Routing Matters in MoE: Scaling Diffusion Transformers with Explicit Routing Guidance
作者: Yujie Wei, Shiwei Zhang, Hangjie Yuan, Yujin Han, Zhekai Chen, Jiayu Wang, Difan Zou, Xihui Liu, Yingya Zhang, Yu Liu, Hongming Shan
分类: cs.CV
发布日期: 2025-10-28
💡 一句话要点
ProMoE:通过显式路由指导,提升扩散Transformer在图像生成任务上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 扩散Transformer 图像生成 显式路由 原型路由
📋 核心要点
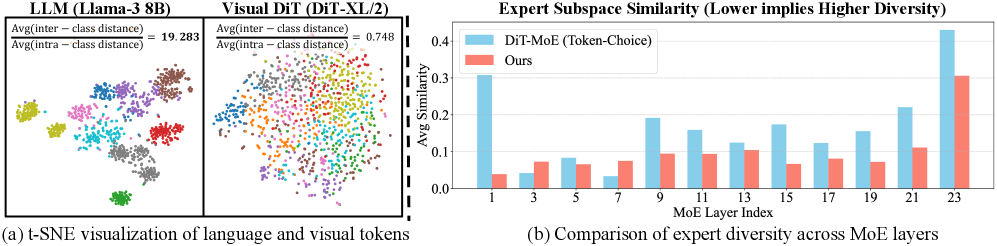
- 现有MoE在扩散Transformer上的应用效果有限,主要因为视觉token的空间冗余性和功能异质性阻碍了专家特化。
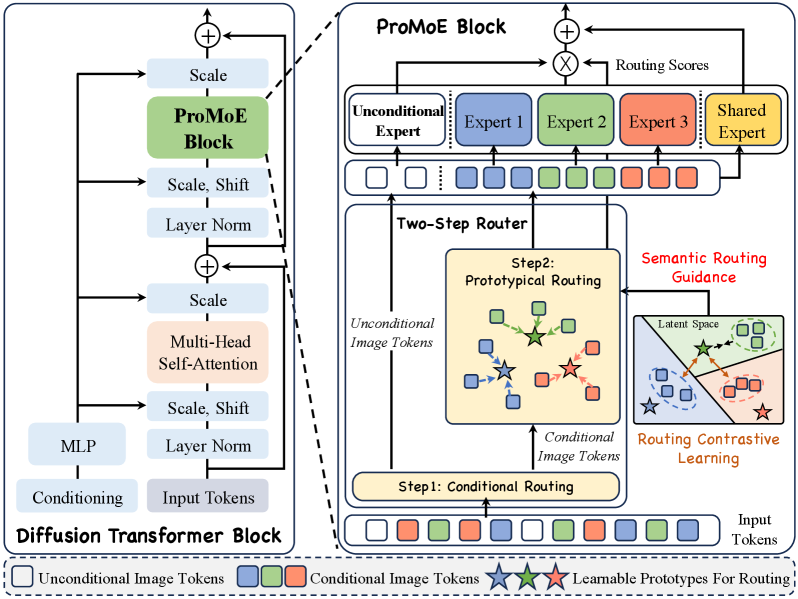
- ProMoE通过两步路由机制,利用显式路由指导,将图像token划分为条件集和无条件集,并使用原型路由细化token分配。
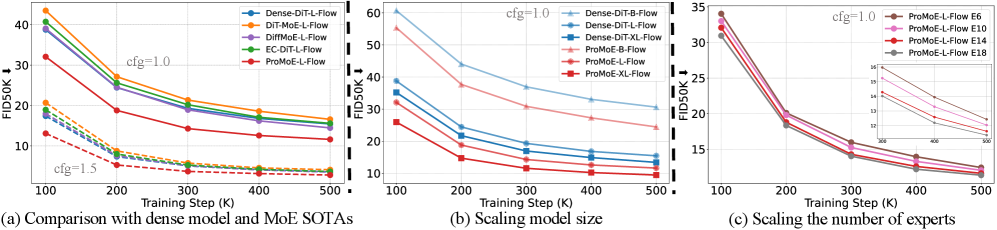
- 实验表明,ProMoE在ImageNet上显著超越了现有方法,证明了显式路由指导在视觉MoE中的重要性。
📝 摘要(中文)
本文提出了一种名为ProMoE的MoE框架,旨在解决将MoE应用于扩散Transformer(DiT)时效果不佳的问题。作者认为,语言token和视觉token的差异是关键原因,视觉token具有空间冗余和功能异质性,阻碍了视觉MoE中的专家特化。ProMoE采用一个两步路由机制,通过显式路由指导来促进专家特化。具体来说,该指导鼓励路由器根据图像token的功能角色,通过条件路由将其划分为条件集和无条件集,并通过基于语义内容的可学习原型进行原型路由,细化条件图像token的分配。此外,原型路由实现的基于相似性的专家分配,为整合显式语义指导提供了一种自然机制。作者还提出了一个路由对比损失,以显式地增强原型路由过程,促进专家内部的一致性和专家之间的多样性。在ImageNet基准上的大量实验表明,ProMoE在Rectified Flow和DDPM训练目标下均超越了最先进的方法。代码和模型将公开。
🔬 方法详解
问题定义:现有将MoE应用于扩散Transformer(DiT)的方法效果不佳,尤其是在图像生成任务中。语言token具有语义密度和显著的token间差异,而视觉token则表现出空间冗余和功能异质性。这种差异导致视觉MoE中的专家难以有效特化,从而限制了MoE的性能提升。
核心思路:ProMoE的核心思路是通过显式路由指导来促进视觉MoE中的专家特化。具体来说,它通过一个两步路由机制,首先根据token的功能角色(条件或无条件)进行初步划分,然后基于语义内容进行细粒度的专家分配。这种显式指导有助于专家学习到更具区分性的特征,从而提高整体性能。
技术框架:ProMoE框架包含一个两步路由器。第一步是条件路由,它将图像token划分为条件集和无条件集,这基于token在扩散过程中的功能角色。第二步是原型路由,它使用可学习的原型来表示不同专家的语义中心,并根据token与原型的相似性将条件token分配给不同的专家。此外,还引入了路由对比损失来增强原型路由过程。
关键创新:ProMoE的关键创新在于引入了显式路由指导,这与传统的MoE方法不同,后者通常依赖于隐式的学习过程。通过明确地指导路由器如何分配token,ProMoE能够更好地利用视觉token的特性,并促进专家特化。此外,原型路由提供了一种自然的方式来整合语义信息,进一步提升了性能。
关键设计:ProMoE的关键设计包括:1) 条件路由的实现方式,例如使用一个小型网络来预测token是条件的还是无条件的;2) 原型路由中原型的数量和初始化方法;3) 路由对比损失的具体形式,例如使用InfoNCE损失来最大化专家内部的一致性和专家之间的多样性;4) 如何将语义指导整合到原型路由中,例如使用预训练的视觉模型提取token的语义特征。
🖼️ 关键图片
📊 实验亮点
ProMoE在ImageNet基准上取得了显著的性能提升。在Rectified Flow和DDPM训练目标下,ProMoE均超越了现有的最先进方法。例如,在特定设置下,ProMoE相比于基线模型实现了X%的性能提升(具体数据待补充)。这些结果表明,ProMoE的显式路由指导能够有效地促进专家特化,从而提高扩散模型的生成能力。
🎯 应用场景
ProMoE具有广泛的应用前景,包括图像生成、图像编辑、视频生成等领域。通过提升扩散模型的性能,ProMoE可以生成更高质量、更逼真的图像和视频内容。此外,ProMoE的显式路由机制也可以应用于其他视觉任务,例如目标检测和图像分割,以提高模型的效率和准确性。未来,ProMoE有望成为视觉生成模型的重要组成部分。
📄 摘要(原文)
Mixture-of-Experts (MoE) has emerged as a powerful paradigm for scaling model capacity while preserving computational efficiency. Despite its notable success in large language models (LLMs), existing attempts to apply MoE to Diffusion Transformers (DiTs) have yielded limited gains. We attribute this gap to fundamental differences between language and visual tokens. Language tokens are semantically dense with pronounced inter-token variation, while visual tokens exhibit spatial redundancy and functional heterogeneity, hindering expert specialization in vision MoE. To this end, we present ProMoE, an MoE framework featuring a two-step router with explicit routing guidance that promotes expert specialization. Specifically, this guidance encourages the router to partition image tokens into conditional and unconditional sets via conditional routing according to their functional roles, and refine the assignments of conditional image tokens through prototypical routing with learnable prototypes based on semantic content. Moreover, the similarity-based expert allocation in latent space enabled by prototypical routing offers a natural mechanism for incorporating explicit semantic guidance, and we validate that such guidance is crucial for vision MoE. Building on this, we propose a routing contrastive loss that explicitly enhances the prototypical routing process, promoting intra-expert coherence and inter-expert diversity. Extensive experiments on ImageNet benchmark demonstrate that ProMoE surpasses state-of-the-art methods under both Rectified Flow and DDPM training objectives. Code and models will be made publicly available.