Test-Time Adaptive Object Detection with Foundation Model
作者: Yingjie Gao, Yanan Zhang, Zhi Cai, Di Huang
分类: cs.CV
发布日期: 2025-10-29
备注: Accepted by NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于Foundation Model的测试时自适应目标检测方法,无需源数据且突破类别限制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 测试时自适应 目标检测 Foundation Model Prompt Tuning 多模态学习
📋 核心要点
- 现有测试时自适应目标检测方法依赖源域统计特征,且假设源域和目标域共享相同类别空间,限制了其应用。
- 本文提出一种基于Foundation Model的测试时自适应方法,通过多模态Prompt Tuning自适应视觉和语言表示,无需源数据。
- 实验表明,该方法在跨损坏和跨数据集上优于现有方法,能适应任意跨域和跨类别目标数据。
📝 摘要(中文)
本文提出了一种基于Foundation Model的测试时自适应目标检测方法,旨在解决在线领域自适应问题。该方法无需依赖源数据,并克服了传统封闭集合的限制。具体而言,我们设计了一个多模态Prompt-based Mean-Teacher框架,用于视觉-语言检测器驱动的测试时自适应,该框架结合了文本和视觉Prompt Tuning,以参数高效的方式在测试数据上调整语言和视觉表示空间。此外,我们提出了一种专为视觉Prompt设计的测试时Warm-start策略,以有效保持视觉分支的表示能力。为了保证每个测试批次中的高质量伪标签,我们维护了一个实例动态记忆(IDM)模块,该模块存储来自先前测试样本的高质量伪标签,并提出了两种新策略——记忆增强和记忆幻觉——以利用IDM的高质量实例分别增强原始预测和幻觉生成没有可用伪标签的图像。在跨损坏和跨数据集基准上的大量实验表明,我们的方法始终优于先前的最先进方法,并且可以适应任意跨域和跨类别目标数据。
🔬 方法详解
问题定义:现有的测试时自适应目标检测方法通常依赖于源域数据,并且假设源域和目标域具有相同的类别空间。这在实际应用中存在局限性,因为获取源域数据可能不可行,并且目标域的类别可能与源域不同。因此,需要一种无需源数据且能处理开放集合场景的测试时自适应目标检测方法。
核心思路:本文的核心思路是利用Foundation Model强大的泛化能力,通过Prompt Tuning的方式,在测试时自适应目标域数据。具体来说,通过视觉和语言Prompt Tuning,调整视觉和语言表示空间,使检测器能够更好地适应目标域的特征分布和类别信息。同时,利用实例动态记忆模块存储高质量伪标签,并利用记忆增强和记忆幻觉策略,提高伪标签的质量和数量。
技术框架:该方法采用多模态Prompt-based Mean-Teacher框架。该框架包含一个学生模型和一个教师模型。学生模型接收带有Prompt的输入图像,并生成预测结果。教师模型是学生模型的指数移动平均,用于生成更稳定的伪标签。框架还包含一个实例动态记忆(IDM)模块,用于存储高质量的伪标签。在每个测试批次中,学生模型使用当前批次的数据和IDM中的数据进行训练。
关键创新:该方法的主要创新点在于:1) 提出了一种基于Foundation Model的测试时自适应目标检测方法,无需源数据且能处理开放集合场景;2) 设计了一种多模态Prompt-based Mean-Teacher框架,通过视觉和语言Prompt Tuning自适应视觉和语言表示;3) 提出了一种实例动态记忆(IDM)模块,并利用记忆增强和记忆幻觉策略,提高伪标签的质量和数量。
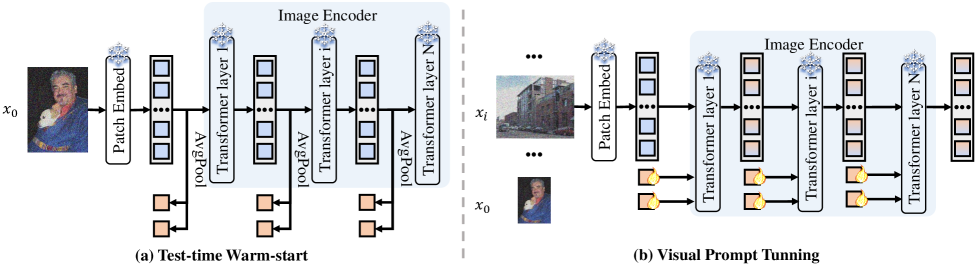
关键设计:视觉Prompt Tuning采用Adapter结构,以参数高效的方式调整视觉表示。语言Prompt Tuning则通过调整文本编码器的输入文本,来适应目标域的类别信息。测试时Warm-start策略用于初始化视觉Prompt,以保留视觉分支的表示能力。记忆增强策略利用IDM中的高质量实例,增强原始预测的置信度。记忆幻觉策略则利用IDM中的高质量实例,生成没有可用伪标签的图像,从而增加训练样本的数量。
🖼️ 关键图片


📊 实验亮点
该方法在跨损坏和跨数据集基准测试中,性能始终优于现有最先进方法。例如,在常见的COCO到Clipart1k的跨域自适应任务上,该方法取得了显著的性能提升,证明了其在复杂场景下的有效性和泛化能力。实验结果表明,该方法能够有效适应任意跨域和跨类别目标数据。
🎯 应用场景
该研究成果可应用于自动驾驶、智能监控、机器人等领域,解决实际场景中目标检测模型因环境变化、数据偏差导致的性能下降问题。无需源数据和类别限制的特性,使其在复杂、动态和未知的环境中具有更强的适应性和实用性,具有广阔的应用前景。
📄 摘要(原文)
In recent years, test-time adaptive object detection has attracted increasing attention due to its unique advantages in online domain adaptation, which aligns more closely with real-world application scenarios. However, existing approaches heavily rely on source-derived statistical characteristics while making the strong assumption that the source and target domains share an identical category space. In this paper, we propose the first foundation model-powered test-time adaptive object detection method that eliminates the need for source data entirely and overcomes traditional closed-set limitations. Specifically, we design a Multi-modal Prompt-based Mean-Teacher framework for vision-language detector-driven test-time adaptation, which incorporates text and visual prompt tuning to adapt both language and vision representation spaces on the test data in a parameter-efficient manner. Correspondingly, we propose a Test-time Warm-start strategy tailored for the visual prompts to effectively preserve the representation capability of the vision branch. Furthermore, to guarantee high-quality pseudo-labels in every test batch, we maintain an Instance Dynamic Memory (IDM) module that stores high-quality pseudo-labels from previous test samples, and propose two novel strategies-Memory Enhancement and Memory Hallucination-to leverage IDM's high-quality instances for enhancing original predictions and hallucinating images without available pseudo-labels, respectively. Extensive experiments on cross-corruption and cross-dataset benchmarks demonstrate that our method consistently outperforms previous state-of-the-art methods, and can adapt to arbitrary cross-domain and cross-category target data. Code is available at https://github.com/gaoyingjay/ttaod_foundation.