Group Relative Attention Guidance for Image Editing
作者: Xuanpu Zhang, Xuesong Niu, Ruidong Chen, Dan Song, Jianhao Zeng, Penghui Du, Haoxiang Cao, Kai Wu, An-an Liu
分类: cs.CV
发布日期: 2025-10-28 (更新: 2025-11-28)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Group Relative Attention Guidance,实现Diffusion-in-Transformer模型图像编辑的精细可控。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 图像编辑 Diffusion模型 Transformer 注意力机制 可控生成
📋 核心要点
- 现有基于Diffusion-in-Transformer的图像编辑方法缺乏对编辑程度的有效控制,难以实现定制化结果。
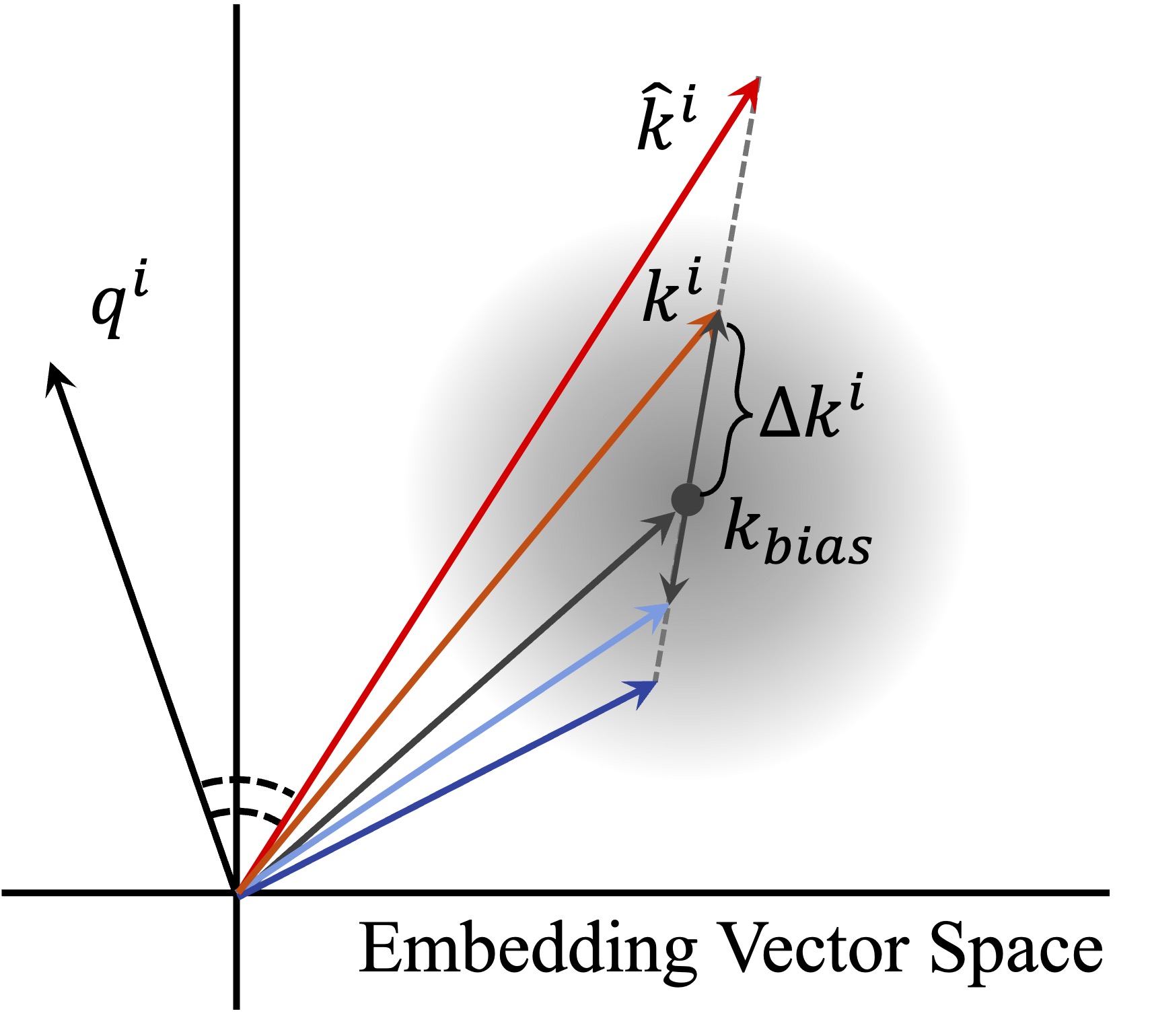
- 论文提出Group Relative Attention Guidance,通过调节token与其偏置的差值,控制模型对输入图像的关注度。
- 实验表明,GRAG能轻松集成到现有框架,提升编辑质量,并实现比Classifier-Free Guidance更平滑精确的控制。
📝 摘要(中文)
本文针对基于Diffusion-in-Transformer模型的图像编辑方法缺乏有效编辑程度控制的问题,通过研究DiT模型中的MM-Attention机制,发现Query和Key tokens共享一个仅依赖于层的偏置向量。该偏置被解释为模型固有的编辑行为,而每个token与其对应偏置之间的差值则编码了内容相关的编辑信号。基于此,作者提出Group Relative Attention Guidance (GRAG) 方法,通过重新加权不同token的差值,调节模型对输入图像的关注度,从而实现对编辑强度的连续和精细控制,且无需任何额外的调整。大量实验表明,GRAG可以轻松集成到现有图像编辑框架中,仅需四行代码即可显著提升编辑质量。与常用的Classifier-Free Guidance相比,GRAG在编辑程度控制方面表现出更平滑和精确的性能。
🔬 方法详解
问题定义:现有基于Diffusion-in-Transformer模型的图像编辑方法,在控制编辑程度方面存在不足。用户难以精确调整编辑强度,从而限制了生成结果的定制化程度。缺乏对编辑过程的细粒度控制,导致生成结果可能过度修改或修改不足,无法满足用户需求。
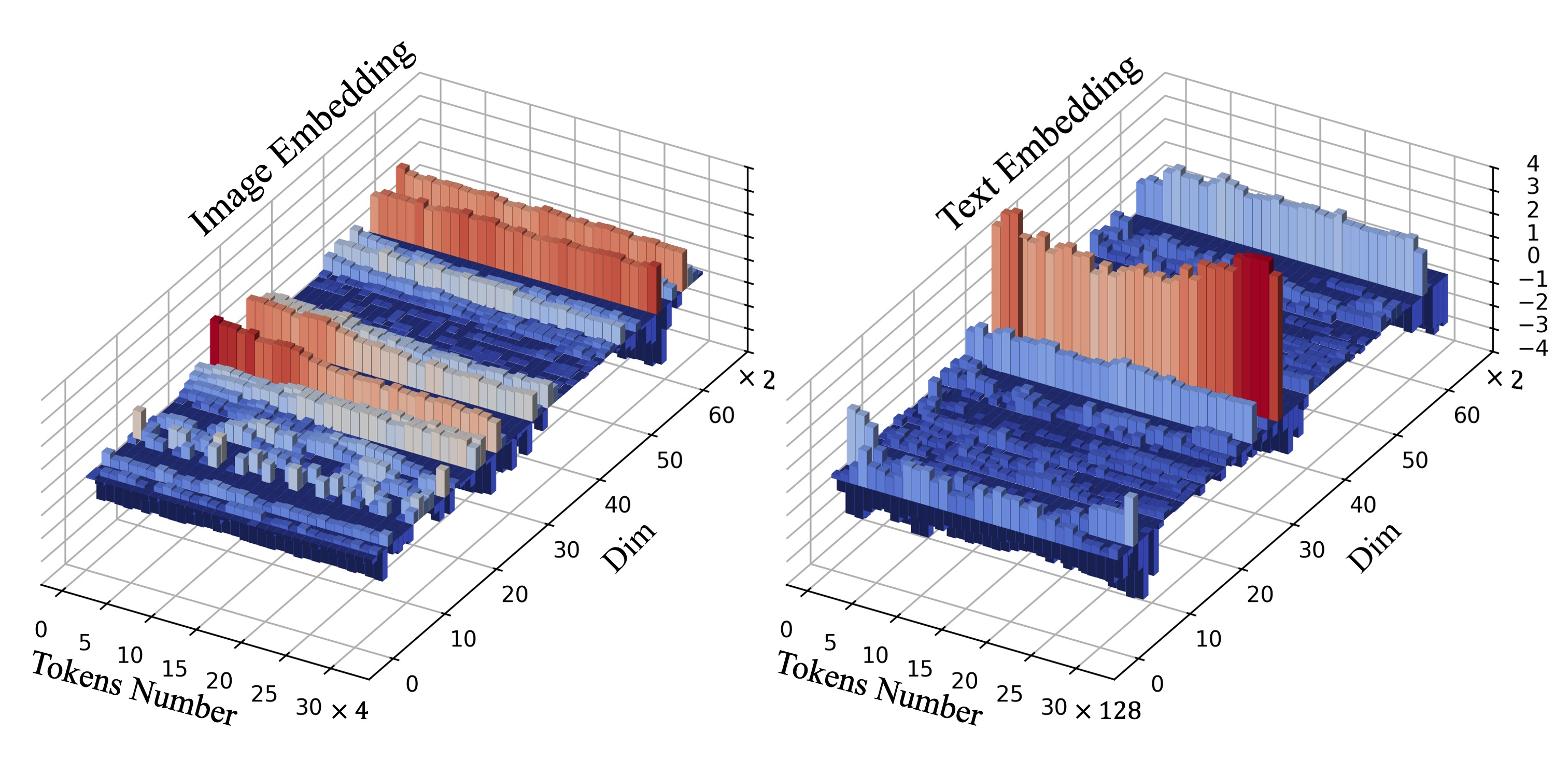
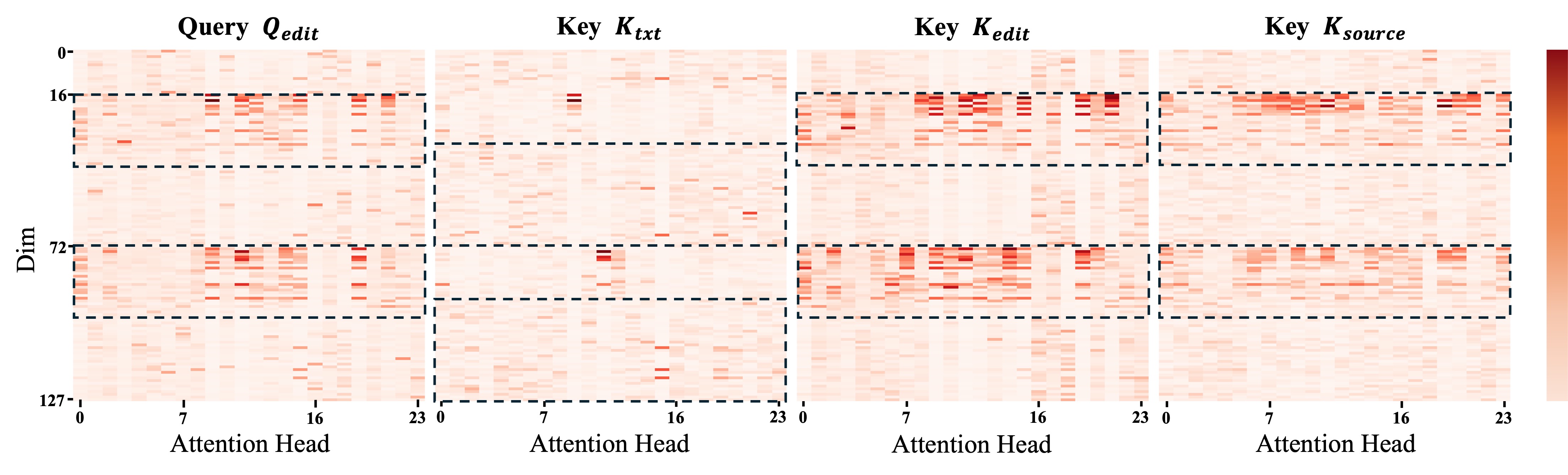
核心思路:论文的核心思路是,将DiT模型中MM-Attention机制的Query和Key tokens共享的偏置向量,解释为模型固有的编辑行为。每个token与其对应偏置之间的差值,则代表了内容相关的编辑信号。通过调整这些差值,可以控制模型对输入图像的关注程度,从而实现对编辑强度的调节。
技术框架:该方法主要基于现有的Diffusion-in-Transformer图像编辑框架。核心在于对MM-Attention模块的修改,引入Group Relative Attention Guidance。具体流程为:首先,计算每个token与其对应偏置之间的差值;然后,根据预设的权重,对这些差值进行重新加权;最后,将加权后的差值重新注入到Attention计算中,从而影响模型的编辑行为。
关键创新:该方法最重要的创新点在于,它将模型内部的偏置向量与编辑行为联系起来,并利用token与其偏置的差值来编码内容相关的编辑信号。通过调节这些信号,实现了对编辑强度的精细控制,而无需对模型进行额外的训练或调整。这种方法简单有效,易于集成到现有框架中。
关键设计:GRAG的关键设计在于差值的重新加权策略。具体来说,作者将token划分为不同的组,并为每个组分配不同的权重。这些权重可以根据用户的需求进行调整,从而实现对不同区域或不同特征的编辑强度的控制。此外,该方法不需要调整任何其他的模型参数或损失函数,因此易于实现和部署。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GRAG能够显著提升现有图像编辑框架的编辑质量,且仅需少量代码即可集成。与常用的Classifier-Free Guidance相比,GRAG在编辑程度控制方面表现出更平滑和精确的性能。具体而言,GRAG能够实现对编辑强度的连续控制,避免了Classifier-Free Guidance可能出现的突变或不稳定现象。实验结果还表明,GRAG在生成图像的视觉质量和一致性方面也优于其他方法。
🎯 应用场景
该研究成果可应用于各种图像编辑场景,例如风格迁移、图像修复、对象替换等。通过GRAG,用户可以更精确地控制编辑强度,生成更符合需求的图像。该方法还可用于图像生成、图像增强等领域,具有广泛的应用前景和实际价值。未来,可以探索将GRAG与其他图像编辑技术相结合,进一步提升编辑效果和用户体验。
📄 摘要(原文)
Recently, image editing based on Diffusion-in-Transformer models has undergone rapid development. However, existing editing methods often lack effective control over the degree of editing, limiting their ability to achieve more customized results. To address this limitation, we investigate the MM-Attention mechanism within the DiT model and observe that the Query and Key tokens share a bias vector that is only layer-dependent. We interpret this bias as representing the model's inherent editing behavior, while the delta between each token and its corresponding bias encodes the content-specific editing signals. Based on this insight, we propose Group Relative Attention Guidance, a simple yet effective method that reweights the delta values of different tokens to modulate the focus of the model on the input image relative to the editing instruction, enabling continuous and fine-grained control over editing intensity without any tuning. Extensive experiments conducted on existing image editing frameworks demonstrate that GRAG can be integrated with as few as four lines of code, consistently enhancing editing quality. Moreover, compared to the commonly used Classifier-Free Guidance, GRAG achieves smoother and more precise control over the degree of editing. Our code will be released at https://github.com/little-misfit/GRAG-Image-Editing.