Modality-Aware SAM: Sharpness-Aware-Minimization Driven Gradient Modulation for Harmonized Multimodal Learning
作者: Hossein R. Nowdeh, Jie Ji, Xiaolong Ma, Fatemeh Afghah
分类: cs.CV, cs.LG
发布日期: 2025-10-28
💡 一句话要点
提出模态感知SAM,通过梯度调制和谐多模态学习,提升泛化性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 锐度感知最小化 梯度调制 Shapley值 模态融合 鲁棒性 泛化能力
📋 核心要点
- 多模态学习中,主导模态易掩盖其他模态,导致泛化性受限,是当前方法面临的主要挑战。
- M-SAM通过Shapley值识别主导模态,并调制损失函数,提升模型对主导模态的鲁棒性,同时增强其他模态的贡献。
- 实验结果表明,M-SAM在多个数据集上优于现有优化和梯度操作方法,显著提升了多模态学习的性能。
📝 摘要(中文)
在多模态学习中,主导模态常常掩盖其他模态,限制了模型的泛化能力。本文提出模态感知锐度感知最小化(M-SAM),这是一个与模型无关的框架,适用于多种模态,并支持早期和晚期融合场景。在每次迭代中,M-SAM通过三个步骤优化学习。首先,它基于Shapley值识别各模态对准确率的贡献,从而确定主导模态。其次,它分解损失景观,或者说,调制损失,优先考虑模型对主导模态的鲁棒性。第三,M-SAM通过调制后的梯度反向传播来更新权重。这确保了主导模态的鲁棒学习,同时增强了其他模态的贡献,使模型能够探索和利用互补特征,从而加强整体性能。在四个不同的数据集上进行的大量实验表明,M-SAM优于最新的优化和梯度操作方法,并显著平衡和改进了多模态学习。
🔬 方法详解
问题定义:多模态学习旨在融合来自不同模态的信息以提升模型性能。然而,一个常见的问题是某些模态(主导模态)可能会在训练过程中占据主导地位,而忽略了其他模态的贡献,导致模型对主导模态过度拟合,泛化能力下降。现有方法难以有效平衡不同模态的贡献,无法充分利用互补信息。
核心思路:M-SAM的核心思路是通过模态感知的梯度调制来平衡不同模态的贡献。具体来说,它首先识别出主导模态,然后通过调整损失函数,使得模型更加关注主导模态的鲁棒性,同时鼓励模型学习其他模态的互补信息。这种方法旨在防止模型过度依赖主导模态,从而提高模型的泛化能力。
技术框架:M-SAM的整体框架包含三个主要步骤:1) 模态重要性评估:使用Shapley值来评估每个模态对模型预测准确率的贡献,从而确定主导模态。2) 损失景观调制:根据模态重要性,调整损失函数,使得模型更加关注主导模态的鲁棒性。这可以通过对损失函数进行分解或加权来实现。3) 梯度更新:使用调制后的梯度进行反向传播,更新模型权重。
关键创新:M-SAM的关键创新在于其模态感知的损失景观调制方法。与传统的Sharpness-Aware Minimization (SAM) 相比,M-SAM不是简单地最小化损失函数的锐度,而是根据不同模态的重要性,有选择地调整损失函数,从而更好地平衡不同模态的贡献。这种方法能够更有效地利用多模态数据中的互补信息,提高模型的泛化能力。
关键设计:M-SAM的关键设计包括:1) 使用Shapley值进行模态重要性评估,这是一种公平且可解释的方法。2) 通过调整损失函数的权重或分解损失函数来实现损失景观调制。具体的调整策略可以根据不同的数据集和任务进行调整。3) M-SAM是模型无关的,可以应用于各种多模态模型和融合策略(早期或晚期融合)。
🖼️ 关键图片
📊 实验亮点
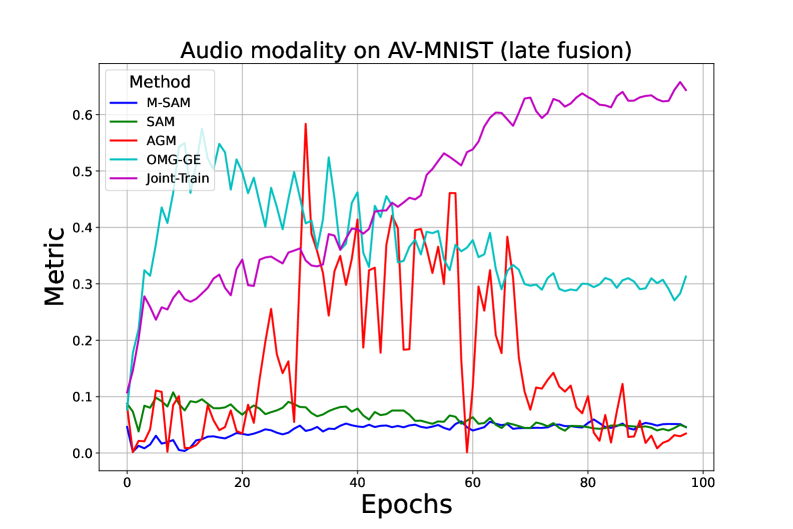
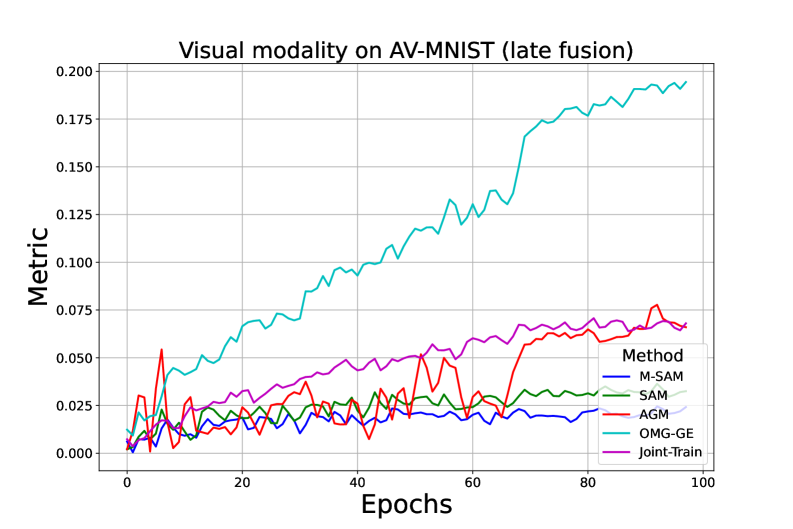
论文在四个不同的数据集上进行了实验,结果表明M-SAM优于现有的优化和梯度操作方法。具体来说,M-SAM在多模态学习任务上取得了显著的性能提升,并且能够更好地平衡不同模态的贡献。实验结果验证了M-SAM的有效性和优越性。
🎯 应用场景
M-SAM可广泛应用于需要多模态数据融合的领域,例如:自动驾驶(融合图像、激光雷达、雷达等数据)、医疗诊断(融合影像、基因组、临床数据)、情感分析(融合文本、语音、面部表情等数据)。该方法能够提升模型的鲁棒性和泛化能力,从而提高实际应用中的性能和可靠性,具有重要的实际价值。
📄 摘要(原文)
In multimodal learning, dominant modalities often overshadow others, limiting generalization. We propose Modality-Aware Sharpness-Aware Minimization (M-SAM), a model-agnostic framework that applies to many modalities and supports early and late fusion scenarios. In every iteration, M-SAM in three steps optimizes learning. \textbf{First, it identifies the dominant modality} based on modalities' contribution in the accuracy using Shapley. \textbf{Second, it decomposes the loss landscape}, or in another language, it modulates the loss to prioritize the robustness of the model in favor of the dominant modality, and \textbf{third, M-SAM updates the weights} by backpropagation of modulated gradients. This ensures robust learning for the dominant modality while enhancing contributions from others, allowing the model to explore and exploit complementary features that strengthen overall performance. Extensive experiments on four diverse datasets show that M-SAM outperforms the latest state-of-the-art optimization and gradient manipulation methods and significantly balances and improves multimodal learning.