Perception, Understanding and Reasoning, A Multimodal Benchmark for Video Fake News Detection
作者: Cui Yakun, Peng Qi, Fushuo Huo, Hang Du, Weijie Shi, Juntao Dai, Zhenghao Zhu, Sirui Han, Yike Guo
分类: cs.CV, cs.AI
发布日期: 2025-10-28 (更新: 2026-01-19)
💡 一句话要点
提出POVFNDB基准,用于多模态大语言模型在视频假新闻检测中感知、理解和推理能力的细粒度评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频假新闻检测 多模态大语言模型 过程导向评估 基准数据集 思维链 Qwen2.5VL-7B-Instruct 多模态推理
📋 核心要点
- 现有视频假新闻检测基准缺乏对模型在感知、理解和推理等关键环节的细粒度评估。
- 提出POVFNDB基准,包含10个任务和36,240个人工标注问答,全面评估MLLM在VFND中的能力。
- 通过POVFND-CoT框架微调Qwen2.5VL-7B-Instruct,建立了强大的基线,并在VFND上取得了SOTA性能。
📝 摘要(中文)
多模态大语言模型(MLLMs)的出现极大地推动了视频假新闻检测(VFND)任务的研究。现有的基准通常侧重于检测准确率,而未能为整个检测过程提供细粒度的评估。为了解决这些局限性,我们引入了{POVFNDB(面向过程的视频假新闻检测基准)},这是一个面向过程的基准,包含10个任务,旨在系统地评估MLLM在VFND中的感知、理解和推理能力。该基准包含 extit{36,240}个人工标注的问答(QA),采用结构化或开放式格式,涵盖15个不同的评估维度,这些维度描述了视频假新闻检测过程的不同方面。我们使用POVFNDB对专有和开源的MLLM进行了全面评估。此外,我们通过在我们提出的POVFND-CoT框架下,对Qwen2.5VL-7B-Instruct进行面向过程的思维链数据微调,建立了一个强大的基准基线,在VFND上实现了最先进的性能。
🔬 方法详解
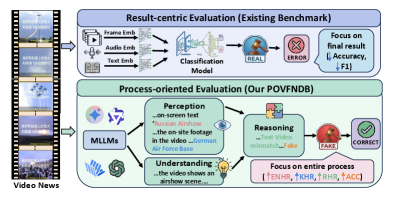
问题定义:论文旨在解决现有视频假新闻检测基准缺乏对模型在感知、理解和推理等关键环节的细粒度评估的问题。现有方法主要关注最终的检测准确率,而忽略了模型做出判断的过程,难以深入了解模型的优缺点,也无法指导模型改进。
核心思路:论文的核心思路是构建一个面向过程的视频假新闻检测基准(POVFNDB),通过设计一系列任务和评估维度,系统地评估MLLM在VFND中的感知、理解和推理能力。通过对模型在各个环节的表现进行评估,可以更全面地了解模型的性能,并为模型改进提供指导。
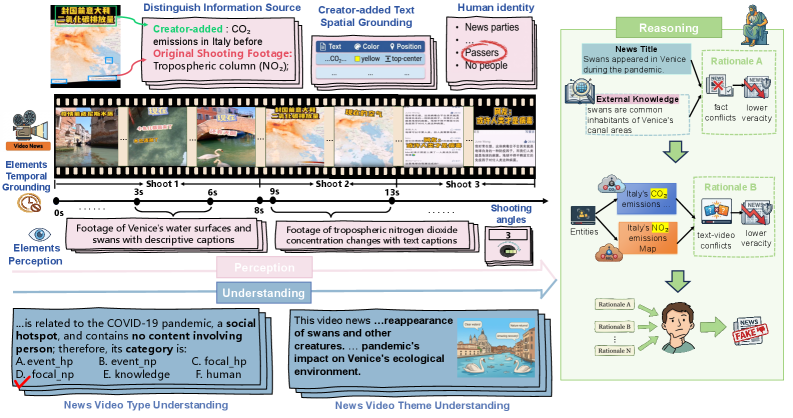
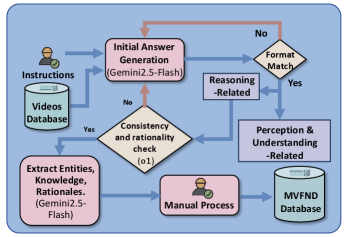
技术框架:POVFNDB基准包含10个任务,涵盖了视频假新闻检测过程中的不同方面,例如视频内容理解、文本信息分析、多模态信息融合和推理判断。每个任务都包含大量的人工标注问答,采用结构化或开放式格式。此外,论文还提出了POVFND-CoT框架,用于生成面向过程的思维链数据,以提升模型的推理能力。整体流程为:构建POVFNDB基准 -> 使用基准评估现有MLLM -> 提出POVFND-CoT框架生成思维链数据 -> 微调MLLM -> 建立SOTA基线。
关键创新:论文的关键创新在于提出了一个面向过程的视频假新闻检测基准(POVFNDB),该基准能够对MLLM在VFND中的感知、理解和推理能力进行细粒度的评估。此外,论文还提出了POVFND-CoT框架,用于生成面向过程的思维链数据,以提升模型的推理能力。与现有方法相比,POVFNDB更加关注模型做出判断的过程,能够更全面地了解模型的性能。
关键设计:POVFNDB基准包含15个评估维度,这些维度描述了视频假新闻检测过程的不同方面,例如视频内容的相关性、文本信息的真实性、多模态信息的一致性等。POVFND-CoT框架通过人工设计prompt,引导模型生成思维链,从而提升模型的推理能力。论文使用Qwen2.5VL-7B-Instruct作为基础模型,并使用面向过程的思维链数据进行微调,最终在VFND上取得了SOTA性能。具体参数设置和损失函数等细节未在摘要中详细描述。
🖼️ 关键图片
📊 实验亮点
论文通过在POVFNDB基准上对现有MLLM进行评估,发现现有模型在感知、理解和推理方面存在不足。通过使用POVFND-CoT框架微调Qwen2.5VL-7B-Instruct,在VFND任务上取得了state-of-the-art的性能,证明了该基准和方法的有效性。具体的性能提升幅度未在摘要中给出。
🎯 应用场景
该研究成果可应用于视频内容审核、社交媒体平台管理、新闻媒体的真实性验证等领域。通过细粒度评估多模态大语言模型在视频假新闻检测中的能力,可以有效提升假新闻的识别准确率,减少虚假信息传播,维护网络信息安全,为构建健康的网络生态环境做出贡献。未来,该基准可以不断扩展和完善,适应不断涌现的新型假新闻形式。
📄 摘要(原文)
The advent of multi-modal large language models (MLLMs) has greatly advanced research on video fake news detection (VFND) tasks. Existing benchmarks typically focus on the detection accuracy, while failing to provide fine-grained assessments for the entire detection process. To address these limitations, we introduce {POVFNDB (Process-oriented Video Fake News Detection Benchmark)}, a process-oriented benchmark comprising 10 tasks designed to systematically evaluate MLLMs' perception, understanding, and reasoning capabilities in VFND. This benchmark contains \textit{36,240} human-annotated question-answer (QA) in structured or open-ended formats, spanning 15 distinct evaluation dimensions that characterize different aspects of the video fake news detection process. Using POVFNDB, we conduct comprehensive evaluations on both proprietary and open-source MLLMs. Moreover, we establish a strong benchmark baseline by fine-tuning Qwen2.5VL-7B-Instruct on process-oriented chain-of-thought data constructed with our proposed POVFND-CoT framework, achieving state-of-the-art performance on VFND.