OSWorld-MCP: Benchmarking MCP Tool Invocation In Computer-Use Agents
作者: Hongrui Jia, Jitong Liao, Xi Zhang, Haiyang Xu, Tianbao Xie, Chaoya Jiang, Ming Yan, Si Liu, Wei Ye, Fei Huang
分类: cs.CV
发布日期: 2025-10-28 (更新: 2025-11-11)
💡 一句话要点
OSWorld-MCP:用于评估计算机使用Agent中MCP工具调用能力的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算机使用Agent 工具调用 多模态Agent 基准测试 模型上下文协议
📋 核心要点
- 现有Agent评估侧重GUI交互,忽略了MCP等工具调用能力,导致评估不全面。
- 提出OSWorld-MCP基准,包含自动化生成的和精选的工具,用于综合评估Agent的工具调用、GUI操作和决策能力。
- 实验表明,MCP工具能提升任务成功率,但现有Agent工具调用率仍较低,表明基准具有挑战性。
📝 摘要(中文)
随着决策和推理能力的进步,多模态Agent在计算机应用场景中展现出强大的潜力。过去的评估主要集中在GUI交互技能上,而工具调用能力,例如由模型上下文协议(MCP)启用的能力,在很大程度上被忽视了。将集成了工具调用能力的Agent与仅在GUI交互上评估的Agent进行比较,本质上是不公平的。我们提出了OSWorld-MCP,这是第一个全面且公平的基准,用于评估计算机使用Agent在真实环境中的工具调用、GUI操作和决策能力。我们设计了一种新颖的自动化代码生成流程来创建工具,并将它们与现有工具中的精选组合相结合。严格的手动验证产生了158个高质量的工具(涵盖7个常见的应用程序),每个工具都经过了正确的功能、实际适用性和通用性的验证。对最先进的多模态Agent在OSWorld-MCP上的广泛评估表明,MCP工具通常可以提高任务成功率(例如,OpenAI o3在15步时从8.3%提高到20.4%,Claude 4 Sonnet在50步时从40.1%提高到43.3%),这突显了评估工具调用能力的重要性。但是,即使是最强大的模型也具有相对较低的工具调用率,仅为36.3%,这表明仍有改进的空间,并突出了基准的挑战性。通过明确衡量MCP工具的使用技能,OSWorld-MCP加深了对多模态Agent的理解,并为评估复杂、工具辅助环境中的性能设定了新标准。我们的代码、环境和数据可在https://osworld-mcp.github.io公开获得。
🔬 方法详解
问题定义:现有计算机使用Agent的评估主要集中在GUI交互能力上,忽略了工具调用能力(如MCP工具)。这导致对Agent在实际复杂环境中的能力的评估不全面,并且无法公平地比较不同Agent的性能。现有方法缺乏一个综合性的基准来评估Agent的工具调用、GUI操作和决策能力。
核心思路:论文的核心思路是构建一个包含高质量工具的综合性基准OSWorld-MCP,用于全面评估Agent的工具调用能力。通过自动化代码生成和人工验证相结合的方式,创建了一系列功能正确、实用且通用的工具。这样可以更公平地评估Agent在真实环境中的表现,并促进Agent在工具调用方面的进一步发展。
技术框架:OSWorld-MCP的整体框架包括以下几个主要部分:1) 自动化代码生成流程:用于生成新的工具。2) 工具精选:从现有工具中选择合适的工具。3) 人工验证:确保工具的功能正确、实用且通用。4) 评估环境:提供一个真实的计算机使用环境,用于评估Agent的性能。5) 评估指标:用于衡量Agent在工具调用、GUI操作和决策方面的能力。
关键创新:该论文的关键创新在于提出了OSWorld-MCP,这是第一个全面且公平的基准,用于评估计算机使用Agent的工具调用能力。此外,论文还设计了一种新颖的自动化代码生成流程,可以高效地创建高质量的工具。通过结合自动化生成和人工验证,确保了工具的质量和多样性。
关键设计:在工具生成方面,论文设计了自动化代码生成流程,具体细节未知。在工具验证方面,采用了严格的人工验证流程,确保工具的功能正确、实用且通用。在评估指标方面,论文设计了多种指标来衡量Agent在工具调用、GUI操作和决策方面的能力,具体指标未知。
🖼️ 关键图片
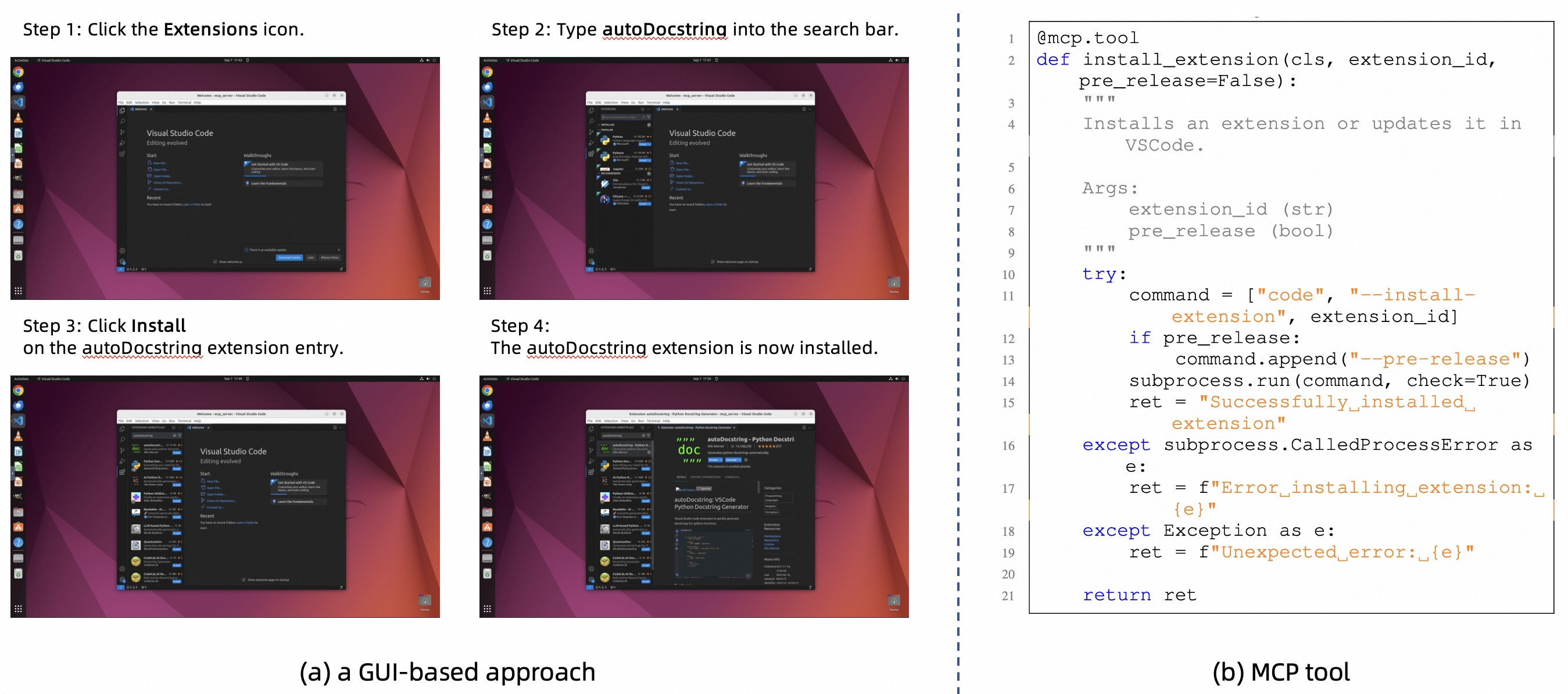
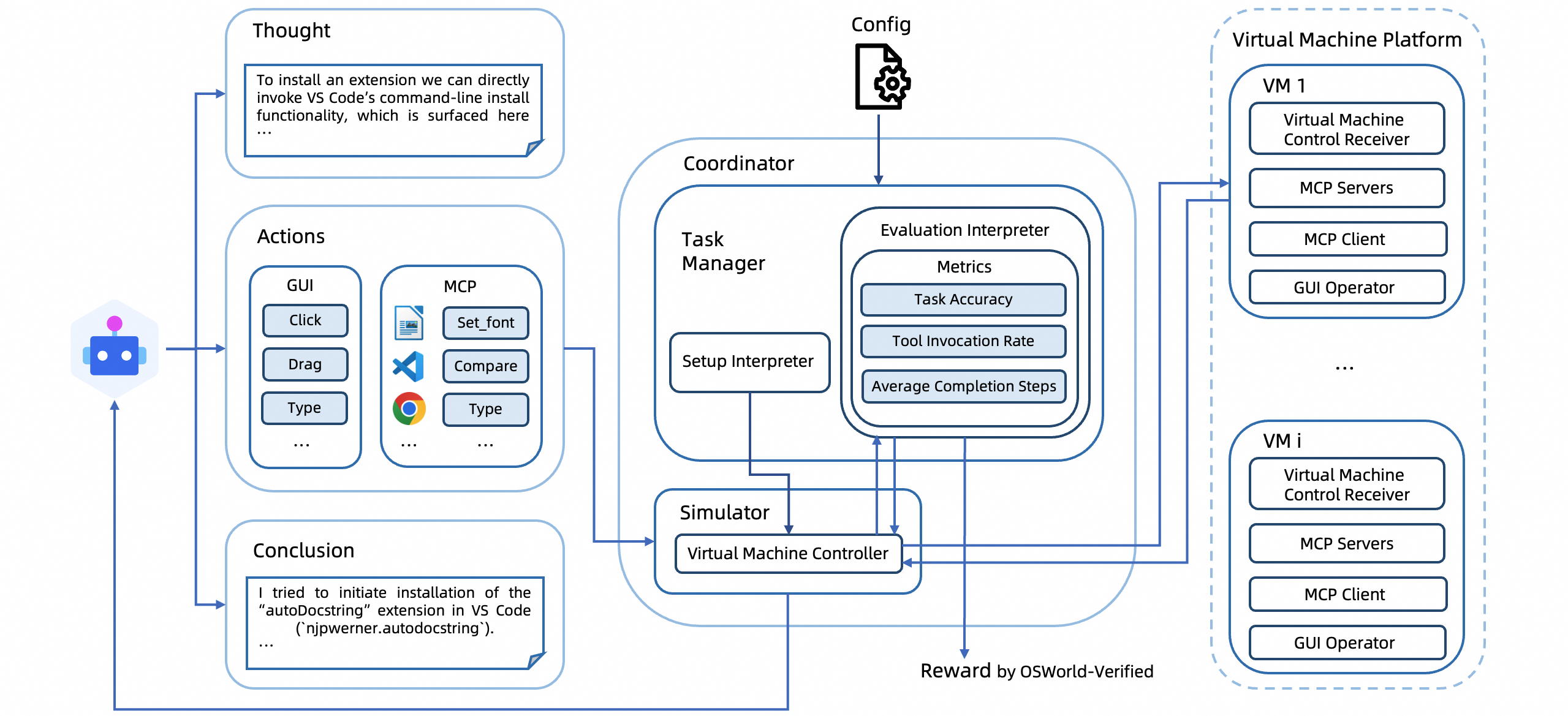
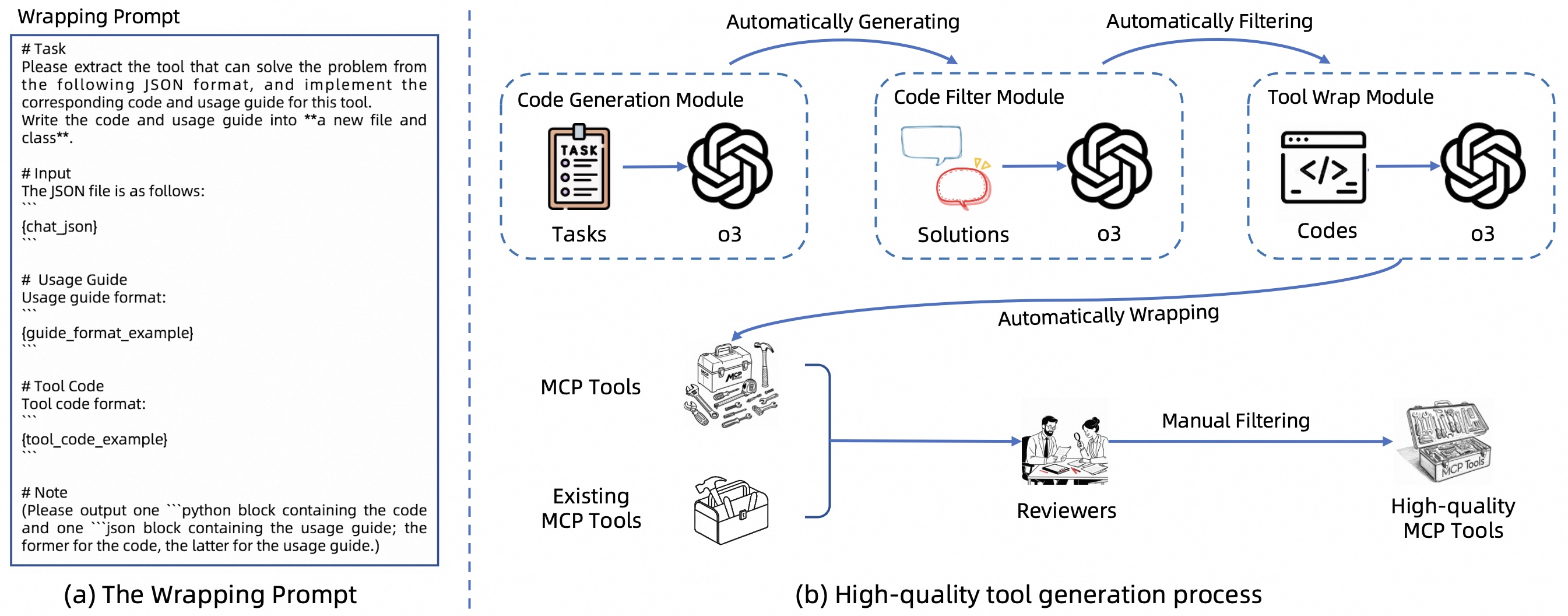
📊 实验亮点
在OSWorld-MCP上的实验表明,MCP工具可以显著提高Agent的任务成功率。例如,OpenAI o3在15步时,任务成功率从8.3%提高到20.4%;Claude 4 Sonnet在50步时,任务成功率从40.1%提高到43.3%。然而,即使是最强大的模型,工具调用率也仅为36.3%,表明仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于开发更智能、更高效的计算机使用Agent,例如智能助手、自动化测试工具等。这些Agent可以帮助用户更轻松地完成各种计算机任务,提高工作效率。此外,该基准还可以促进Agent在工具调用方面的研究,推动Agent技术的发展。
📄 摘要(原文)
With advances in decision-making and reasoning capabilities, multimodal agents show strong potential in computer application scenarios. Past evaluations have mainly assessed GUI interaction skills, while tool invocation abilities, such as those enabled by the Model Context Protocol (MCP), have been largely overlooked. Comparing agents with integrated tool invocation to those evaluated only on GUI interaction is inherently unfair. We present OSWorld-MCP, the first comprehensive and fair benchmark for assessing computer-use agents' tool invocation, GUI operation, and decision-making abilities in a real-world environment. We design a novel automated code-generation pipeline to create tools and combine them with a curated selection from existing tools. Rigorous manual validation yields 158 high-quality tools (covering 7 common applications), each verified for correct functionality, practical applicability, and versatility. Extensive evaluations of state-of-the-art multimodal agents on OSWorld-MCP show that MCP tools generally improve task success rates (e.g., from 8.3% to 20.4% for OpenAI o3 at 15 steps, from 40.1% to 43.3% for Claude 4 Sonnet at 50 steps), underscoring the importance of assessing tool invocation capabilities. However, even the strongest models have relatively low tool invocation rates, Only 36.3%, indicating room for improvement and highlighting the benchmark's challenge. By explicitly measuring MCP tool usage skills, OSWorld-MCP deepens understanding of multimodal agents and sets a new standard for evaluating performance in complex, tool-assisted environments. Our code, environment, and data are publicly available at https://osworld-mcp.github.io.