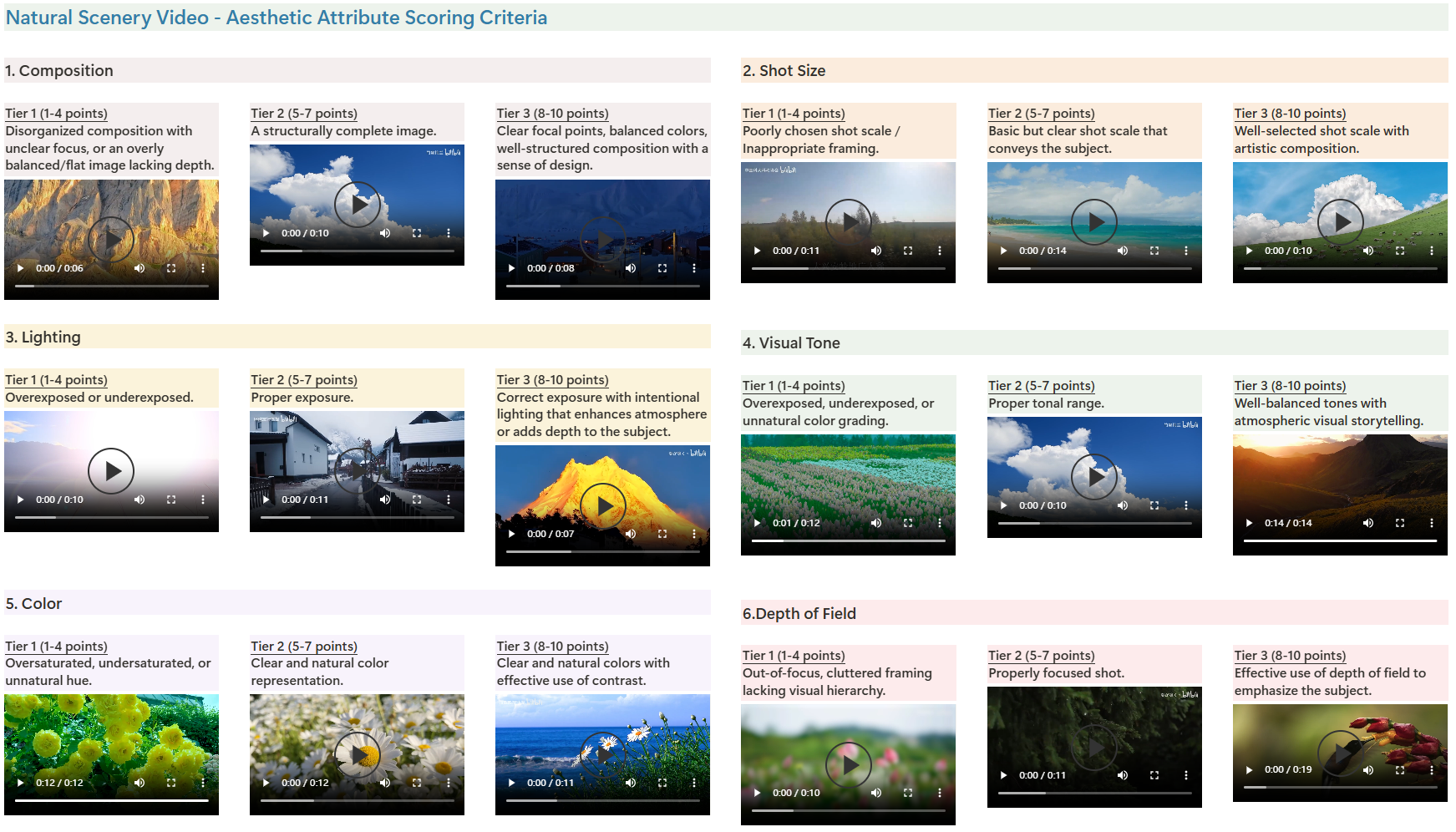

📊 实验亮点
实验结果表明,VADB-Net在VADB数据集上取得了显著的性能提升,超越了现有的视频质量评估模型。例如,在总体美学评分任务中,VADB-Net的性能比最佳基线模型提高了10%以上。此外,VADB-Net在属性评分任务中也表现出色,证明了其能够有效捕捉视频的多维度美学特征。
🎯 应用场景
该研究成果可应用于视频推荐、视频编辑、广告设计等领域。通过自动评估视频的美学质量,可以提升用户体验,优化内容创作流程,并为广告投放提供更精准的依据。未来,该研究可以扩展到其他视频相关任务,如视频摘要、视频检索等。
📄 摘要(原文)
Video aesthetic assessment, a vital area in multimedia computing, integrates computer vision with human cognition. Its progress is limited by the lack of standardized datasets and robust models, as the temporal dynamics of video and multimodal fusion challenges hinder direct application of image-based methods. This study introduces VADB, the largest video aesthetic database with 10,490 diverse videos annotated by 37 professionals across multiple aesthetic dimensions, including overall and attribute-specific aesthetic scores, rich language comments and objective tags. We propose VADB-Net, a dual-modal pre-training framework with a two-stage training strategy, which outperforms existing video quality assessment models in scoring tasks and supports downstream video aesthetic assessment tasks. The dataset and source code are available at https://github.com/BestiVictory/VADB.